Log-likelihood values (ဥပမာများဖြင့်) အဓိပ္ပာယ်ဖွင့်ဆိုပုံ၊
ဆုတ်ယုတ်မှုပုံစံ၏ မှတ်တမ်းဖြစ်နိုင်ခြေတန်ဖိုး သည် မော်ဒယ်တစ်ခု၏ အံဝင်ခွင်ကျကောင်းမွန်မှုကို တိုင်းတာသည့်နည်းလမ်းဖြစ်သည်။ log-likelihood value ပိုများလေ၊ model သည် data set တစ်ခုနှင့် ပိုအဆင်ပြေလေဖြစ်သည်။
ပေးထားသောမော်ဒယ်တစ်ခုအတွက် မှတ်တမ်းဖြစ်နိုင်ခြေတန်ဖိုးသည် အနုတ်လက္ခဏာ infinity မှ positive infinity အထိရှိနိုင်ပါသည်။ ပေးထားသောမော်ဒယ်အတွက် အမှန်တကယ် မှတ်တမ်းဖြစ်နိုင်ခြေတန်ဖိုးသည် ယေဘုယျအားဖြင့် အဓိပ္ပါယ်မရှိသော်လည်း မော်ဒယ်နှစ်ခု သို့မဟုတ် ထို့ထက်ပိုသော မော်ဒယ်များကို နှိုင်းယှဉ်ရန်အတွက် အသုံးဝင်သည် ။
လက်တွေ့တွင်၊ ကျွန်ုပ်တို့သည် ဒေတာအတွဲတစ်ခုတွင် အကြိမ်ပေါင်းများစွာ ဆုတ်ယုတ်မှုပုံစံများကို မကြာခဏ ဖြည့်သွင်းပြီး ဒေတာနှင့် အကိုက်ညီဆုံး ဒေတာနှင့် အသင့်တော်ဆုံး မှတ်တမ်းဖြစ်နိုင်ခြေတန်ဖိုးအမြင့်ဆုံး မော်ဒယ်ကို ရွေးချယ်ပါ။
အောက်ဖော်ပြပါ ဥပမာသည် လက်တွေ့တွင် မတူညီသော ဆုတ်ယုတ်မှုပုံစံများအတွက် log-likelihood တန်ဖိုးများကို မည်သို့အဓိပ္ပာယ်ဖွင့်ဆိုသည်ကို ပြသထားသည်။
ဥပမာ- မှတ်တမ်းဖြစ်နိုင်ခြေတန်ဖိုးများကို စကားပြန်ဆိုခြင်း။
ကျွန်ုပ်တို့တွင် အိပ်ခန်းအရေအတွက်၊ ရေချိုးခန်းအရေအတွက်နှင့် ရပ်ကွက်တစ်ခုရှိ မတူညီသောအိမ် 20 ၏ အရောင်းစျေးနှုန်းများကို ပြသသည့် အောက်ပါဒေတာအစုံရှိသည်ဆိုကြပါစို့။
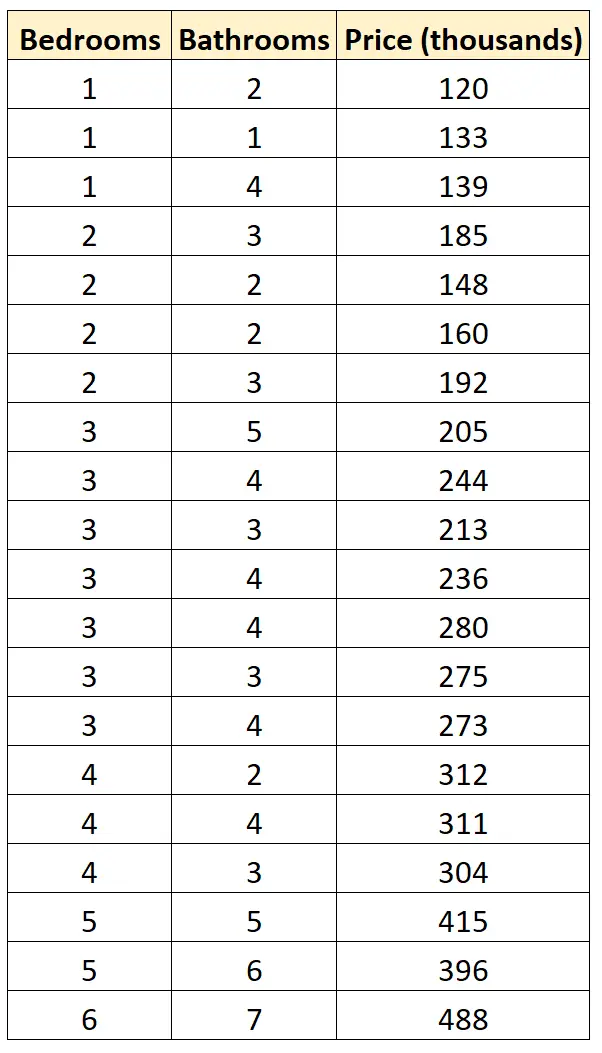
ကျွန်ုပ်တို့သည် အောက်ဖော်ပြပါ ဆုတ်ယုတ်မှုပုံစံနှစ်ခုကို အံဝင်ခွင်ကျဖြစ်စေပြီး မည်သည့်ဒေတာနှင့် အသင့်တော်ဆုံးဖြစ်စေမည်ကို ဆုံးဖြတ်လိုသည်ဆိုပါစို့။
မော်ဒယ် 1 : ဈေးနှုန်း = β 0 + β 1 (အခန်းအရေအတွက်)
မော်ဒယ် 2 စျေးနှုန်း = β 0 + β 1 (ရေချိုးခန်း အရေအတွက်)
အောက်ဖော်ပြပါ ကုဒ်သည် ဆုတ်ယုတ်မှုပုံစံတစ်ခုစီနှင့် အံကိုက်လုပ်နည်းကို ပြသပြီး မော်ဒယ်တစ်ခုစီ၏ မှတ်တမ်းဖြစ်နိုင်ခြေတန်ဖိုးကို R တွင် တွက်ချက်ပြသည်-
#define data df <- data. frame (beds=c(1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 5, 5, 6), baths=c(2, 1, 4, 3, 2, 2, 3, 5, 4, 3, 4, 4, 3, 4, 2, 4, 3, 5, 6, 7), price=c(120, 133, 139, 185, 148, 160, 192, 205, 244, 213, 236, 280, 275, 273, 312, 311, 304, 415, 396, 488)) #fitmodels model1 <- lm(price~beds, data=df) model2 <- lm(price~baths, data=df) #calculate log-likelihood value of each model logLik(model1) 'log Lik.' -91.04219 (df=3) logLik(model2) 'log Lik.' -111.7511 (df=3)
ပထမမော်ဒယ်တွင် မှတ်တမ်းဖြစ်နိုင်ခြေတန်ဖိုး ( -91.04 ) ရှိပြီး ဒုတိယမော်ဒယ် ( -111.75 ) ထက် ပိုမိုမြင့်မားသော မော်ဒယ်တွင် အဓိပ္ပါယ်မှာ ပထမမော်ဒယ်သည် ဒေတာနှင့် ပိုမိုကိုက်ညီမှုရှိသည်။
မှတ်တမ်းဖြစ်နိုင်ခြေတန်ဖိုးများကို အသုံးပြုခြင်းအတွက် ကြိုတင်ကာကွယ်မှုများ
မှတ်တမ်းဖြစ်နိုင်ခြေတန်ဖိုးများကို တွက်ချက်ရာတွင်၊ မော်ဒယ်တစ်ခုသို့ ထပ်လောင်းခန့်မှန်းသူကိန်းရှင်များကို ပေါင်းထည့်ခြင်းသည် ကိန်းဂဏန်းအချက်အလက်များအရ သိသာထင်ရှားခြင်းမရှိလျှင်ပင် မှတ်တမ်းဖြစ်နိုင်ခြေတန်ဖိုးများကို အမြဲတမ်းနီးပါးတိုးစေမည်ဖြစ်ကြောင်း မှတ်သားထားရန် အရေးကြီးပါသည်။
ဆိုလိုသည်မှာ မော်ဒယ်တစ်ခုစီတွင် ခန့်မှန်းသူကိန်းရှင်အရေအတွက် တူညီပါက regression model နှစ်ခုကြားတွင် log ဖြစ်နိုင်ခြေတန်ဖိုးများကိုသာ နှိုင်းယှဉ်သင့်သည်။
မော်ဒယ်များကို အမျိုးမျိုးသော ကိန်းဂဏန်းများကို ခန့်မှန်းနိုင်သော ကိန်းရှင်များနှင့် နှိုင်းယှဉ်ရန်၊ nested regression မော်ဒယ်နှစ်ခု၏ အံဝင်ခွင်ကျဖြစ်နိုင်ခြေကို နှိုင်းယှဉ်ရန် ဖြစ်နိုင်ခြေအချိုးစမ်းသပ်မှုကို လုပ်ဆောင်နိုင်သည်။
ထပ်လောင်းအရင်းအမြစ်များ
R တွင် linear မော်ဒယ်များနှင့်ကိုက်ညီရန် lm() function ကိုအသုံးပြုနည်း
R တွင်ဖြစ်နိုင်ခြေအချိုးစမ်းသပ်မှုပြုလုပ်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။