
Comment utiliser Pandas Get Dummies – pd.get_dummies
Souvent, en statistiques, les ensembles de données avec lesquels nous travaillons incluent des variables catégorielles .
Ce sont des variables qui prennent des noms ou des étiquettes. Les exemples comprennent:
- État civil (« marié », « célibataire », « divorcé »)
- Statut de fumeur (« fumeur », « non-fumeur »)
- Couleur des yeux (« bleu », « vert », « noisette »)
- Niveau d’études (par exemple « lycée », « licence », « maîtrise »)
Lors de l’ajustement d’algorithmes d’apprentissage automatique (comme la régression linéaire , la régression logistique , les forêts aléatoires , etc.), nous convertissons souvent les variables catégorielles en variables factices , qui sont des variables numériques utilisées pour représenter des données catégorielles.
Par exemple, supposons que nous ayons un ensemble de données contenant la variable catégorielle Gender . Pour utiliser cette variable comme prédicteur dans un modèle de régression, il faudrait d’abord la convertir en variable muette.
Pour créer cette variable muette, nous pouvons choisir l’une des valeurs (« Mâle ») pour représenter 0 et l’autre valeur (« Femme ») pour représenter 1 :
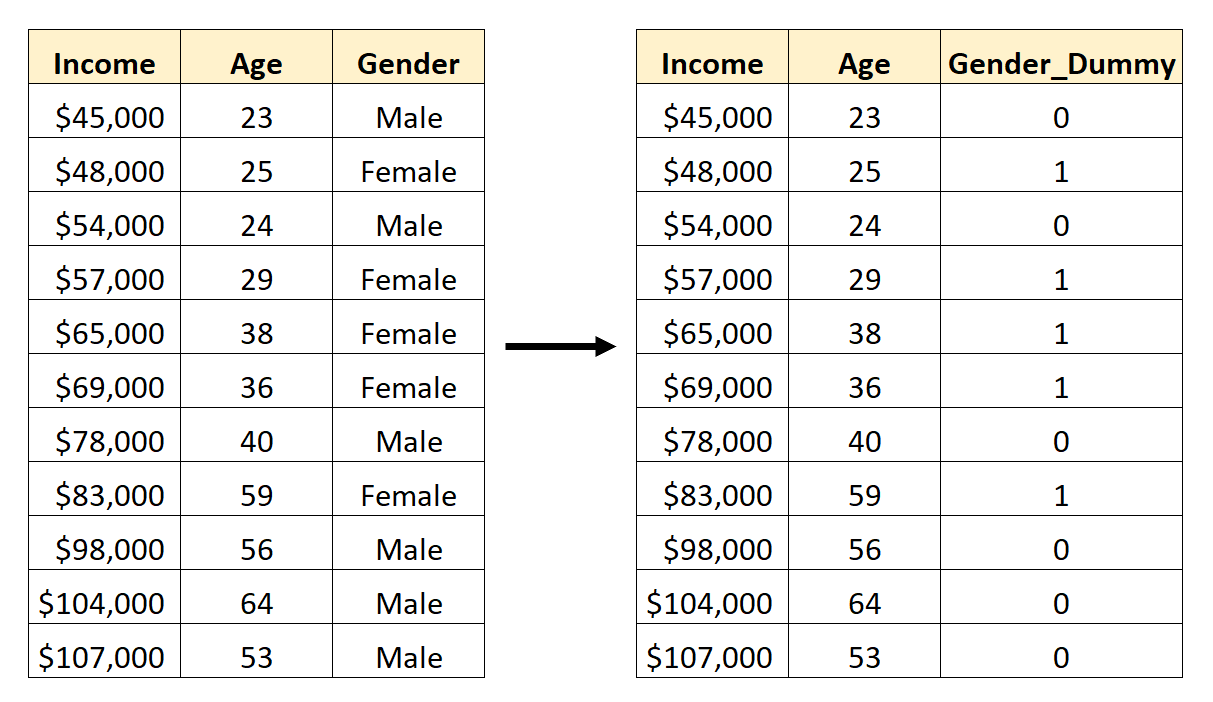
Comment créer des variables factices dans Pandas
Pour créer des variables factices pour une variable dans un DataFrame pandas, nous pouvons utiliser la fonction pandas.get_dummies() , qui utilise la syntaxe de base suivante :
pandas.get_dummies(data, prefix=Aucun, columns=Aucun, drop_first=False)
où:
- data : Le nom du pandas DataFrame
- prefix : une chaîne à ajouter au début de la nouvelle colonne de variable factice
- columns : Le nom de la ou des colonnes à convertir en variable factice
- drop_first : s’il faut ou non supprimer la première colonne de variable factice
Les exemples suivants montrent comment utiliser cette fonction dans la pratique.
Exemple 1 : créer une seule variable factice
Supposons que nous ayons le DataFrame pandas suivant :
import pandas as pd #create DataFrame df = pd.DataFrame({'income': [45, 48, 54, 57, 65, 69, 78], 'age': [23, 25, 24, 29, 38, 36, 40], 'gender': ['M', 'F', 'M', 'F', 'F', 'F', 'M']}) #view DataFrame df income age gender 0 45 23 M 1 48 25 F 2 54 24 M 3 57 29 F 4 65 38 F 5 69 36 F 6 78 40 M
Nous pouvons utiliser la fonction pd.get_dummies() pour transformer le genre en variable factice :
#convert gender to dummy variable pd.get_dummies(df, columns=['gender'], drop_first=True) income age gender_M 0 45 23 1 1 48 25 0 2 54 24 1 3 57 29 0 4 65 38 0 5 69 36 0 6 78 40 1
La colonne sexe est désormais une variable fictive où :
- Une valeur de 0 représente « Femme »
- Une valeur de 1 représente « Homme »
Exemple 2 : créer plusieurs variables factices
Supposons que nous ayons le DataFrame pandas suivant :
import pandas as pd #create DataFrame df = pd.DataFrame({'income': [45, 48, 54, 57, 65, 69, 78], 'age': [23, 25, 24, 29, 38, 36, 40], 'gender': ['M', 'F', 'M', 'F', 'F', 'F', 'M'], 'college': ['Y', 'N', 'N', 'N', 'Y', 'Y', 'Y']}) #view DataFrame df income age gender college 0 45 23 M Y 1 48 25 F N 2 54 24 M N 3 57 29 F N 4 65 38 F Y 5 69 36 F Y 6 78 40 M Y
Nous pouvons utiliser la fonction pd.get_dummies() pour convertir le sexe et l’université en variables factices :
#convert gender to dummy variable pd.get_dummies(df, columns=['gender', 'college'], drop_first=True) income age gender_M college_Y 0 45 23 1 1 1 48 25 0 0 2 54 24 1 0 3 57 29 0 0 4 65 38 0 1 5 69 36 0 1 6 78 40 1 1
La colonne sexe est désormais une variable fictive où :
- Une valeur de 0 représente « Femme »
- Une valeur de 1 représente « Homme »
Et la colonne collège est désormais une variable muette où :
- Une valeur de 0 représente « Non » université
- Une valeur de 1 représente « Oui » au collège
Ressources additionnelles
Comment utiliser des variables factices dans l’analyse de régression
Qu’est-ce que le piège variable factice ?
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus