စက်သင်ယူမှုတွင် ဘက်လိုက်မှုကွဲလွဲမှု အပေးအယူသည် အဘယ်နည်း။
ဒေတာအတွဲတစ်ခုပေါ်ရှိ မော်ဒယ်တစ်ခု၏ စွမ်းဆောင်ရည်ကို အကဲဖြတ်ရန်၊ ကျွန်ုပ်တို့သည် မော်ဒယ်၏ ခန့်မှန်းချက်များသည် စောင့်ကြည့်လေ့လာထားသော ဒေတာနှင့် မည်မျှကိုက်ညီကြောင်း တိုင်းတာရန် လိုအပ်ပါသည်။
ဆုတ်ယုတ်မှုပုံစံ များအတွက်၊ အသုံးအများဆုံးမက်ထရစ်မှာ အောက်ပါအတိုင်းတွက်ချက်ထားသည့် mean square error (MSE) ဖြစ်သည်။
MSE = (1/n)*Σ(y i – f(x i )) ၂
ရွှေ-
- n- လေ့လာတွေ့ရှိချက်စုစုပေါင်း
- y i : IT Observation ၏ တုံ့ပြန်မှုတန်ဖိုး
- f(x i ): i th observation ၏ ခန့်မှန်းထားသော တုံ့ပြန်မှုတန်ဖိုး
မော်ဒယ်ခန့်မှန်းချက်များသည် စောင့်ကြည့်မှုများနှင့် နီးကပ်လေ၊ MSE သည် နိမ့်လေဖြစ်သည်။
သို့သော်၊ ကျွန်ုပ်တို့သည် ကျွန်ုပ်တို့၏မော်ဒယ်ကို မမြင်ရသောဒေတာအတွက် အသုံးပြုသည့်အခါ MSE စာမေးပွဲကို သာ အာရုံစိုက်ပါသည်။ အကြောင်းမှာ ကျွန်ုပ်တို့သည် ရှိပြီးသားဒေတာပေါ်တွင်မဟုတ်ဘဲ အမည်မသိဒေတာတွင် မော်ဒယ်မည်သို့လုပ်ဆောင်မည်ကို ကျွန်ုပ်တို့ ဂရုစိုက်သောကြောင့်ဖြစ်သည်။
ဥပမာအားဖြင့်၊ စတော့စျေးနှုန်းများကို ခန့်မှန်းသည့် မော်ဒယ်တစ်ခုတွင် သမိုင်းဆိုင်ရာ အချက်အလက်များတွင် MSE နိမ့်ပါက ကောင်းမွန်သော်လည်း အနာဂတ်ဒေတာကို တိကျစွာ ခန့်မှန်းရန် မော်ဒယ်ကို အမှန်တကယ် အသုံးပြုလိုပါသည်။
MSE စာမေးပွဲကို အပိုင်းနှစ်ပိုင်းခွဲထားနိုင်သေးကြောင်း တွေ့ရှိရပါသည်။
(1) ကွဲပြားမှု- မတူညီသော လေ့ကျင့်မှုအစုံကို အသုံးပြု၍ ခန့်မှန်းပါက ကျွန်ုပ်တို့၏လုပ်ဆောင်ချက် f ပြောင်းလဲမည့်ပမာဏကို ရည်ညွှန်းသည်။
(၂) ဘက်လိုက်မှု- အလွန်ရိုးရှင်းသော ပုံစံဖြင့် တကယ့်ပြဿနာကို ချဉ်းကပ်ခြင်းဖြင့် တင်ပြခဲ့သော အမှားကို ရည်ညွှန်းသည်။
သင်္ချာအသုံးအနှုန်းများဖြင့် ရေးသားထားသည်-
MSE စမ်းသပ်မှု = Var( f̂( x 0 )) + [Bias( f̂( x 0 ))] 2 + Var(ε)
MSE စမ်းသပ်မှု = Variance + Bias 2 + Irreducible အမှား
တတိယအခေါ်အဝေါ်၊ အစားထိုးမရနိုင်သောအမှားသည် မည်သည့်ပုံစံဖြင့်မျှ လျှော့ချ၍မရသော အမှားဖြစ်ပြီး ရှင်းလင်းချက်ပြောင်းနိုင်သောကိန်းရှင်အစုများနှင့် တုံ့ပြန်မှုကိန်းရှင်များ ကြားတွင် ဆူညံသံ အမြဲရှိနေသောကြောင့်ဖြစ်သည်။
ဘက်လိုက်မှု မြင့်မား သော မော်ဒယ်များသည် ကွဲလွဲမှု နည်းပါး တတ်သည်။ ဥပမာအားဖြင့်၊ linear regression မော်ဒယ်များသည် ဘက်လိုက်မှုမြင့်မားလေ့ရှိသည် (ရှင်းလင်းချက်ကိန်းရှင်များနှင့် တုံ့ပြန်မှုကိန်းရှင်ကြား ရိုးရှင်းသောမျဉ်းကြောင်းဆက်နွယ်မှုဟု ယူဆသည်) နှင့် ကွဲလွဲမှုနည်းပါးသည် (မော်ဒယ်ခန့်မှန်းချက်သည် နမူနာမှနမူနာသို့ များစွာပြောင်းလဲမည်မဟုတ်ပါ)။ အခြား)။
သို့သော် ဘက်လိုက်မှုနည်း သော မော်ဒယ်များသည် ကွဲပြားမှု မြင့်မား တတ်သည်။ ဥပမာအားဖြင့်၊ ရှုပ်ထွေးသော လိုင်းမဟုတ်သော မော်ဒယ်များသည် ဘက်လိုက်မှု နည်းပါးတတ်သည် (ရှင်းပြချက် ကိန်းရှင်များနှင့် တုံ့ပြန်မှု ကိန်းရှင်ကြား ဆက်စပ်မှုဟု မယူဆပါနှင့်) ကွဲပြားမှု မြင့်မားသည် (မော်ဒယ် ခန့်မှန်းချက်များသည် သင်ယူမှု နမူနာမှ အခြားတစ်ခုသို့ သိသိသာသာ ပြောင်းလဲနိုင်သည်)။
အပေးအယူ ဘက်လိုက်မှုကွဲလွဲမှု
Bias-variance အပေးအယူသည် ယေဘုယျအားဖြင့် ဘက်လိုက်မှုကို တိုးလာစေသည့် ဘက်လိုက်မှုကို လျှော့ချရန် ကျွန်ုပ်တို့ရွေးချယ်သောအခါတွင် ဖြစ်ပေါ်သည့် အပေးအယူကို ရည်ညွှန်းသည်။
အောက်ပါဂရပ်သည် ဤအပေးအယူကို မြင်သာစေရန် နည်းလမ်းကို ပေးဆောင်သည်-
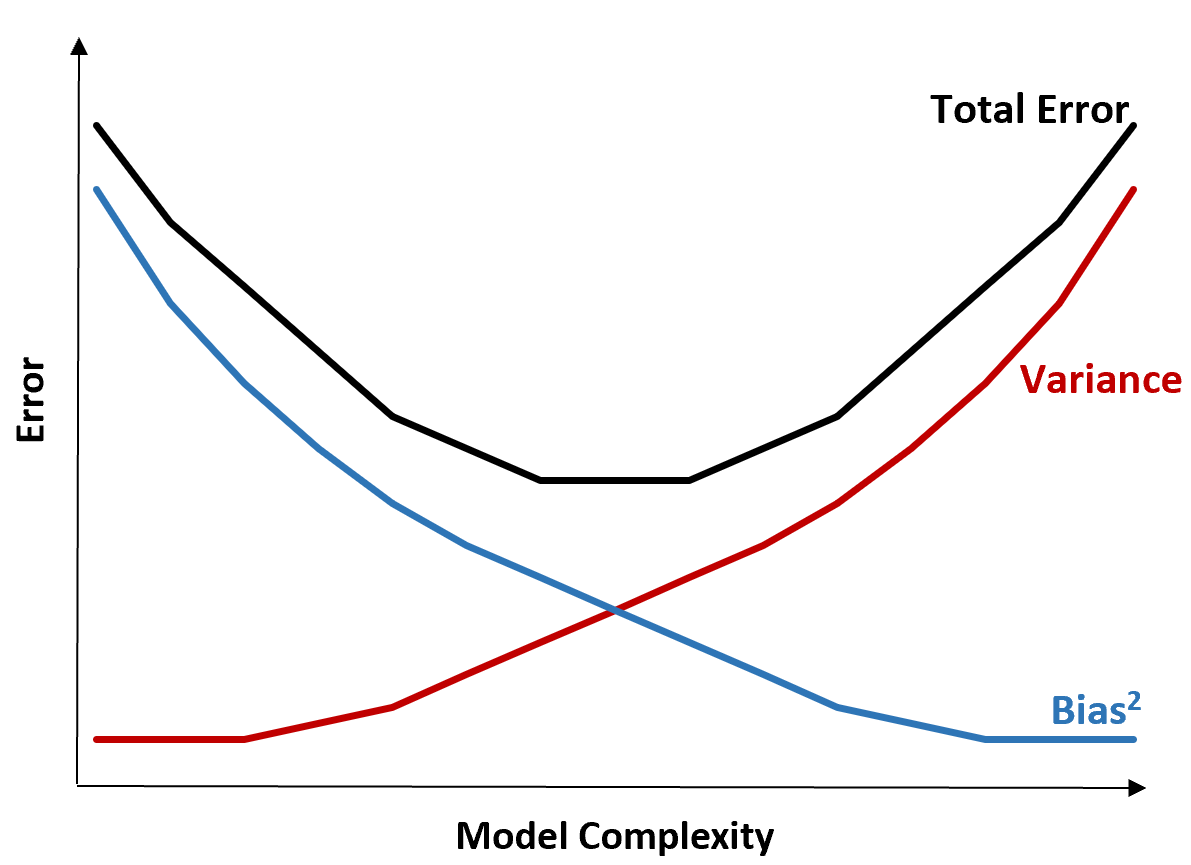
မော်ဒယ်တစ်ခု၏ ရှုပ်ထွေးမှုများ တိုးလာသည်နှင့်အမျှ စုစုပေါင်း error လျော့နည်းသွားသည်၊ သို့သော် အချို့သောအချက်များအထိသာ။ အချို့သောအချက်ကိုကျော်လွန်၍ ကွဲလွဲမှုစတင်လာပြီး စုစုပေါင်းအမှားအယွင်းများလည်း တိုးလာပါသည်။
လက်တွေ့တွင်၊ ကျွန်ုပ်တို့သည် ကွဲပြားမှု သို့မဟုတ် ဘက်လိုက်မှုကို လျှော့ချရန် မလိုအပ်ဘဲ မော်ဒယ်တစ်ခု၏ စုစုပေါင်းအမှားကို လျှော့ချရန်သာ အာရုံစိုက်ပါသည်။ စုစုပေါင်းအမှားကို လျှော့ချရန် နည်းလမ်းမှာ ကွဲလွဲမှုနှင့် ဘက်လိုက်မှုကြား မှန်ကန်သော ချိန်ခွင်လျှာကို ရှာဖွေရန်ဖြစ်သည်ကို တွေ့ရှိရသည်။
တစ်နည်းဆိုရသော် ကျွန်ုပ်တို့သည် ရှင်းလင်းချက်ကိန်းရှင်များနှင့် တုံ့ပြန်မှုကိန်းရှင်ကြားရှိ စစ်မှန်သောဆက်နွယ်မှုကို ဖမ်းယူနိုင်လောက်အောင် ရှုပ်ထွေးသည့် စံပြပုံစံကို လိုချင်သော်လည်း လက်တွေ့တွင် မရှိသည့်ပုံစံများကို ရှာဖွေရန် အလွန်ရှုပ်ထွေးမည်မဟုတ်ပါ။
မော်ဒယ်တစ်ခုသည် ရှုပ်ထွေးလွန်းသောအခါ၊ ၎င်းသည် ဒေတာ နှင့် ပိုကိုက်ညီသည် ။ အခွင့်အလမ်းကြောင့်ဖြစ်ရသည့် လေ့ကျင့်ရေးဒေတာတွင် ပုံစံများကိုရှာဖွေရန် အလွန်ခက်ခဲသောကြောင့်ဖြစ်သည်။ ဤပုံစံသည် မမြင်နိုင်သောဒေတာများတွင် ညံ့ဖျင်းစွာလုပ်ဆောင်နိုင်ဖွယ်ရှိသည်။
ဒါပေမယ့် မော်ဒယ်တစ်ခုက ရိုးရှင်းလွန်းတဲ့အခါ အချက်အလက်ကို လျှော့တွက်တယ် ။ ရှင်းလင်းချက်ကိန်းရှင်များနှင့် တုံ့ပြန်မှုကိန်းရှင်ကြားရှိ စစ်မှန်သောဆက်နွယ်မှုမှာ ၎င်းထက်ပိုမိုရိုးရှင်းသည်ဟု ယူဆသောကြောင့် ထိုသို့ဖြစ်ရခြင်းဖြစ်ပေသည်။
စက်သင်ယူမှုတွင် အကောင်းဆုံးမော်ဒယ်များကို ရွေးချယ်ရန်နည်းလမ်းမှာ အနာဂတ်မမြင်ရသောဒေတာများတွင် မော်ဒယ်စမ်းသပ်မှုအမှားကို လျှော့ချရန် ဘက်လိုက်မှုနှင့် ကွဲလွဲမှုအကြား ဟန်ချက်ညီမှုကို ရှာဖွေရန်ဖြစ်သည်။
လက်တွေ့တွင်၊ စစ်ဆေးမှုများ၏ MSE ကိုလျှော့ချရန် အသုံးအများဆုံးနည်းလမ်းမှာ cross-validation ကို အသုံးပြုခြင်းဖြစ်သည်။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။