ဘာကို "ကောင်း" လို့ သတ်မှတ်သလဲ။ f1 ရမှတ်?
စက်သင်ယူမှုတွင် အမျိုးအစားခွဲခြင်းပုံစံများကို အသုံးပြုသည့်အခါ၊ မော်ဒယ်အရည်အသွေးကို အကဲဖြတ်ရန် ကျွန်ုပ်တို့အသုံးပြုလေ့ရှိသည့် မက်ထရစ်မှာ F1 ရမှတ် ဖြစ်သည်။
ဤမက်ထရစ်ကို အောက်ပါအတိုင်း တွက်ချက်သည်-
F1 ရမှတ် = 2 * (တိကျမှု * ပြန်လည်ခေါ်ယူခြင်း) / (တိကျမှု + ပြန်လည်ခေါ်ယူခြင်း)
ရွှေ-
- တိကျမှု – စုစုပေါင်း အပြုသဘောဆောင်သော ခန့်မှန်းချက်များနှင့် ဆက်စပ်သော အပြုသဘောဆောင်သော ခန့်မှန်းချက်များကို မှန်ကန်စွာ ပြင်ပါ။
- သတိပေးချက် – စုစုပေါင်းအမှန်တကယ် အပြုသဘောဆောင်သည့် အပြုသဘောဆောင်သော ခန့်မှန်းချက်များကို ပြုပြင်ခြင်း။
ဥပမာအားဖြင့်၊ ကျွန်ုပ်တို့သည် မတူညီသောကောလိပ်ဘတ်စကက်ဘောကစားသမား 400 ကို NBA သို့ရေးဆွဲမည်လား မခန့်မှန်းရန် ထောက်ပံ့ပို့ဆောင်ရေးဆုတ်ယုတ်မှုပုံစံကို အသုံးပြုသည်ဆိုပါစို့။
အောက်ဖော်ပြပါ ရှုပ်ထွေးမှု matrix သည် မော်ဒယ်မှ ပြုလုပ်သော ခန့်မှန်းချက်များကို အကျဉ်းချုပ်ဖော်ပြသည်-

ဤသည်မှာ မော်ဒယ်၏ F1 ရမှတ်ကို တွက်ချက်နည်းဖြစ်သည်။
တိကျမှု = True Positive / (True Positive + False Positive) = 120/ (120+70) = 0.63157
Recall = True Positive / (True Positive + False Negative) = 120 / (120+40) = 0.75
F1 ရမှတ် = 2 * (.63157 * .75) / (.63157 + .75) = . ၆၈၅၇
F1 ရမှတ်ကောင်းဆိုတာဘာလဲ။
ကျောင်းသားတွေ မေးလေ့ရှိတဲ့ မေးခွန်းတစ်ခုကတော့
F1 မှာ ရမှတ်ကောင်းဆိုတာဘာလဲ။
ရိုးရိုးရှင်းရှင်းပြောရလျှင် F1 ရမှတ်များသည် ယေဘုယျအားဖြင့် ပိုကောင်းပါသည်။
F1 ရမှတ်များသည် 0 မှ 1 အထိ ကွာဟနိုင်ပြီး 1 သည် စောင့်ကြည့်မှုတစ်ခုစီကို မှန်ကန်သောအတန်းအဖြစ် စုံလင်စွာခွဲခြားသတ်မှတ်ပေးသည့် မော်ဒယ်ကိုကိုယ်စားပြုပြီး 0 သည် မှန်ကန်သောအတန်းအဖြစ် မှတ်သားမှုကို မှန်ကန်သောအတန်းသို့မခွဲခြားနိုင်သော မော်ဒယ်ကိုကိုယ်စားပြုကြောင်း သတိရပါ။
ယင်းကို သရုပ်ဖော်ရန်၊ ကျွန်ုပ်တို့တွင် အောက်ပါရှုပ်ထွေးမှုမက်ထရစ်ကို ထုတ်ပေးသည့် ထောက်ပံ့ပို့ဆောင်ရေး ဆုတ်ယုတ်မှုပုံစံတစ်ခုရှိသည် ဆိုပါစို့။
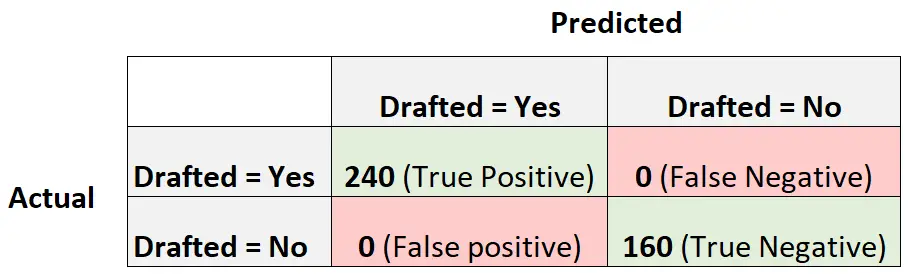
ဤသည်မှာ မော်ဒယ်၏ F1 ရမှတ်ကို တွက်ချက်နည်းဖြစ်သည်။
တိကျမှု = True Positive / (True Positive + False Positive) = 240/ (240+0) = 1
Recall = True Positive / (True Positive + False Negative) = 240 / (240+0) = 1
F1 ရမှတ် = 2 * (1 * 1) / (1 + 1) = 1
F1 ရမှတ်သည် လေ့လာမှု 400 တစ်ခုစီကို အတန်းတစ်ခုအဖြစ် စုံလင်စွာ ခွဲခြားနိုင်သောကြောင့် ၎င်းသည် တစ်ခုနှင့်ညီမျှသည်။
ကစားသမားတစ်ဦးစီကို ရေးဆွဲမည်ဟု ရိုးရိုးရှင်းရှင်း ခန့်မှန်းထားသည့် အခြားသော ထောက်ပံ့ပို့ဆောင်ရေး ဆုတ်ယုတ်မှုပုံစံကို ယခု သုံးသပ်ကြည့်ပါ-
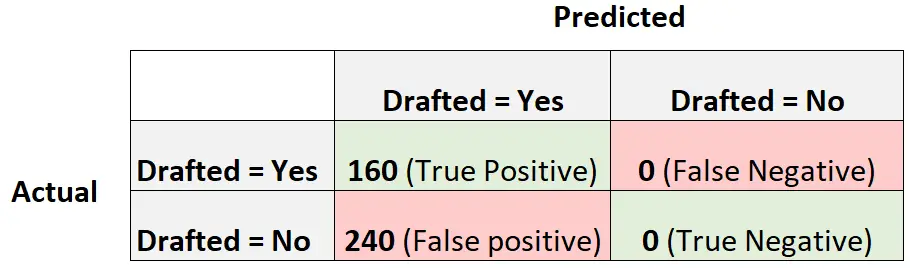
ဤသည်မှာ မော်ဒယ်၏ F1 ရမှတ်ကို တွက်ချက်နည်းဖြစ်သည်။
တိကျမှု = True Positive / (True Positive + False Positive) = 160/ (160+240) = 0.4
Recall = True Positive / (True Positive + False Negative) = 160 / (160+0) = 1
F1 ရမှတ် = 2 * (.4 * 1) / (.4 + 1) = 0.5714၊
၎င်းသည် ဒေတာအတွဲရှိ စောင့်ကြည့်မှုတိုင်းအတွက် တူညီသောခန့်မှန်းချက်ဖြစ်စေသည့် စံနမူနာကို ကိုယ်စားပြုသောကြောင့် ကျွန်ုပ်တို့၏ logistic regression model ကို နှိုင်းယှဉ်နိုင်သည့် အခြေခံစံနမူနာ အဖြစ် ယူဆနိုင်ပါသည်။
ကျွန်ုပ်တို့၏ F1 ရမှတ်သည် ရည်ညွှန်းမော်ဒယ်တစ်ခုနှင့် နှိုင်းယှဉ်ပါက ပိုမိုမြင့်မားလေ၊ ကျွန်ုပ်တို့၏ မော်ဒယ်သည် ပိုမိုအသုံးဝင်လေဖြစ်သည်။
ကျွန်ုပ်တို့၏မော်ဒယ်တွင် F1 ရမှတ် 0.6857 ရထားသည်ကို အစောပိုင်းက သတိရပါ။ ၎င်းသည် 0.5714 ထက် များစွာမမြင့်ပါ၊ ကျွန်ုပ်တို့၏မော်ဒယ်သည် အခြေခံမော်ဒယ်ထက် ပိုမိုအသုံးဝင်ကြောင်း ညွှန်ပြသော်လည်း များများစားစားမရှိပါ။
F1 ရမှတ်များကို နှိုင်းယှဉ်ခြင်း။
လက်တွေ့တွင်၊ ကျွန်ုပ်တို့သည် အမျိုးအစားခွဲခြင်းပြဿနာအတွက် “ အကောင်းဆုံး” မော်ဒယ်ကို ရွေးချယ်ရန် အောက်ပါလုပ်ငန်းစဉ်ကို အသုံးပြုလေ့ရှိသည်-
အဆင့် 1- လေ့လာမှုတစ်ခုစီအတွက် တူညီသောခန့်မှန်းချက်ကို ပြုလုပ်နိုင်သော ရည်ညွှန်းပုံစံတစ်ခုကို ကွက်တိပါ။
အဆင့် 2- မတူညီသော အမျိုးအစားခွဲခြားထားသော မော်ဒယ်များစွာကို ကိုက်ညီပြီး မော်ဒယ်တစ်ခုစီအတွက် F1 ရမှတ်ကို တွက်ချက်ပါ။
အဆင့် 3- ရည်ညွှန်းမော်ဒယ်ထက် F1 ရမှတ် ပိုမြင့်မားကြောင်း အတည်ပြုပြီး “ အကောင်းဆုံး” မော်ဒယ်အဖြစ် F1 ရမှတ် အမြင့်ဆုံး မော်ဒယ်ကို ရွေးချယ်ပါ။
တိကျသောတန်ဖိုးကို “ ကောင်း” F1 ရမှတ်ဟု မယူဆပါ၊ ထို့ကြောင့် ကျွန်ုပ်တို့သည် အမြင့်ဆုံး F1 ရမှတ်ကိုထုတ်ပေးသည့် အမျိုးအစားခွဲခြားပုံစံကို ယေဘူယျအားဖြင့် ရွေးချယ်ပါသည်။
ထပ်လောင်းအရင်းအမြစ်များ
F1 ရမှတ်နှင့် တိကျမှု- မည်သည့်အရာကို အသုံးပြုသင့်သနည်း။
R တွင် F1 ရမှတ်ကိုဘယ်လိုတွက်မလဲ။
Python တွင် F1 ရမှတ်ကို တွက်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။