R တွင် မတူကွဲပြားသော ခွဲခြမ်းစိတ်ဖြာမှုကို မည်သို့လုပ်ဆောင်ရမည်နည်း (ဥပမာများဖြင့်)
univariate analysis ဟူသော ဝေါဟာရသည် ကိန်းရှင်တစ်ခု၏ ခွဲခြမ်းစိတ်ဖြာမှုကို ရည်ညွှန်းသည်။ ရှေ့ဆက် “ uni” သည် “ one” ဖြစ်သောကြောင့်၎င်းကိုသင်မှတ်မိနိုင်သည်။
ကိန်းရှင်တစ်ခုပေါ်တွင် တစ်မူထူးခြားသော ခွဲခြမ်းစိတ်ဖြာမှုကို လုပ်ဆောင်ရန် ဘုံနည်းလမ်းသုံးမျိုးရှိပါသည်။
1. အကျဉ်းချုပ်စာရင်းအင်းများ – တန်ဖိုးများကို ဗဟိုချက်နှင့် ဖြန့်ဖြူးမှုကို တိုင်းတာသည်။
2. ကြိမ်နှုန်းဇယား – မတူညီသောတန်ဖိုးများ မည်မျှပေါ်လာသည်ကို ဖော်ပြသည်။
3. ဇယားများ – တန်ဖိုးများ ဖြန့်ဖြူးမှုကို မြင်သာစေရန် အသုံးပြုသည်။
ဤသင်ခန်းစာသည် အောက်ဖော်ပြပါ variable အတွက် univariate ခွဲခြမ်းစိတ်ဖြာနည်းကို ဥပမာပေးပါသည်။
#create variable with 15 values
x <- c(1, 1, 2, 3.5, 4, 4, 4, 5, 5, 6.5, 7, 7.4, 8, 13, 14.2)
စာရင်းဇယားအကျဉ်းချုပ်
ကျွန်ုပ်တို့၏ variable အတွက် အမျိုးမျိုးသော အနှစ်ချုပ်ကိန်းဂဏန်းများကို တွက်ချက်ရန် အောက်ပါ syntax ကို အသုံးပြုနိုင်ပါသည်။
#find means mean(x) [1] 5.706667 #find median median(x) [1] 5 #find range max(x) - min(x) [1] 13.2 #find interquartile range (spread of middle 50% of values) IQR(x) [1] 3.45 #find standard deviation sd(x) [1] 3.858287
ကြိမ်နှုန်းဇယား
ကျွန်ုပ်တို့၏ variable အတွက် ကြိမ်နှုန်းဇယားကို ထုတ်လုပ်ရန် အောက်ပါ syntax ကို အသုံးပြုနိုင်ပါသည်။
#produce frequency table
table(s)
1 2 3.5 4 5 6.5 7 7.4 8 13 14.2
2 1 1 3 2 1 1 1 1 1 1
၎င်းသည် ကျွန်ုပ်တို့အား ပြောပြသည်-
- တန်ဖိုး 1 သည် နှစ်ခါပေါ်လာသည်။
- တန်ဖိုး 2 သည် 1 ကြိမ်ပေါ်လာသည်။
- တန်ဖိုး 3.5 သည် 1 ကြိမ်ပေါ်လာသည်။
နောက် … ပြီးတော့။
ဂရပ်ဖစ်
အောက်ပါ syntax ကို အသုံးပြု၍ boxplot တစ်ခုကို ထုတ်လုပ်နိုင်သည်။
#produce boxplot
boxplot(x)
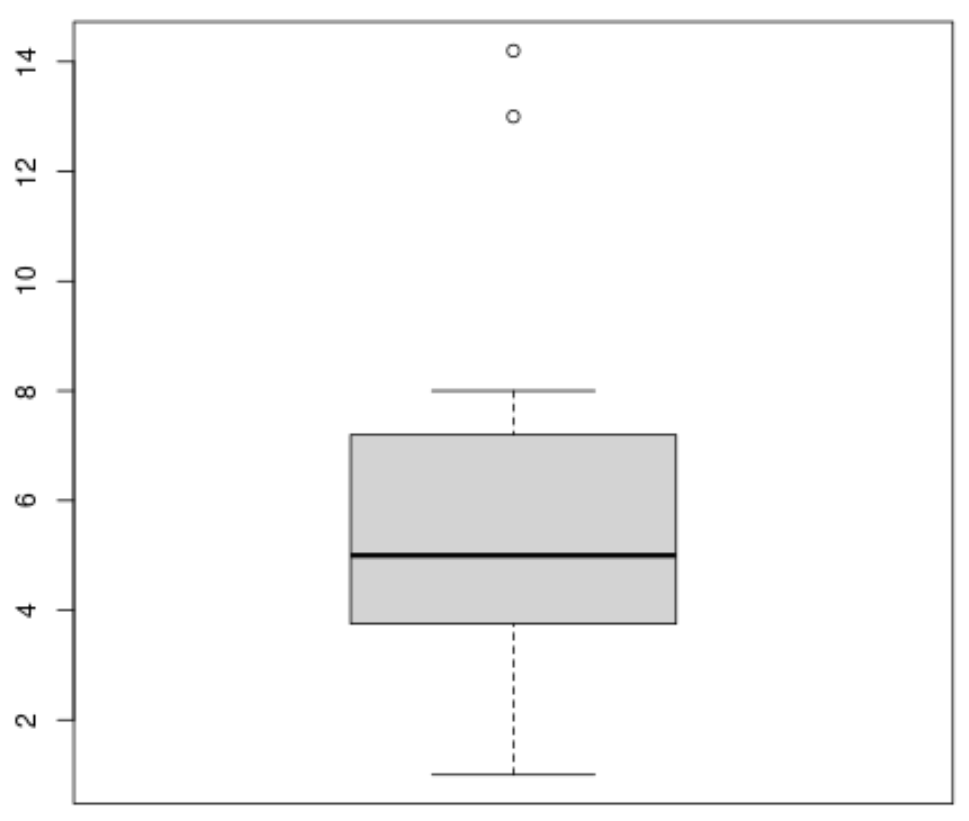
အောက်ပါအထားအသိုကို အသုံးပြု၍ ကျွန်ုပ်တို့သည် ဟီစတိုဂရမ်တစ်ခုကို ထုတ်လုပ်နိုင်သည်-
#produce histogram
hist(x)
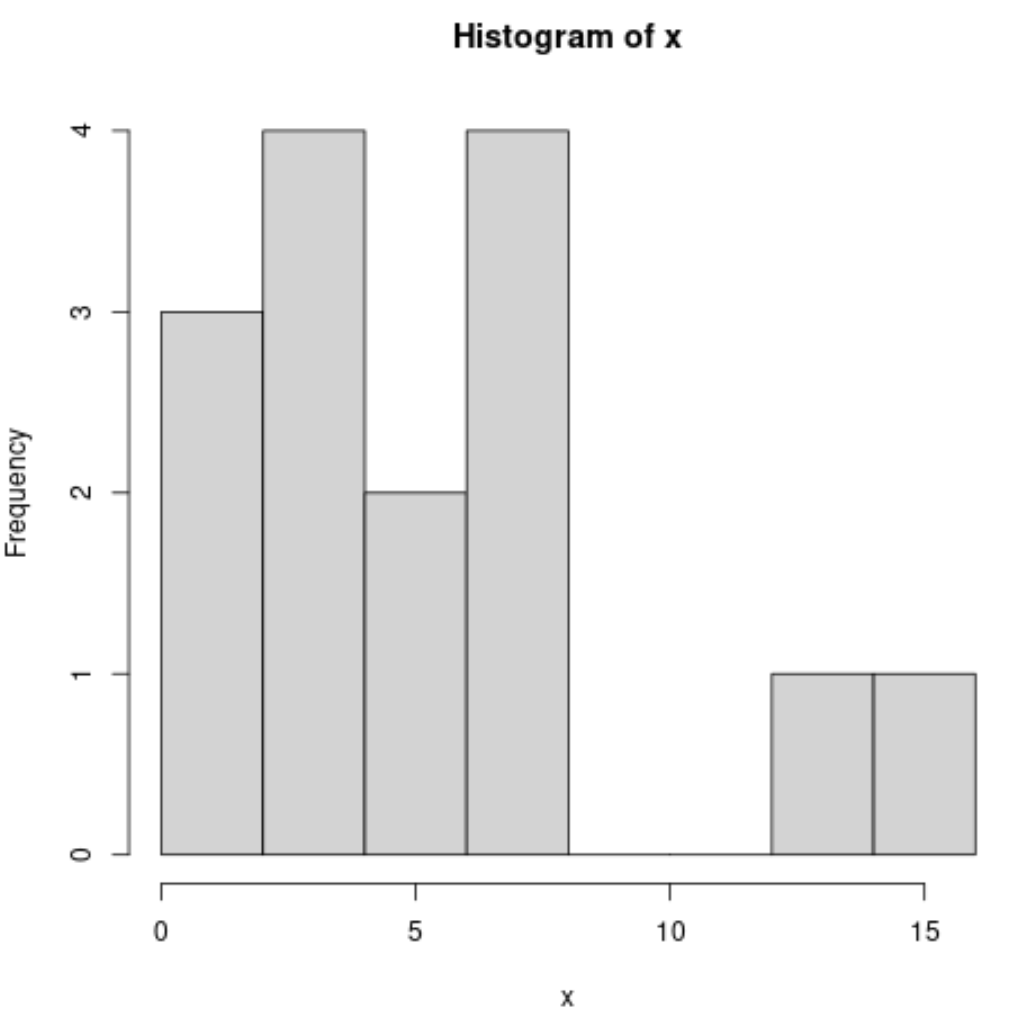
အောက်ဖော်ပြပါ syntax ကို အသုံးပြု၍ သိပ်သည်းဆမျဉ်းကွေးကို ထုတ်လုပ်နိုင်သည်-
#produce density curve
plot(density(x))
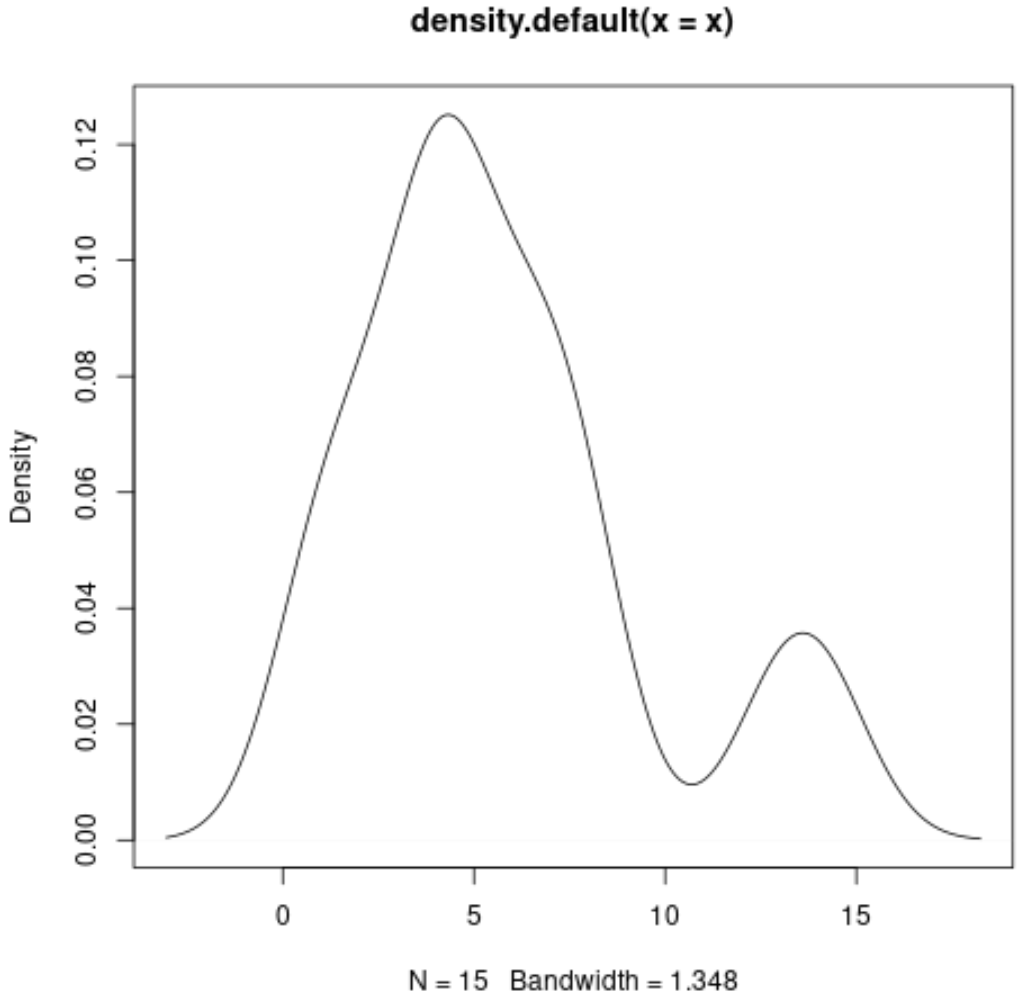
ဤဂရပ်များတစ်ခုစီသည် ကျွန်ုပ်တို့အား ကျွန်ုပ်တို့၏ variable ၏တန်ဖိုးများဖြန့်ဖြူးမှုကို မြင်သာစေရန် ထူးခြားသောနည်းလမ်းကိုပေးပါသည်။
နောက်ထပ် R သင်ခန်းစာများကို ဤစာမျက်နှာတွင် သင်တွေ့နိုင်ပါသည်။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။