Python ရှိ principal component regression (အဆင့်ဆင့်)
p ကြိုတင်ခန့်မှန်းကိန်းရှင် ကိန်းရှင်အစုတစ်ခုနှင့် တုံ့ပြန်မှုကိန်းရှင်တစ်ခုအား ပေးထားသည့် မျဉ်းကြောင်းပြန်ဆုတ်မှုအများအပြားသည် ကျန်ရှိသောစတုရန်း၏ပေါင်းလဒ် (RSS) ကို လျှော့ချရန် အနည်းဆုံးစတုရန်းများဟု သိထားသောနည်းလမ်းကို အသုံးပြုသည်-
RSS = Σ(y i – ŷ i ) ၂
ရွှေ-
- ∑ : ပေါင်းလဒ် ဟု အဓိပ္ပာယ်ရသော ဂရိသင်္ကေတ
- y i : အိုင်တီ လေ့လာခြင်းအတွက် အမှန်တကယ် တုံ့ပြန်မှုတန်ဖိုး
- ŷ i : Multiple linear regression model ကို အခြေခံ၍ ခန့်မှန်းထားသော တုံ့ပြန်မှုတန်ဖိုး
သို့ရာတွင်၊ ကြိုတင်ခန့်မှန်းနိုင်သောကိန်းရှင်များသည် အလွန်ဆက်စပ်နေသောအခါတွင်၊ ကော်လိုင်းပေါင်းစုံသည် ပြဿနာဖြစ်လာနိုင်သည်။ ၎င်းသည် မော်ဒယ်ဖော်ကိန်း ခန့်မှန်းချက်များကို ယုံကြည်စိတ်ချမှုမရှိစေဘဲ ကွဲပြားမှုမြင့်မားမှုကို ပြသနိုင်သည်။
ဤပြဿနာကို ရှောင်ရှားရန် နည်းလမ်းတစ်ခုမှာ မူလ p ကြိုတင်တွက်ဆမှုများ၏ M linear ပေါင်းစပ်မှုများ (“ principal components” ဟုခေါ်သည်) ကိုရှာပေးသည့် အဓိကအစိတ်အပိုင်းများ ဆုတ်ယုတ်မှု အား အသုံးပြုပြီး ပင်မအစိတ်အပိုင်းများကို ကြိုတင်ဟောကိန်းထုတ်သူများအဖြစ် အသုံးပြုကာ မျဉ်းကြောင်းဆုတ်ယုတ်မှုပုံစံတစ်ခုနှင့် ကိုက်ညီရန် အနည်းဆုံးစတုရန်းများကို အသုံးပြုခြင်းဖြစ်သည်။
ဤသင်ခန်းစာသည် Python တွင် အဓိကအစိတ်အပိုင်းများ ဆုတ်ယုတ်ခြင်းကို လုပ်ဆောင်ပုံအဆင့်ဆင့်ကို ဥပမာပေးထားသည်။
အဆင့် 1- လိုအပ်သော ပက်ကေ့ခ်ျများကို တင်သွင်းပါ။
ဦးစွာ၊ Python ရှိ အဓိကအစိတ်အပိုင်းဆုတ်ယုတ်မှု (PCR) လုပ်ဆောင်ရန် လိုအပ်သော ပက်ကေ့ဂျ်များကို တင်သွင်းပါမည်။
import numpy as np
import pandas as pd
import matplotlib. pyplot as plt
from sklearn. preprocessing import scale
from sklearn import model_selection
from sklearn. model_selection import RepeatedKFold
from sklearn.model_selection import train_test_split
from sklearn. PCA import decomposition
from sklearn. linear_model import LinearRegression
from sklearn. metrics import mean_squared_error
အဆင့် 2: ဒေတာကို တင်ပါ။
ဤဥပမာအတွက်၊ ကျွန်ုပ်တို့သည် မတူညီသောကား ၃၃ စီးရှိ အချက်အလက်များပါရှိသော mtcars ဟုခေါ်သော ဒေတာအစုံကို အသုံးပြုပါမည်။ ကျွန်ုပ်တို့သည် တုံ့ပြန်မှု variable အဖြစ် hp ကို အသုံးပြုပြီး အောက်ပါ variable များကို ကြိုတင်ခန့်မှန်းသူများအဖြစ် အသုံးပြုပါမည်။
- စိုင်းစိုင်းခမ်းလှိုင်
- ပြသခြင်း။
- ပြောရမှာပါ။
- ကိုယ်အလေးချိန်
- qsec
အောက်ဖော်ပြပါ ကုဒ်သည် ဤဒေတာအတွဲကို မည်သို့တင်၍ ပြသရမည်ကို ပြသသည်-
#define URL where data is located
url = "https://raw.githubusercontent.com/Statorials/Python-Guides/main/mtcars.csv"
#read in data
data_full = pd. read_csv (url)
#select subset of data
data = data_full[["mpg", "disp", "drat", "wt", "qsec", "hp"]]
#view first six rows of data
data[0:6]
mpg disp drat wt qsec hp
0 21.0 160.0 3.90 2.620 16.46 110
1 21.0 160.0 3.90 2.875 17.02 110
2 22.8 108.0 3.85 2.320 18.61 93
3 21.4 258.0 3.08 3.215 19.44 110
4 18.7 360.0 3.15 3.440 17.02 175
5 18.1 225.0 2.76 3.460 20.22 105
အဆင့် 3: PCR မော်ဒယ်ကို ချိန်ညှိပါ။
အောက်ဖော်ပြပါကုဒ်သည် PCR မော်ဒယ်ကို ဤဒေတာနှင့် မည်သို့ အံဝင်ခွင်ကျဖြစ်စေရန် ဖော်ပြသည်။ အောက်ပါတို့ကို သတိပြုပါ။
- pca.fit_transform(scale(X)) : ခန့်မှန်းသူကိန်းရှင်တစ်ခုစီတိုင်းကို ပျမ်းမျှ 0 နှင့် 1 ၏ စံသွေဖည်မှုရှိရန် အတိုင်းအတာတစ်ခုစီရှိသင့်သည်ဟု Python အားပြောထားသည်။ ၎င်းသည် အကယ်၍ ခန့်မှန်းသူကိန်းရှင်သည် မော်ဒယ်တွင် လွှမ်းမိုးမှုအလွန်အကျွံရှိနေကြောင်း သေချာစေပါသည်။ ဒီလိုဖြစ်ပေါ်ပါတယ်။ ယူနစ်အမျိုးမျိုးဖြင့် တိုင်းတာရန်။
- cv = RepeatedKFold() : ၎င်းသည် မော်ဒယ်စွမ်းဆောင်ရည်ကို အကဲဖြတ်ရန် k-fold cross-validation ကို အသုံးပြုရန် Python အား ပြောထားသည်။ ဤဥပမာအတွက် ကျွန်ုပ်တို့သည် k = 10 ခေါက်ကို ရွေးကာ 3 ကြိမ် ထပ်ခါထပ်ခါ လုပ်သည်။
#define predictor and response variables
X = data[["mpg", "disp", "drat", "wt", "qsec"]]
y = data[["hp"]]
#scale predictor variables
pca = pca()
X_reduced = pca. fit_transform ( scale (X))
#define cross validation method
cv = RepeatedKFold(n_splits= 10 , n_repeats= 3 , random_state= 1 )
regr = LinearRegression()
mse = []
# Calculate MSE with only the intercept
score = -1*model_selection. cross_val_score (regr,
n.p. ones ((len(X_reduced),1)), y, cv=cv,
scoring=' neg_mean_squared_error '). mean ()
mse. append (score)
# Calculate MSE using cross-validation, adding one component at a time
for i in np. arange (1, 6):
score = -1*model_selection. cross_val_score (regr,
X_reduced[:,:i], y, cv=cv, scoring=' neg_mean_squared_error '). mean ()
mse. append (score)
# Plot cross-validation results
plt. plot (mse)
plt. xlabel ('Number of Principal Components')
plt. ylabel ('MSE')
plt. title ('hp')
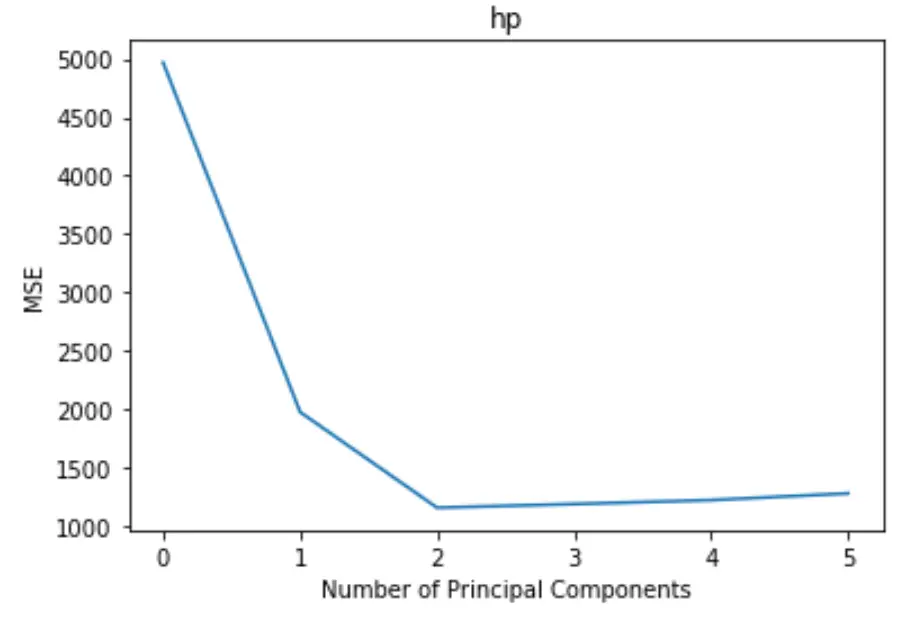
ကွက်ကွက်သည် x-ဝင်ရိုးတစ်လျှောက် အဓိကအစိတ်အပိုင်း အရေအတွက်နှင့် y-ဝင်ရိုးတစ်လျှောက် MSE (ပျမ်းမျှစတုရန်းအမှားအယွင်း) စမ်းသပ်မှုကို ပြသသည်။
ဂရပ်မှ၊ စာမေးပွဲ၏ MSE သည် အဓိကအစိတ်အပိုင်းနှစ်ခုကို ထည့်ခြင်းဖြင့် လျော့နည်းသွားသည်ကို ကျွန်ုပ်တို့တွေ့မြင်နိုင်သည်၊ သို့သော် ကျွန်ုပ်တို့သည် အဓိကအစိတ်အပိုင်း နှစ်ခုထက်ပို၍ တိုးလာသည်နှင့်အမျှ ၎င်းသည် တိုးလာပါသည်။
ထို့ကြောင့် အကောင်းဆုံးမော်ဒယ်တွင် ပထမအဓိကအစိတ်အပိုင်းနှစ်ခုသာ ပါဝင်ပါသည်။
မော်ဒယ်သို့ အဓိကအစိတ်အပိုင်းတစ်ခုစီကို ပေါင်းထည့်ခြင်းဖြင့် ရှင်းပြထားသည့် တုံ့ပြန်မှုကိန်းရှင်၏ ကွဲလွဲမှုရာခိုင်နှုန်းကို တွက်ချက်ရန် အောက်ပါကုဒ်ကို အသုံးပြုနိုင်သည်။
n.p. cumsum (np. round (pca. explained_variance_ratio_ , decimals= 4 )* 100 )
array([69.83, 89.35, 95.88, 98.95, 99.99])
အောက်ပါတို့ကို ကျွန်ုပ်တို့ မြင်နိုင်သည်-
- ပထမ အဓိက အစိတ်အပိုင်းကို အသုံးပြု၍ တုံ့ပြန်မှု ကိန်းရှင်တွင် ကွဲလွဲမှု 69.83% ကို ရှင်းပြနိုင်ပါသည်။
- ဒုတိယ အဓိက အစိတ်အပိုင်းကို ပေါင်းထည့်ခြင်းဖြင့် တုံ့ပြန်မှု ကိန်းရှင်တွင် ကွဲလွဲမှု 89.35% ကို ရှင်းပြနိုင်ပါသည်။
ကျွန်ုပ်တို့သည် အဓိကအစိတ်အပိုင်းများကို အသုံးပြုခြင်းဖြင့် ပိုမိုကွဲပြားမှုကို ရှင်းပြနိုင်ဆဲဖြစ်သည်ကို သတိပြုပါ၊ သို့သော် အဓိကအစိတ်အပိုင်းနှစ်ခုထက်ပိုထည့်ခြင်းသည် ရှင်းပြထားသည့်ကွဲလွဲမှုရာခိုင်နှုန်းကို အမှန်တကယ်တိုးပွားစေမည်မဟုတ်ကြောင်း သတိပြုပါ။
အဆင့် 4- ခန့်မှန်းချက်များကို ပြုလုပ်ရန် နောက်ဆုံးပုံစံကို အသုံးပြုပါ။
လေ့လာတွေ့ရှိချက်အသစ်များနှင့်ပတ်သက်၍ ခန့်မှန်းချက်များပြုလုပ်ရန် နောက်ဆုံးအဓိကအစိတ်အပိုင်းနှစ်ခု PCR မော်ဒယ်ကို ကျွန်ုပ်တို့အသုံးပြုနိုင်ပါသည်။
အောက်ပါကုဒ်သည် မူရင်းဒေတာအစုံကို လေ့ကျင့်ရေးနှင့် စမ်းသပ်မှုအဖြစ် ပိုင်းခြားပုံပြသပြီး စမ်းသပ်မှုအစုတွင် ခန့်မှန်းချက်များပြုလုပ်ရန် အဓိကအစိတ်အပိုင်းနှစ်ခုပါရှိသော PCR မော်ဒယ်ကို အသုံးပြုပါ။
#split the dataset into training (70%) and testing (30%) sets
X_train,X_test,y_train,y_test = train_test_split (X,y,test_size= 0.3 , random_state= 0 )
#scale the training and testing data
X_reduced_train = pca. fit_transform ( scale (X_train))
X_reduced_test = pca. transform ( scale (X_test))[:,:1]
#train PCR model on training data
regr = LinearRegression()
reg. fit (X_reduced_train[:,:1], y_train)
#calculate RMSE
pred = regr. predict (X_reduced_test)
n.p. sqrt ( mean_squared_error (y_test, pred))
40.2096
RMSE စစ်ဆေးမှုသည် 40.2096 ဖြစ်သည်ကို ကျွန်ုပ်တို့မြင်ရသည်။ ၎င်းသည် ခန့်မှန်းထားသော hp တန်ဖိုးနှင့် စမ်းသပ်မှုအစုအဝေးအတွက် လေ့လာတွေ့ရှိထားသော hp တန်ဖိုးကြား ပျမ်းမျှသွေဖည်မှုဖြစ်သည်။
ဤဥပမာတွင်အသုံးပြုထားသော Python ကုဒ်အပြည့်အစုံကို ဤနေရာတွင် တွေ့နိုင်ပါသည်။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။