동일하지 않은 표본 크기로 t-검정을 수행하는 방법
통계를 공부할 때 학생들이 자주 묻는 질문은 다음과 같습니다.
각 그룹의 표본 크기가 동일하지 않은 경우 t-검정을 수행할 수 있습니까?
짧은 대답:
예, 표본 크기가 동일하지 않은 경우 t-검정을 수행할 수 있습니다. 동일한 표본 크기는 t-검정에서 가정된 가정 중 하나가 아닙니다.
실제 문제는 두 표본이 t-검정에서 가정한 가정 중 하나 인 등분산을 갖지 않을 때 발생합니다.
이 경우 등분산을 가정하지 않는 Welch의 t-검정을 대신 사용하는 것이 좋습니다.
다음 예에서는 분산이 동일할 때와 동일하지 않을 때 동일하지 않은 표본 크기를 사용하여 T 테스트를 수행하는 방법을 보여줍니다.
예 1: 동일하지 않은 표본 크기 및 등분산
학생들이 특정 시험에서 더 나은 성적을 낼 수 있도록 돕기 위해 고안된 두 가지 프로그램을 운영한다고 가정해 보겠습니다.
결과는 다음과 같습니다:
프로그램 1:
- n (샘플 크기): 500
- x (샘플 평균): 80
- s (표본 표준편차): 5
프로그램 2:
- n (샘플 크기): 20
- x (샘플 평균): 85
- s (표본 표준편차): 5
다음 코드는 각 프로그램의 시험 점수 분포를 시각화하기 위해 R에서 상자 그림을 만드는 방법을 보여줍니다.
#make this example reproducible set. seeds (1) #create vectors to hold exam scores program1 <- rnorm(500, mean=80, sd=5) program2 <- rnorm(20, mean=85, sd=5) #create boxplots to visualize distribution of exam scores boxplot(program1, program2, names=c(" Program 1 "," Program 2 "))
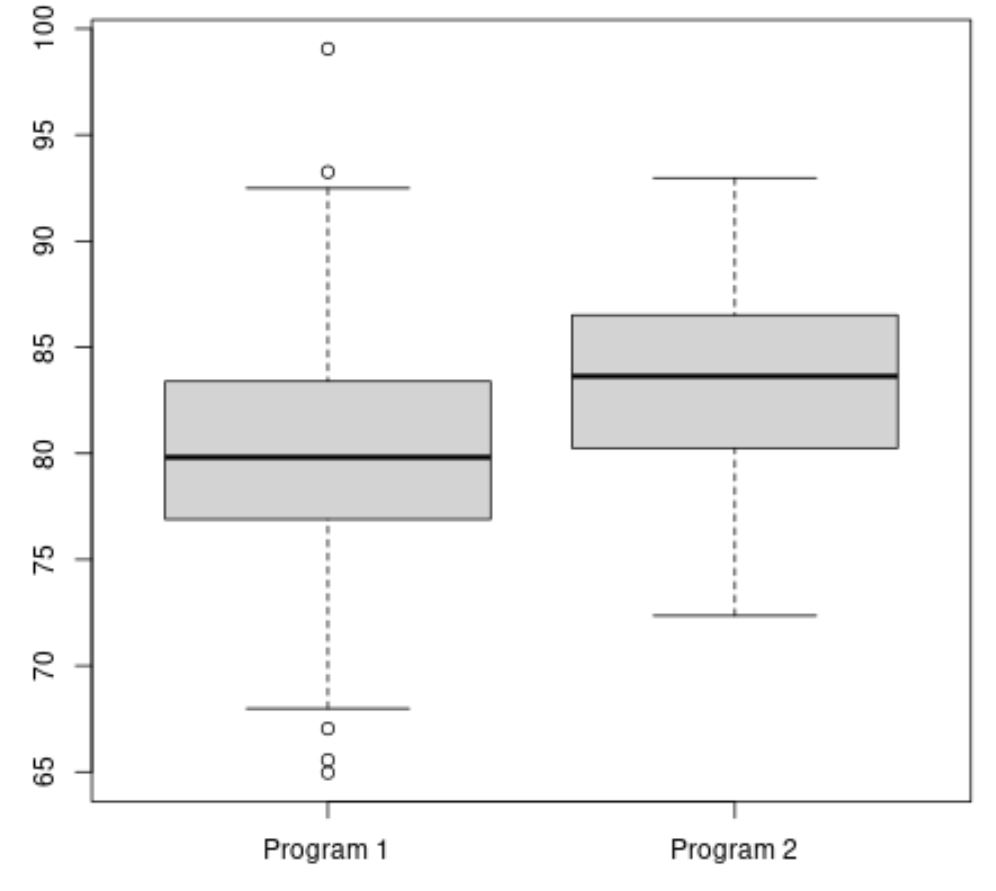
프로그램 2의 평균 시험 점수는 더 높은 것으로 보이지만 두 프로그램 간의 시험 점수 차이는 거의 동일합니다.
다음 코드는 Welch의 t-검정을 사용하여 독립 표본 t-검정을 수행하는 방법을 보여줍니다.
#perform independent samples t-test t. test (program1, program2, var. equal = TRUE ) Two Sample t-test data: program1 and program2 t = -3.3348, df = 518, p-value = 0.0009148 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -6.111504 -1.580245 sample estimates: mean of x mean of y 80.11322 83.95910 #perform Welch's two sample t-test t. test (program1, program2, var. equal = FALSE ) Welch Two Sample t-test data: program1 and program2 t = -3.3735, df = 20.589, p-value = 0.00293 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -6.219551 -1.472199 sample estimates: mean of x mean of y 80.11322 83.95910
독립 표본 t-검정은 p-값 0.0009 를 반환하고 Welch의 t-검정은 p-값 0.0029 를 반환합니다.
각 테스트의 p-값이 0.05보다 작기 때문에 각 테스트에서 귀무 가설을 기각하고 두 프로그램 간의 평균 시험 점수에 통계적으로 유의미한 차이가 있다는 결론을 내립니다.
표본 크기가 동일하지 않더라도 독립 표본 t-검정과 Welch의 t-검정은 두 표본의 분산이 동일하므로 둘 다 비슷한 결과를 반환합니다.
예 2: 동일하지 않은 표본 크기 및 동일하지 않은 분산
학생들이 특정 시험에서 더 나은 성적을 낼 수 있도록 돕기 위해 고안된 두 가지 프로그램을 운영한다고 가정해 보겠습니다.
결과는 다음과 같습니다:
프로그램 1:
- n (샘플 크기): 500
- x (샘플 평균): 80
- s (표본 표준편차): 25
프로그램 2:
- n (샘플 크기): 20
- x (샘플 평균): 85
- s (표본 표준편차): 5
다음 코드는 각 프로그램의 시험 점수 분포를 시각화하기 위해 R에서 상자 그림을 만드는 방법을 보여줍니다.
#make this example reproducible set. seeds (1) #create vectors to hold exam scores program1 <- rnorm(500, mean=80, sd=25) program2 <- rnorm(20, mean=85, sd=5) #create boxplots to visualize distribution of exam scores boxplot(program1, program2, names=c(" Program 1 "," Program 2 "))
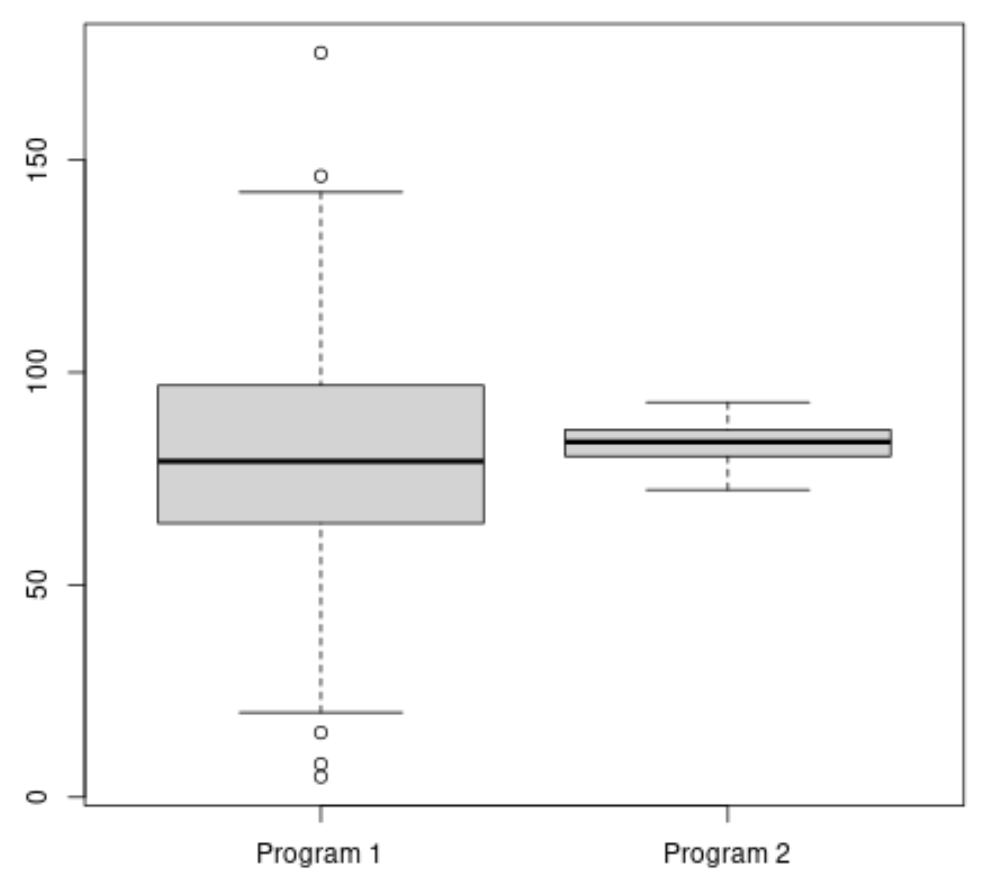
프로그램 2의 평균 시험 점수는 더 높은 것으로 보이지만 프로그램 1의 시험 점수 분산은 프로그램 2의 것보다 훨씬 높습니다.
다음 코드는 Welch의 t-검정을 사용하여 독립 표본 t-검정을 수행하는 방법을 보여줍니다.
#perform independent samples t-test t. test (program1, program2, var. equal = TRUE ) Two Sample t-test data: program1 and program2 t = -0.5988, df = 518, p-value = 0.5496 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -14.52474 7.73875 sample estimates: mean of x mean of y 80.5661 83.9591 #perform Welch's two sample t-test t. test (program1, program2, var. equal = FALSE ) Welch Two Sample t-test data: program1 and program2 t = -2.1338, df = 74.934, p-value = 0.03613 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -6.560690 -0.225296 sample estimates: mean of x mean of y 80.5661 83.9591
독립 표본 t-검정은 p-값 0.5496 을 반환하고 Welch의 t-검정은 p-값 0.0361 을 반환합니다.
독립표본 t-검정은 평균 시험 점수의 차이를 탐지할 수 없지만 Welch의 t-검정은 통계적으로 유의한 차이를 탐지할 수 있습니다.
두 표본의 분산이 동일하지 않기 때문에 Welch의 t-검정만이 평균 시험 점수에서 통계적으로 유의미한 차이를 탐지할 수 있었습니다. 이 검정은 표본 간의 분산이 동일하다고 가정하지 않기 때문입니다 .
추가 리소스
다음 튜토리얼에서는 t-테스트에 대한 추가 정보를 제공합니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기