High-dimensional data ဆိုတာ ဘာလဲ။ (အဓိပ္ပါယ်နှင့် ဥပမာများ)
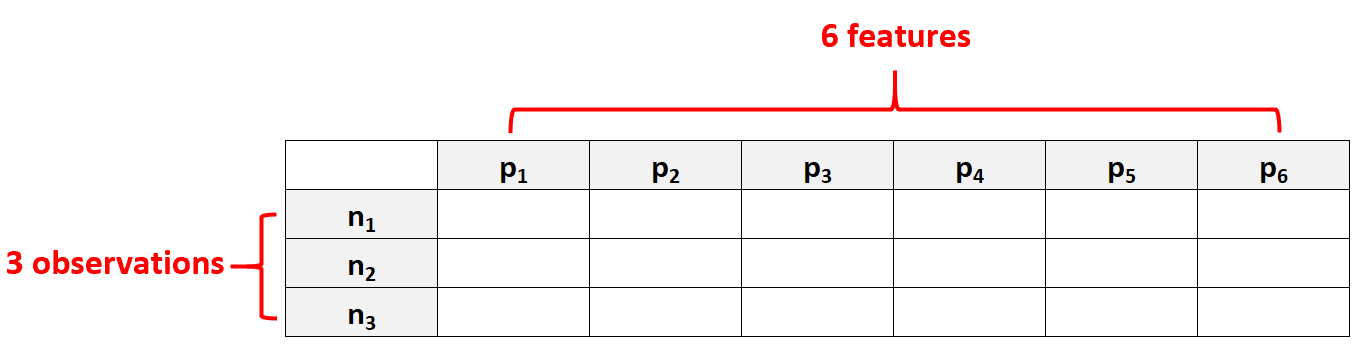
High-dimensional data ဆိုသည်မှာ p သည် စောင့်ကြည့်မှု အရေအတွက် N ထက်များသော အင်္ဂါရပ်များ p >> N ဖြင့် ရေးသားလေ့ရှိသော ဒေတာအစုံကို ရည်ညွှန်းသည်။
ဥပမာအားဖြင့်၊ p =6 အင်္ဂါရပ်များပါရှိသော ဒေတာအတွဲတစ်ခုနှင့် N =3 လေ့လာတွေ့ရှိချက်များသာ အင်္ဂါရပ်အရေအတွက်သည် စူးစမ်းမှုအရေအတွက်ထက် ပိုများနေသောကြောင့် အဘက်ဘက်မှ မြင့်မားသောဒေတာအဖြစ် သတ်မှတ်ခံရမည်ဖြစ်သည်။
လူတွေလုပ်လေ့ရှိတဲ့ အမှားတစ်ခုကတော့ “ အမြင့်ဘက်မြင်ဒေတာ” ဟာ အင်္ဂါရပ်များစွာနဲ့ ဒေတာအစုံကို ဆိုလိုပါတယ်။ သို့သော် ဤသည်မှာ မမှန်ပါ။ ဒေတာအတွဲတစ်ခုတွင် အင်္ဂါရပ်ပေါင်း 10,000 ပါဝင်နိုင်သော်လည်း ၎င်းတွင် စူးစမ်းလေ့လာမှု 100,000 ပါဝင်ပါက ၎င်းသည် မြင့်မားသောဘက်မြင်မှုမဟုတ်ပါ။
မှတ်ချက်- အမြင့်ဘက်မြင်ဒေတာနောက်ကွယ်ရှိ သင်္ချာဆိုင်ရာ အသေးစိတ်ဆွေးနွေးချက်တစ်ခုအတွက် ကိန်းဂဏန်းလေ့လာခြင်းဆိုင်ရာ ဒြပ်စင်များ၏ အခန်း 18 ကို ကိုးကားပါ။
မြင့်မားသောဒေတာသည် အဘယ်ကြောင့် ပြဿနာဖြစ်သနည်း။
ဒေတာအတွဲတစ်ခုရှိ အင်္ဂါရပ်အရေအတွက်သည် လေ့လာသုံးသပ်မှုအရေအတွက်ထက် ကျော်လွန်သောအခါ၊ ကျွန်ုပ်တို့သည် မည်သည့်အခါမျှ အဆုံးအဖြတ်ပေးသည့် အဖြေကို ရရှိမည်မဟုတ်ပါ။
တစ်နည်းဆိုရသော်၊ ခန့်မှန်းသူကိန်းရှင်များနှင့် တုံ့ပြန်မှုကိန်းရှင် ကြား ဆက်နွယ်မှုကို ဖော်ပြနိုင်သော မော်ဒယ်တစ်ခုကို ရှာတွေ့ရန် မဖြစ်နိုင်တော့ပေ။ အကြောင်းမှာ ကျွန်ုပ်တို့တွင် မော်ဒယ်ကိုလေ့ကျင့်ရန် လုံလောက်သော စူးစမ်းလေ့လာမှုများ မရှိသောကြောင့်ဖြစ်သည်။
အဘက်ဘက်မှ မြင့်မားသော အချက်အလက် နမူနာများ
အောက်ဖော်ပြပါ ဥပမာများသည် မတူညီသော ဒိုမိန်းများတွင် မြင့်မားသော အဘက်ဘက်မှ ဒေတာအတွဲများကို သရုပ်ဖော်သည်။
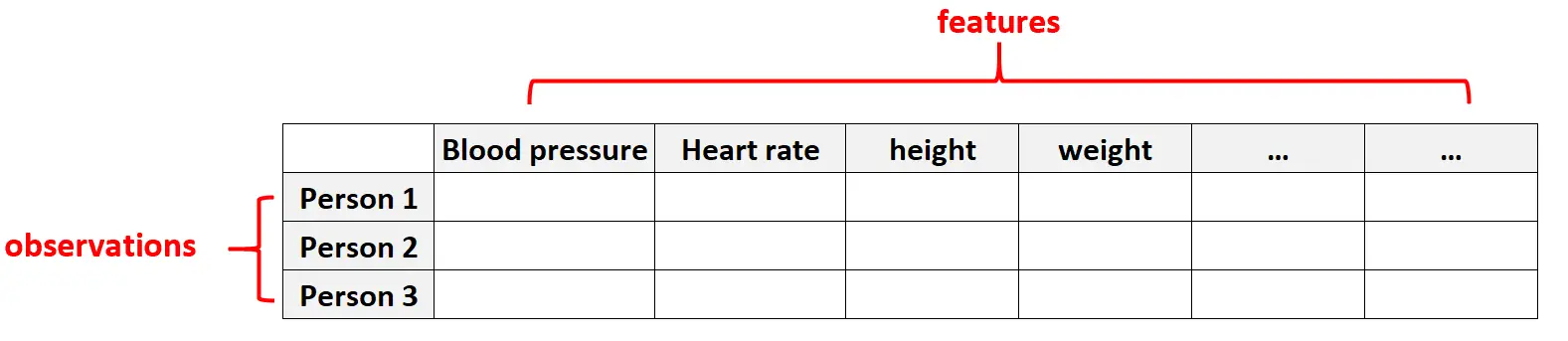
ဥပမာ 1- ကျန်းမာရေးဒေတာ
ပေးထားသောတစ်ဦးချင်းစီအတွက် အင်္ဂါရပ်အရေအတွက် ကြီးမားနိုင်သည် (ဆိုလိုသည်မှာ သွေးပေါင်ချိန်၊ နှလုံးခုန်နှုန်း၊ ခုခံအားစနစ်အခြေအနေ၊ ခွဲစိတ်မှုမှတ်တမ်း၊ အရပ်အမြင့်၊ ကိုယ်အလေးချိန်၊ ရှိပြီးသားအခြေအနေစသည်ဖြင့်) ကျန်းမာရေးစောင့်ရှောက်မှုဒေတာအတွဲများတွင် မြင့်မားသောဒေတာသည် အသုံးများပါသည်။
ဤဒေတာအတွဲများတွင်၊ အင်္ဂါရပ်များ အရေအတွက်သည် စူးစမ်းမှုအရေအတွက်ထက် ပိုများနေလေ့ရှိသည်။
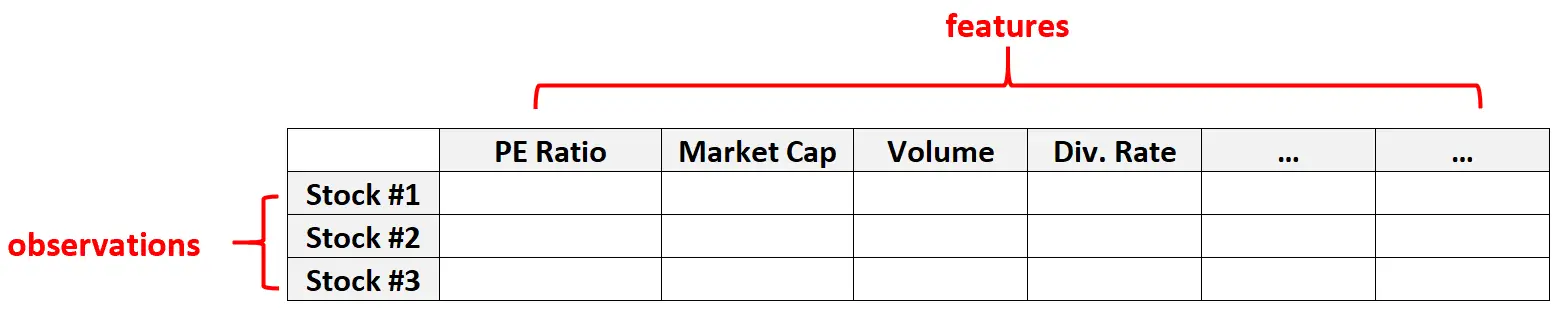
ဥပမာ 2- ဘဏ္ဍာရေးအချက်အလက်
ပေးထားသောစတော့ရှယ်ယာတစ်ခုအတွက်အင်္ဂါရပ်အရေအတွက်အတော်လေးကြီးမားနိုင်သည် (ဆိုလိုသည်မှာ PE အချိုး၊ စျေးကွက်အရင်းအနှီး၊ ကုန်သွယ်မှုပမာဏ၊ အမြတ်ဝေစုနှုန်းစသည်ဖြင့်) ငွေကြေးဆိုင်ရာဒေတာအတွဲများတွင်လည်း မြင့်မားသောဒေတာသည် အသုံးများပါသည်။
ဤဒေတာအတွဲအမျိုးအစားများတွင်၊ တစ်ခုချင်းလုပ်ဆောင်မှုအရေအတွက်ထက် များစွာကြီးမားသော entities အရေအတွက်သည် သာမာန်ဖြစ်သည်။
ဥပမာ 3- Genomics
မြင့်မားသော ကိန်းဂဏာန်းအချက်အလက်များသည် မျိုးရိုးဗီဇနယ်ပယ်တွင် တူညီပြီး ပေးထားသော လူတစ်ဦးချင်းစီ၏ မျိုးရိုးဗီဇလက္ခဏာများ အရေအတွက်သည် ကြီးမားနိုင်သည်။

ကြီးမားသောဒေတာကိုကိုင်တွယ်နည်း
High-dimensional data ကို လုပ်ဆောင်ရန် ဘုံနည်းလမ်း နှစ်ခု ရှိပါသည်။
1. အနည်းငယ်သောအင်္ဂါရပ်များပါ ၀ င်ရန်ရွေးချယ်ပါ။
အဘက်ဘက်မှ မြင့်မားသောဒေတာကို ရှောင်ရှားရန် အထင်ရှားဆုံးနည်းလမ်းမှာ ဒေတာအတွဲတွင် အင်္ဂါရပ်အနည်းငယ်သာ ထည့်သွင်းရန်ဖြစ်သည်။
ဒေတာအတွဲတစ်ခုမှ မည်သည့်အင်္ဂါရပ်များကို ဖယ်ရှားရမည်ကို ဆုံးဖြတ်ရန် နည်းလမ်းများစွာရှိပြီး၊ အပါအဝင်၊
- ပျောက်ဆုံးနေသောတန်ဖိုးများစွာရှိသည့် အင်္ဂါရပ်များကို ဖယ်ရှားပါ- ဒေတာအတွဲတစ်ခုတွင် ပေးထားသောကော်လံတစ်ခုတွင် ပျောက်ဆုံးနေသောတန်ဖိုးများစွာရှိနေပါက၊ အချက်အလက်များစွာမဆုံးရှုံးဘဲ ၎င်းကို လုံးလုံးဖယ်ရှားနိုင်မည်ဖြစ်သည်။
- ကွဲလွဲမှုနည်းသောအင်္ဂါရပ်များကို ဖယ်ရှားပါ- ဒေတာအတွဲတစ်ခုတွင် ပေးထားသောကော်လံတစ်ခုတွင် အနည်းငယ်သာပြောင်းလဲသည့်တန်ဖိုးများရှိပါက၊ ၎င်းသည် အခြားအင်္ဂါရပ်များထက် တုံ့ပြန်မှုကိန်းရှင်တစ်ခုအကြောင်း များစွာအသုံးဝင်သောအချက်အလက်များကို ပေးစွမ်းနိုင်ဖွယ်မရှိသောကြောင့် ၎င်းကိုဖယ်ရှားနိုင်သည်။
- တုံ့ပြန်မှုကိန်းရှင်နှင့် ဆက်နွယ်မှုနည်းသော အင်္ဂါရပ်များကို ဖယ်ရှားပါ- အချို့သောအင်္ဂါရပ်သည် သင်စိတ်ဝင်စားသည့် တုံ့ပြန်မှုကိန်းရှင်နှင့် အလွန်ဆက်စပ်မှုမရှိပါက၊ မော်ဒယ်တစ်ခုတွင် အသုံးဝင်သောအင်္ဂါရပ်ဖြစ်နိုင်ဖွယ်မရှိသောကြောင့် ၎င်းအား ဒေတာအတွဲမှ ဖယ်ရှားနိုင်မည်ဖြစ်သည်။
2. ပုံမှန်ပြုလုပ်ခြင်းနည်းလမ်းကို အသုံးပြုပါ။
ဒေတာအတွဲမှ အင်္ဂါရပ်များကို မဖယ်ရှားဘဲ မြင့်မားသောအဘက်ဘက်မှ ဒေတာကို ကိုင်တွယ်ရန် အခြားနည်းလမ်းမှာ ပုံမှန်ပြုလုပ်ခြင်းနည်းလမ်းကို အသုံးပြုခြင်းဖြစ်သည်-
- အဓိကအစိတ်အပိုင်းခွဲခြမ်းစိတ်ဖြာ
- အဓိက အစိတ်အပိုင်းများ ဆုတ်ယုတ်ခြင်း။
- ဆုတ်ယုတ်မှု အထွတ်အထိပ်
- Lasso ဆုတ်ယုတ်မှု
ဤနည်းပညာတစ်ခုစီသည် မြင့်မားသောဘက်မြင်ဒေတာကို ထိရောက်စွာလုပ်ဆောင်ရန်အတွက် အသုံးပြုနိုင်သည်။
ဤစာမျက်နှာတွင် စာရင်းအင်းဆိုင်ရာ စက်သင်ယူမှုသင်ခန်းစာအားလုံး၏ စာရင်းအပြည့်အစုံကို သင်တွေ့နိုင်သည်။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။