Pandas get dummies – pd.get_dummies ကိုအသုံးပြုနည်း
မကြာခဏဆိုသလို ကိန်းဂဏန်းစာရင်းဇယားများတွင် ကျွန်ုပ်တို့လုပ်ဆောင်သော ဒေတာအတွဲများတွင် အမျိုးအစားခွဲခြားနိုင်သော ကိန်းရှင်များ ပါဝင်သည်။
၎င်းတို့သည် အမည်များ သို့မဟုတ် အညွှန်းများယူသည့် ကိန်းရှင်များဖြစ်သည်။ ဥပမာများပါဝင်သည်-
- အိမ်ထောင်ရေးအခြေအနေ (“လက်ထပ်”၊ “လူပျို”၊ “ကွာရှင်း”)
- ဆေးလိပ်သောက်ခြင်းအခြေအနေ (“ ဆေးလိပ်သောက်သူ” ၊ “ ဆေးလိပ်မသောက်သူ” )
- မျက်လုံးအရောင် (“အပြာ”၊ “စိမ်း”၊ “အပြာရောင်”)
- ပညာရေးအဆင့် (ဥပမာ “ အထက်တန်းကျောင်း” ၊ “ ဘွဲ့” ၊ “ မဟာဘွဲ့” )
စက်သင်ယူမှုဆိုင်ရာ အယ်လဂိုရီသမ်များကို ချိန်ညှိခြင်း ( လိုင်းရိုးဆုတ်ယုတ်မှု ၊ ထောက်ပံ့ပို့ဆောင်ရေးဆုတ်ယုတ်မှု ကဲ့သို့၊ ကျပန်းသစ်တောများ စသည်ဖြင့်) ကို ချိန်ညှိသည့်အခါ၊ ကျွန်ုပ်တို့သည် ဒေတာအမျိုးအစား အလိုက် ကိန်းသေကိန်းရှင်များကို ကိုယ်စားပြုရန် အသုံးပြုသည့် ကိန်းဂဏာန်းကိန်းရှင်များဖြစ်သည့် categorical variables အဖြစ်သို့ ပြောင်းလဲလေ့ရှိပါသည်။
ဥပမာအားဖြင့်၊ ကျွန်ုပ်တို့တွင် အမျိုးအစားအလိုက် ပြောင်းလဲနိုင်သော လိင် အမျိုးအစား ပါ၀င်သည့် ဒေတာအတွဲတစ်ခုရှိသည်ဆိုပါစို့။ ဆုတ်ယုတ်မှုပုံစံတစ်ခုတွင် ဤကိန်းရှင်အား ခန့်မှန်းသူအဖြစ် အသုံးပြုရန်၊ ၎င်းကို dummy variable အဖြစ်သို့ ပြောင်းလဲရန် ဦးစွာ လိုအပ်မည်ဖြစ်သည်။
ဤအရုပ်ပြောင်းကိန်းကို ဖန်တီးရန်၊ ကျွန်ုပ်တို့သည် 0 ကိုကိုယ်စားပြုရန် တန်ဖိုးများထဲမှတစ်ခု (“ ယောကျာ်း” ) ကို ရွေးချယ်နိုင်ပြီး 1 ကိုကိုယ်စားပြုရန် အခြားတန်ဖိုး (“ အမျိုးသမီး” ) ကို ကိုယ်စားပြုနိုင်သည်-
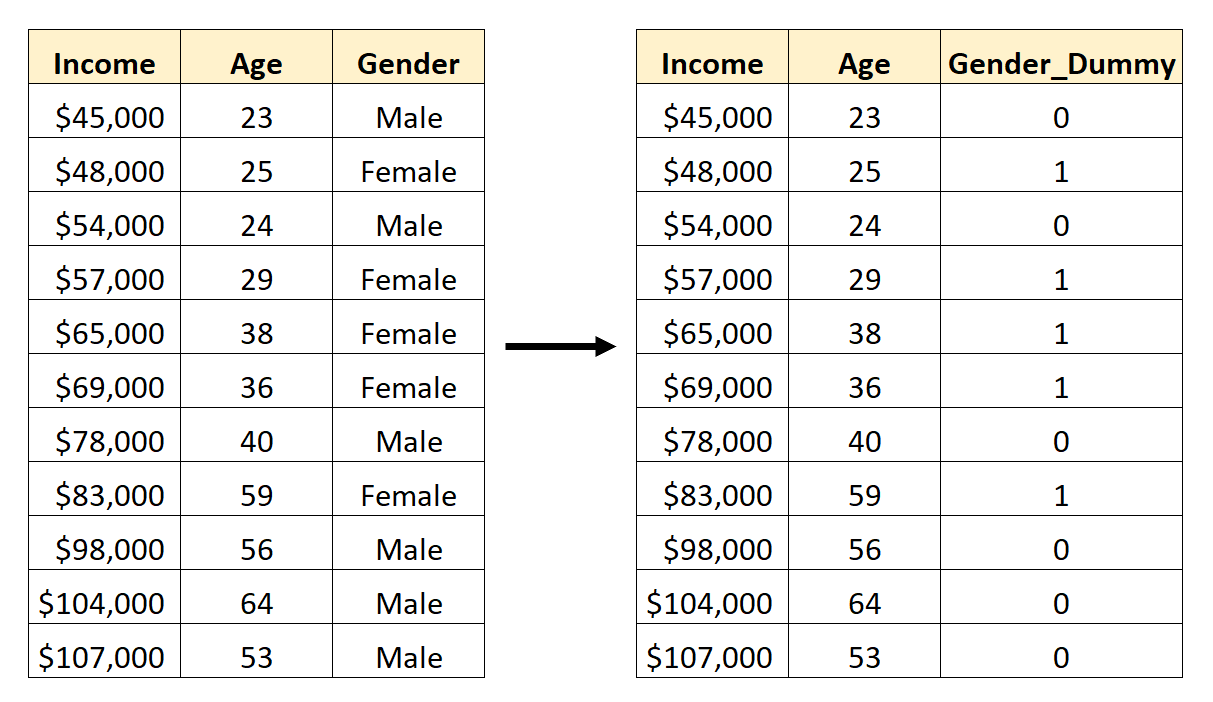
Pandas တွင် dummy variable များကိုဖန်တီးနည်း
pandas DataFrame အတွင်းရှိ variable တစ်ခုအတွက် dummies ဖန်တီးရန်၊ အောက်ပါအခြေခံ syntax ကိုအသုံးပြုထားသည့် pandas.get_dummies() လုပ်ဆောင်ချက်ကို အသုံးပြုနိုင်ပါသည်။
pandas.get_dummies(ဒေတာ၊ ရှေ့ဆုံး=မရှိ၊ ကော်လံ=မရှိ၊ drop_first=False)
ရွှေ-
- data : ပန်ဒါ DataFrame ၏အမည်
- ရှေ့ထွက် – dummy variable ကော်လံအသစ်၏အစတွင် ထည့်ရန် စာကြောင်းတစ်ခု
- ကော်လံများ – dummy variable အဖြစ်ပြောင်းရန် ကော်လံ(များ) ၏ အမည်
- drop_first : ပထမဆုံး dummy variable ကော်လံကို လွှတ်ချရန်၊
အောက်ဖော်ပြပါ ဥပမာများသည် ဤလုပ်ဆောင်ချက်ကို လက်တွေ့အသုံးချနည်းကို ပြသထားသည်။
ဥပမာ 1- dummy variable တစ်ခုတည်းကို ဖန်တီးပါ။
ကျွန်ုပ်တို့တွင် အောက်ပါ ပန်ဒါ DataFrame ရှိသည် ဆိုပါစို့။
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M']}) #view DataFrame df income age gender 0 45 23 M 1 48 25 F 2 54 24 M 3 57 29 F 4 65 38 F 5 69 36 F 6 78 40 M
pd.get_dummies() လုပ်ဆောင်ချက်ကို အသုံးပြု၍ လိင်ကို dummy variable အဖြစ် ပြောင်းလဲနိုင်သည်-
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender '], drop_first= True ) income age gender_M 0 45 23 1 1 48 25 0 2 54 24 1 3 57 29 0 4 65 38 0 5 69 36 0 6 78 40 1
ကျား-မ ကော်လံသည် ယခုအခါတွင် ကိန်းသေပုံစံပြောင်းနိုင်သည့် ပုံစံဖြစ်သည်-
- 0 တန်ဖိုးသည် “ အမျိုးသမီး” ကို ကိုယ်စားပြုသည်
- 1 ၏တန်ဖိုးသည် “ ယောကျာ်း” ကိုကိုယ်စားပြုသည်
ဥပမာ 2- dummy variable အများအပြားကို ဖန်တီးပါ။
ကျွန်ုပ်တို့တွင် အောက်ပါ ပန်ဒါ DataFrame ရှိသည် ဆိုပါစို့။
import pandas as pd #createDataFrame df = pd. DataFrame ({' income ': [45, 48, 54, 57, 65, 69, 78], ' age ': [23, 25, 24, 29, 38, 36, 40], ' gender ': ['M', 'F', 'M', 'F', 'F', 'F', 'M'], ' college ': ['Y', 'N', 'N', 'N', 'Y', 'Y', 'Y']}) #view DataFrame df income age gender college 0 45 23 M Y 1 48 25 F N 2 54 24 M N 3 57 29 F N 4 65 38 F Y 5 69 36 F Y 6 78 40 M Y
pd.get_dummies() လုပ်ဆောင်ချက်ကို အသုံးပြု၍ လိင်နှင့်ကောလိပ်ကို dummy variable အဖြစ်သို့ပြောင်းလဲနိုင်သည်-
#convert gender to dummy variable p.d. get_dummies (df, columns=[' gender ', ' college '], drop_first= True ) income age gender_M college_Y 0 45 23 1 1 1 48 25 0 0 2 54 24 1 0 3 57 29 0 0 4 65 38 0 1 5 69 36 0 1 6 78 40 1 1
ကျား-မ ကော်လံသည် ယခုအခါတွင် ကိန်းသေပုံစံပြောင်းနိုင်သည့် ပုံစံဖြစ်သည်-
- 0 တန်ဖိုးသည် “ အမျိုးသမီး” ကို ကိုယ်စားပြုသည်
- 1 ၏တန်ဖိုးသည် “ ယောကျာ်း” ကိုကိုယ်စားပြုသည်
ကောလိပ်ကော်လံသည် ယခုအခါတွင် ကိန်းသေပုံစံပြောင်းနိုင်သည့် ပုံစံဖြစ်နေပါသည်။
- 0 တန်ဖိုးသည် “ No” တက္ကသိုလ်ကို ကိုယ်စားပြုသည်။
- 1 တန်ဖိုးသည် ကောလိပ်သို့ “ Yes” ကို ကိုယ်စားပြုသည်။
ထပ်လောင်းအရင်းအမြစ်များ
regression ခွဲခြမ်းစိတ်ဖြာမှုတွင် dummy variables ကိုအသုံးပြုနည်း
dummy variable trap ကဘာလဲ။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။