
Mesures de forme
Cet article explique quelles sont les mesures de forme. Vous découvrirez donc à quoi servent les mesures de forme, comment les mesures de forme sont interprétées et comment ces types de métriques statistiques sont calculés.
Que sont les mesures de forme ?
En statistique, les mesures de forme sont des indicateurs qui permettent de décrire une distribution de probabilité en fonction de sa forme. Autrement dit, les mesures de forme sont utilisées pour déterminer à quoi ressemble une distribution sans qu’il soit nécessaire de la représenter graphiquement.
Il existe deux types de mesures de forme : l’asymétrie et l’aplatissement. L’asymétrie indique le degré de symétrie d’une distribution, tandis que l’aplatissement indique le degré de concentration d’une distribution autour de sa moyenne.
Quelles sont les mesures de forme ?
Compte tenu de la définition des mesures de forme, cette section montre quels sont ces types de paramètres statistiques.
En statistique, on distingue deux mesures de forme :
- Skewness : Indique si une distribution est symétrique ou asymétrique.
- Kurtosis – Indique si une distribution est raide ou plate.
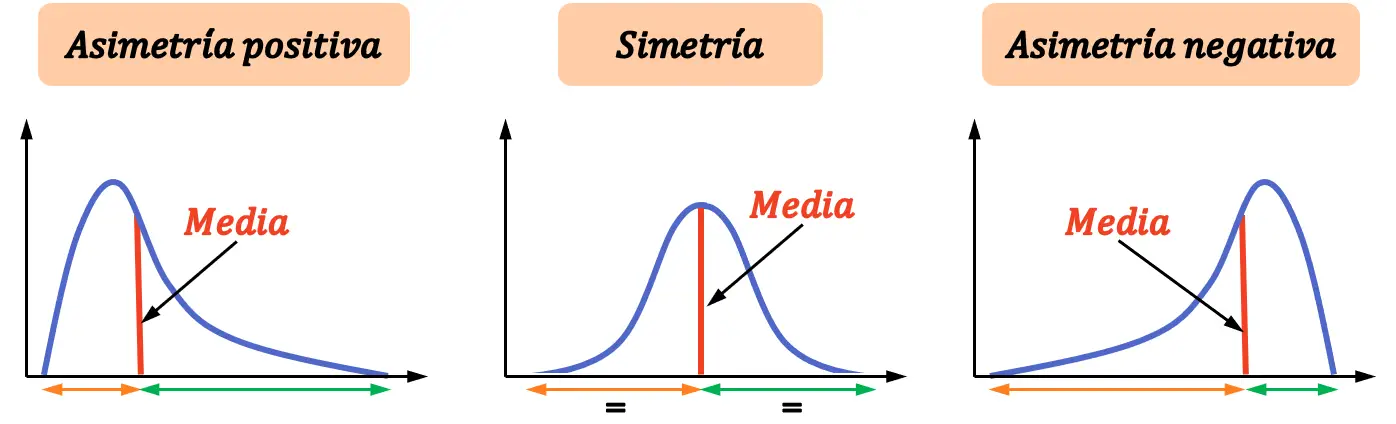
Asymétrie
Il existe trois types d’asymétrie :
- Asymétrie positive : La distribution a plus de valeurs différentes à droite de la moyenne qu’à sa gauche.
- Symétrie : La distribution a le même nombre de valeurs à gauche de la moyenne qu’à droite de la moyenne.
- Asymétrie négative : La distribution a plus de valeurs différentes à gauche de la moyenne qu’à sa droite.
coefficient d’asymétrie
Le coefficient d’asymétrie , ou indice d’asymétrie , est un coefficient statistique qui permet de déterminer l’asymétrie d’une distribution. Ainsi, en calculant le coefficient d’asymétrie, il est possible de connaître le type d’asymétrie de la distribution sans avoir à en faire une représentation graphique.
Bien qu’il existe différentes formules pour calculer le coefficient d’asymétrie, et nous les verrons toutes ci-dessous, quelle que soit la formule utilisée, l’interprétation du coefficient d’asymétrie se fait toujours comme suit :
- Si le coefficient d’asymétrie est positif, la distribution est positivement asymétrique .
- Si le coefficient d’asymétrie est égal à zéro, la distribution est symétrique .
- Si le coefficient d’asymétrie est négatif, la distribution est asymétrique négativement .
Coefficient d’asymétrie de Fisher
Le coefficient d’asymétrie de Fisher est égal au troisième moment autour de la moyenne divisé par l’écart type de l’échantillon. Par conséquent, la formule du coefficient d’asymétrie de Fisher est la suivante :

De manière équivalente, l’une ou l’autre des deux formules suivantes peut être utilisée pour calculer le coefficient de Fisher :

![\displaystyle\gamma_1=\frac{\operatorname{E}[X^3] - 3\mu\sigma^2 - \mu^3}{\sigma^3}](https://statorials.org/wp-content/ql-cache/quicklatex.com-92f7c8482d520258f24cc0166d898d1e_l3.png "Rendered by QuickLaTeX.com")
Où
 est l’espérance mathématique,
est l’espérance mathématique, la moyenne arithmétique,
la moyenne arithmétique, l’écart type et
l’écart type et le nombre total de données.
le nombre total de données.
En revanche, si les données sont regroupées vous pouvez utiliser la formule suivante :

Où dans ce cas
 C’est la marque de la classe et
C’est la marque de la classe et la fréquence absolue du cours.
la fréquence absolue du cours.
Coefficient d’asymétrie de Pearson
Le coefficient d’asymétrie de Pearson est égal à la différence entre la moyenne et le mode de l’échantillon divisée par son écart type (ou écart type). La formule du coefficient d’asymétrie de Pearson est donc la suivante :

Où
 est le coefficient de Pearson, la moyenne arithmétique,
est le coefficient de Pearson, la moyenne arithmétique, la mode et l’écart type.
la mode et l’écart type.
Gardez à l’esprit que le coefficient d’asymétrie de Pearson ne peut être calculé que s’il s’agit d’une distribution unimodale, c’est-à-dire s’il existe un seul mode dans les données.
Coefficient d’asymétrie de Bowley
Le coefficient d’asymétrie de Bowley est égal à la somme du troisième quartile plus le premier quartile moins deux fois la médiane divisée par la différence entre le troisième et le premier quartile. La formule de ce coefficient d’asymétrie est donc la suivante :

Où
 et
et sont respectivement les premier et troisième quartiles et
sont respectivement les premier et troisième quartiles et est la médiane de la distribution.
est la médiane de la distribution.
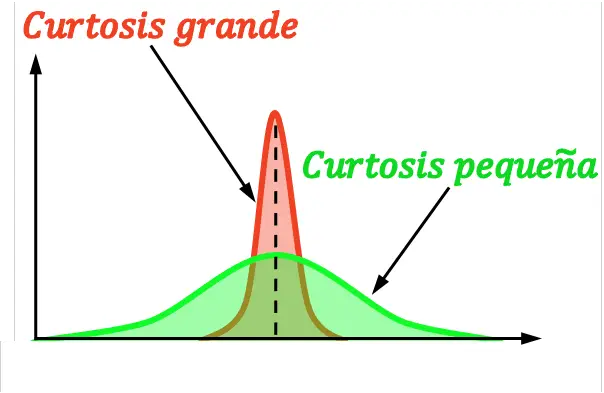
Aplatissement
L’aplatissement , également appelé pointage , indique le degré de concentration d’une distribution autour de sa moyenne. Autrement dit, l’aplatissement indique si une distribution est raide ou plate. Plus précisément, plus l’aplatissement d’une distribution est élevé, plus elle est raide (ou pointue).
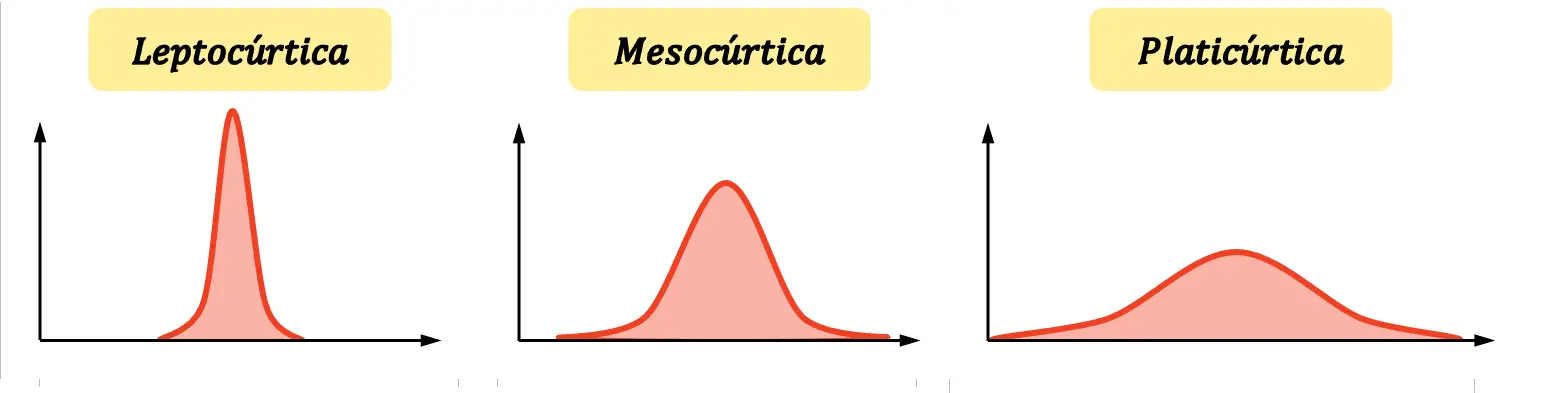
Il existe trois types d’aplatissement :
- Leptokurtique : la distribution est très pointue, c’est-à-dire que les données sont fortement concentrées autour de la moyenne. Plus précisément, les distributions leptokurtiques sont définies comme les distributions plus pointues que la distribution normale.
- Mésokurtique : L’aplatissement de la distribution est équivalent à l’aplatissement de la distribution normale. Elle n’est donc considérée ni pointue ni aplatie.
- Platicurtique : la distribution est très aplatie, c’est-à-dire que la concentration autour de la moyenne est faible. Formellement, les distributions platykurtiques sont définies comme les distributions plus aplaties que la distribution normale.
A noter que les différents types d’aplatissement sont définis en prenant comme référence l’aplatissement de la distribution normale.
Coefficient d’aplatissement
La formule du coefficient d’aplatissement est la suivante :

La formule du coefficient d’aplatissement pour les données regroupées dans des tableaux de fréquence :

Enfin, la formule du coefficient d’aplatissement pour les données regroupées en intervalles :

Où:
 est le coefficient d’aplatissement.
est le coefficient d’aplatissement.- est le nombre total de données.
- est la ième donnée de la série.
- est la moyenne arithmétique de la distribution.
- est l’écart type (ou écart typique) de la distribution.
- est la fréquence absolue du ième ensemble de données.
 est la marque de classe du ième groupe.
est la marque de classe du ième groupe.
Notez que dans toutes les formules de coefficient d’aplatissement, 3 est soustrait car il s’agit de la valeur d’aplatissement de la distribution normale. Ainsi, le calcul du coefficient d’aplatissement se fait en prenant comme référence l’aplatissement de la distribution normale. C’est pourquoi parfois dans les statistiques, on dit qu’un kurtosis excessif est calculé.
Une fois le coefficient d’aplatissement calculé, il faut l’interpréter comme suit pour identifier de quel type d’aplatissement il s’agit :
- Si le coefficient d’aplatissement est positif, cela signifie que la distribution est leptokurtique .
- Si le coefficient d’aplatissement est égal à zéro, cela signifie que la distribution est mésokurtique .
- Si le coefficient d’aplatissement est négatif, cela signifie que la distribution est platykurtique .
Autres types de mesures statistiques
Vous pourriez également être intéressé par l’une des mesures statistiques suivantes, cliquez sur l’une d’elles pour voir de quoi il s’agit et comment elles sont calculées.
à propos de l'auteur
Pr Amélia Rodriguez
En mettant l'accent sur l'apprentissage interactif et les applications pratiques, la professeure Amélia Rodriguez propose des tutoriels complets et des exemples concrets pour rendre les concepts de probabilité accessibles et pertinents pour la vie de ses étudiants. Lire plus