Python တွင် bivariate ခွဲခြမ်းစိတ်ဖြာမှုပြုလုပ်နည်း- ဥပမာများဖြင့်
bivariate analysis ဟူသော ဝေါဟာရသည် ကိန်းရှင်နှစ်ခု၏ ခွဲခြမ်းစိတ်ဖြာမှုကို ရည်ညွှန်းသည်။ ရှေ့ဆက် “ bi” သည် “ နှစ်ခု” ဖြစ်သောကြောင့်၎င်းကိုသင်မှတ်မိနိုင်သည်။
bivariate ခွဲခြမ်းစိတ်ဖြာခြင်း၏ပန်းတိုင်မှာ variable နှစ်ခုကြားရှိ ဆက်နွယ်မှုကို နားလည်ရန်ဖြစ်သည်။
bivariate ခွဲခြမ်းစိတ်ဖြာမှုကို လုပ်ဆောင်ရန် ဘုံနည်းလမ်းသုံးမျိုးရှိသည်။
1. တိမ်ညွှန်
2. ဆက်စပ်ကိန်းများ
3. ရိုးရှင်းသောမျဉ်းကြောင်းဆုတ်ယုတ်မှု
အောက်ပါဥပမာသည် ကိန်းရှင်နှစ်ခုအကြောင်း အချက်အလက်ပါရှိသော အောက်ပါ pandas DataFrame ကိုအသုံးပြု၍ Python တွင် ဤ bivariate ခွဲခြမ်းစိတ်ဖြာမှုအမျိုးအစားတစ်ခုစီကို မည်သို့လုပ်ဆောင်ရမည်ကို ပြသသည်- (1) လေ့လာချိန်နာရီများနှင့် (2) မတူညီသောကျောင်းသား 20 မှရရှိသော စာမေးပွဲရမှတ်-
import pandas as pd #createDataFrame df = pd. DataFrame ({' hours ': [1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 5, 5, 6, 6, 6, 7, 8], ' score ': [75, 66, 68, 74, 78, 72, 85, 82, 90, 82, 80, 88, 85, 90, 92, 94, 94, 88, 91, 96]}) #view first five rows of DataFrame df. head () hours score 0 1 75 1 1 66 2 1 68 3 2 74 4 2 78
1. တိမ်ညွှန်
စာမေးပွဲရလဒ်များနှင့် နှိုင်းယှဉ်လေ့လာထားသော နာရီများ၏ အပိုင်းအစတစ်ခုကို ဖန်တီးရန် အောက်ပါ syntax ကို အသုံးပြုနိုင်ပါသည်။
import matplotlib. pyplot as plt #create scatterplot of hours vs. score plt. scatter (df. hours , df. score ) plt. title (' Hours Studied vs. Exam Score ') plt. xlabel (' Hours Studied ') plt. ylabel (' Exam Score ')
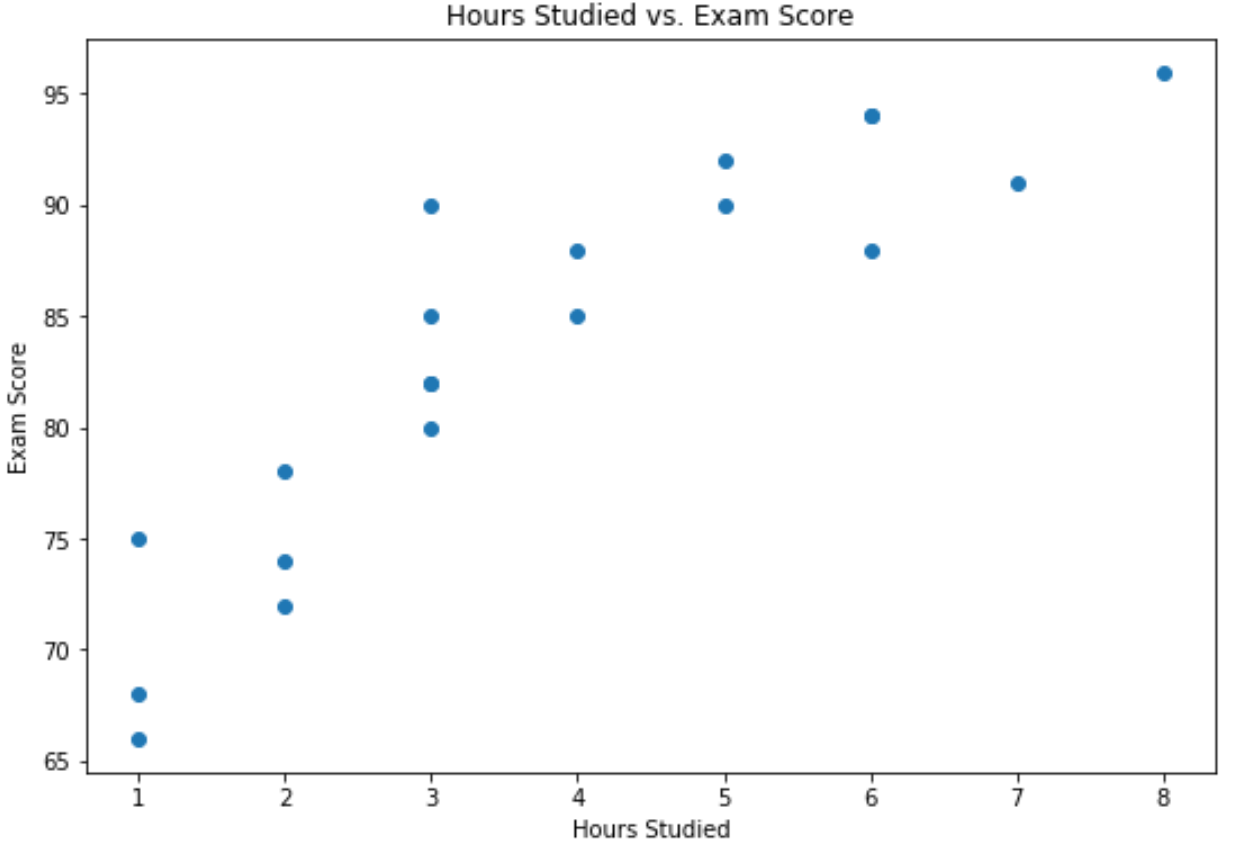
x-axis သည် လေ့လာထားသောနာရီများကိုပြသပြီး y-axis သည် စာမေးပွဲတွင်ရရှိသောအဆင့်ကိုပြသသည်။
ကိန်းရှင်နှစ်ခုကြားတွင် အပြုသဘောဆောင်သော ဆက်နွယ်မှုရှိကြောင်း ဂရပ်က ဖော်ပြသည်- လေ့လာမှု နာရီအရေအတွက် တိုးလာသည်နှင့်အမျှ စာမေးပွဲရမှတ်များလည်း တိုးလာတတ်သည်။
2. ဆက်စပ်ကိန်းများ
Pearson ဆက်စပ်ဆက်စပ်ကိန်းတစ်ခုသည် ကိန်းရှင်နှစ်ခုကြားရှိ မျဉ်းကြောင်းဆက်နွယ်မှုကို တွက်ဆရန်နည်းလမ်းတစ်ခုဖြစ်သည်။
ဆက်စပ်မက်ထရစ်ကိုဖန်တီးရန် ပန်ဒါများရှိ corr() လုပ်ဆောင်ချက်ကို ကျွန်ုပ်တို့အသုံးပြုနိုင်သည်-
#create correlation matrix df. corr () hours score hours 1.000000 0.891306 score 0.891306 1.000000
ဆက်စပ်ကိန်းဂဏန်းသည် 0.891 ဖြစ်လာသည်။ ၎င်းသည် လေ့လာသည့်နာရီနှင့် စာမေးပွဲအဆင့်ကြား ခိုင်မာသော အပြုသဘောဆောင်သော ဆက်စပ်မှုကို ညွှန်ပြသည်။
3. ရိုးရှင်းသောမျဉ်းကြောင်းဆုတ်ယုတ်မှု
ရိုးရှင်းသော linear regression သည် variable နှစ်ခုကြားရှိ ဆက်နွယ်မှုကို တွက်ချက်ရန်အတွက် အသုံးပြုနိုင်သော ကိန်းဂဏန်းဆိုင်ရာ နည်းလမ်းတစ်ခုဖြစ်သည်။
နာရီပေါင်းများစွာ လေ့လာပြီး ရရှိလာသော စာမေးပွဲရလဒ်များကို ရိုးရှင်းသော linear regression model နှင့် အမြန်ကိုက်ညီရန် statsmodels package မှ OLS() လုပ်ဆောင်ချက်ကို အသုံးပြုနိုင်ပါသည်။
import statsmodels. api as sm #define response variable y = df[' score '] #define explanatory variable x = df[[' hours ']] #add constant to predictor variables x = sm. add_constant (x) #fit linear regression model model = sm. OLS (y,x). fit () #view model summary print ( model.summary ()) OLS Regression Results ==================================================== ============================ Dept. Variable: R-squared score: 0.794 Model: OLS Adj. R-squared: 0.783 Method: Least Squares F-statistic: 69.56 Date: Mon, 22 Nov 2021 Prob (F-statistic): 1.35e-07 Time: 16:15:52 Log-Likelihood: -55,886 No. Observations: 20 AIC: 115.8 Df Residuals: 18 BIC: 117.8 Model: 1 Covariance Type: non-robust ==================================================== ============================ coef std err t P>|t| [0.025 0.975] -------------------------------------------------- ---------------------------- const 69.0734 1.965 35.149 0.000 64.945 73.202 hours 3.8471 0.461 8.340 0.000 2.878 4.816 ==================================================== ============================ Omnibus: 0.171 Durbin-Watson: 1.404 Prob(Omnibus): 0.918 Jarque-Bera (JB): 0.177 Skew: 0.165 Prob(JB): 0.915 Kurtosis: 2.679 Cond. No. 9.37 ==================================================== ============================
တပ်ဆင်ထားသော ဆုတ်ယုတ်မှုညီမျှခြင်းမှာ-
စာမေးပွဲရမှတ် = 69.0734 + 3.8471*(စာသင်ချိန်)
ထပ်လောင်းလေ့လာထားသောနာရီတိုင်းသည် စာမေးပွဲရမှတ်တွင် ပျမ်းမျှ 3.8471 တိုးလာခြင်းနှင့် ဆက်စပ်နေကြောင်း ၎င်းကဆိုသည်။
ကျောင်းသားတစ်ဦးရရှိမည့်ရမှတ်ကို ခန့်မှန်းရန် တပ်ဆင်ထားသည့် ဆုတ်ယုတ်မှုညီမျှခြင်းကိုလည်း အသုံးပြု၍ လေ့လာခဲ့သည့် စုစုပေါင်းနာရီအရေအတွက်အပေါ် မူတည်၍ ကျောင်းသားတစ်ဦးရရှိမည့်ရမှတ်ကို ခန့်မှန်းနိုင်သည်။
ဥပမာအားဖြင့်၊ ၃ နာရီစာလေ့လာသော ကျောင်းသားသည် ရမှတ် 81.6147 ရသင့်သည် ။
- စာမေးပွဲရမှတ် = 69.0734 + 3.8471*(စာသင်ချိန်)
- စာမေးပွဲရမှတ် = 69.0734 + 3.8471*(3)
- စာမေးပွဲရလဒ် = 81.6147
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် bivariate ခွဲခြမ်းစိတ်ဖြာခြင်းဆိုင်ရာ နောက်ထပ်အချက်အလက်များကို ပေးဆောင်သည်-
Bivariate ခွဲခြမ်းစိတ်ဖြာခြင်းအတွက် နိဒါန်း
လက်တွေ့ဘဝတွင် bivariate data နမူနာ ၅ ခု
Simple Linear Regression နိဒါန်း
Pearson Correlation Coefficient နိဒါန်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။