R에서 적합성 결여 테스트를 수행하는 방법(단계별)
적합성 결여 테스트는 전체 회귀 모델이 모델의 축소 버전보다 데이터 세트에 훨씬 더 나은 적합성을 제공하는지 여부를 결정하는 데 사용됩니다.
예를 들어, 특정 대학의 학생들의 시험 점수를 예측하기 위해 공부한 시간을 사용한다고 가정해 보겠습니다. 다음 두 가지 회귀 모델을 적용하기로 결정할 수 있습니다.
전체 모델: 점수 = β 0 + B 1 (시간) + B 2 (시간) 2
축소 모델: 점수 = β 0 + B 1 (시간)
다음 단계별 예에서는 R에서 적합성 부족 테스트를 수행하여 전체 모델이 축소된 모델보다 훨씬 더 나은 적합성을 제공하는지 확인하는 방법을 보여줍니다.
1단계: 데이터세트 생성 및 시각화
먼저 다음 코드를 사용하여 학생 50명의 공부 시간과 획득한 시험 점수가 포함된 데이터 세트를 만듭니다.
#make this example reproducible set. seeds (1) #create dataset df <- data. frame (hours = runif (50, 5, 15), score=50) df$score = df$score + df$hours^3/150 + df$hours* runif (50, 1, 2) #view first six rows of data head(df) hours score 1 7.655087 64.30191 2 8.721239 70.65430 3 10.728534 73.66114 4 14.082078 86.14630 5 7.016819 59.81595 6 13.983897 83.60510
다음으로, 시간과 점수 사이의 관계를 시각화하기 위해 산점도를 만듭니다.
#load ggplot2 visualization package library (ggplot2) #create scatterplot ggplot(df, aes (x=hours, y=score)) + geom_point()
2단계: 서로 다른 두 모델을 데이터 세트에 맞추기
다음으로 데이터 세트에 두 가지 다른 회귀 모델을 적용하겠습니다.
#fit full model full <- lm(score ~ poly (hours,2), data=df) #fit reduced model reduced <- lm(score ~ hours, data=df)
3단계: 적합성 부족 테스트 수행
다음으로 anova() 명령을 사용하여 두 모델 간의 적합성 부족 테스트를 수행합니다.
#lack of fit test
anova(full, reduced)
Analysis of Variance Table
Model 1: score ~ poly(hours, 2)
Model 2: score ~ hours
Res.Df RSS Df Sum of Sq F Pr(>F)
1 47 368.48
2 48 451.22 -1 -82.744 10.554 0.002144 **
---
Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
F 검정 통계량은 10.554 이고 해당 p-값은 0.002144 입니다. 이 p-값이 0.05보다 작기 때문에 검정의 귀무 가설을 기각하고 전체 모델이 축소 모델보다 통계적으로 유의하게 더 나은 적합성을 제공한다는 결론을 내릴 수 있습니다.
4단계: 최종 모델 시각화
마지막으로 원본 데이터 세트에 대해 최종 모델(전체 모델)을 시각화할 수 있습니다.
ggplot(df, aes (x=hours, y=score)) +
geom_point() +
stat_smooth(method=' lm ', formula = y ~ poly (x,2), size = 1) +
xlab(' Hours Studied ') +
ylab(' Score ')
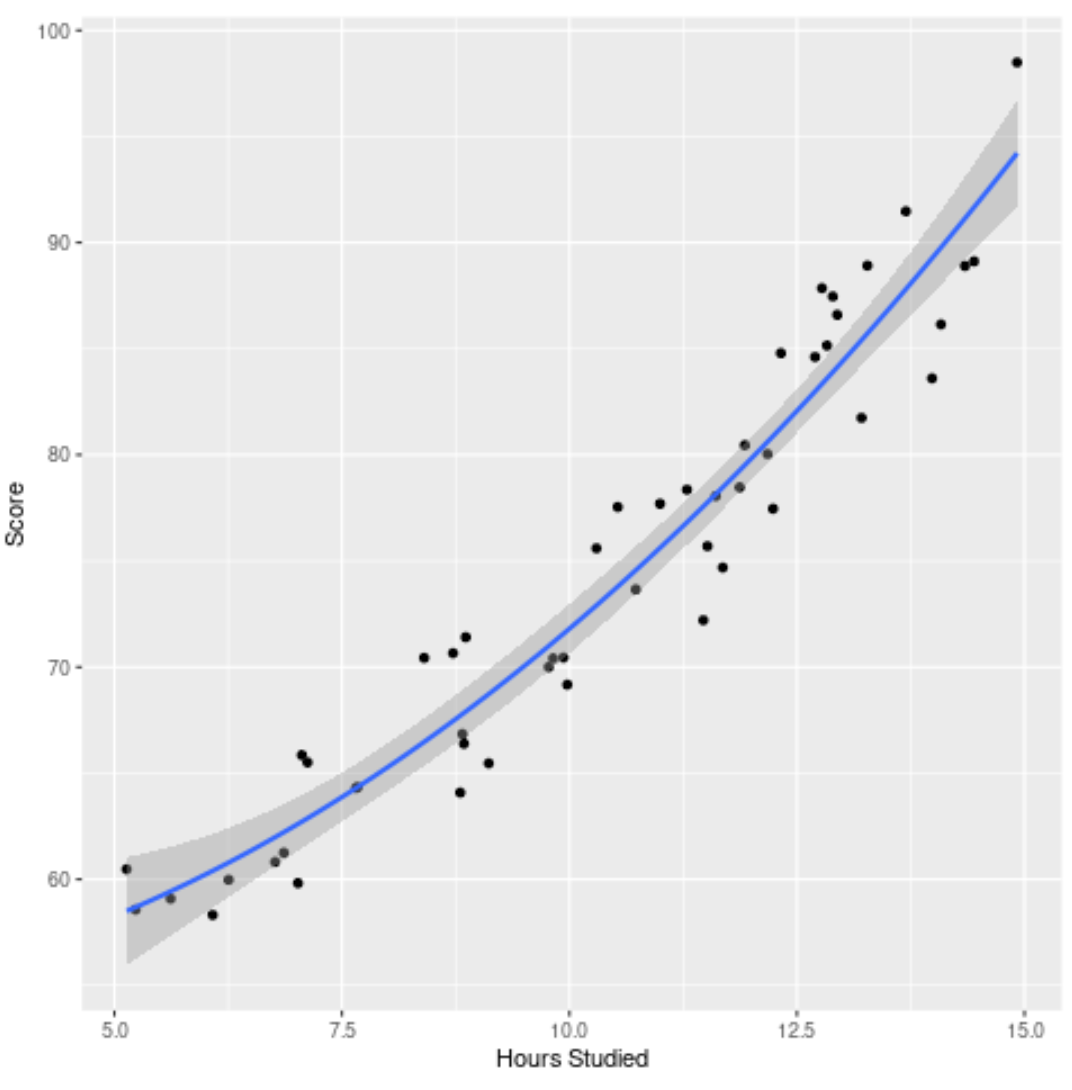
모델 곡선이 데이터와 매우 잘 맞는 것을 볼 수 있습니다.
추가 리소스
R에서 단순 선형 회귀를 수행하는 방법
R에서 다중 선형 회귀를 수행하는 방법
R에서 다항식 회귀를 수행하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기