R တွင် ပုံမှန်ဖြန့်ဝေနည်း (ဥပမာများဖြင့်)
အောက်ပါ syntax ကိုအသုံးပြုသည့် rnorm() လုပ်ဆောင်ချက်ကို အသုံးပြု၍ R တွင် ပုံမှန်ဖြန့်ဝေမှုကို လျင်မြန်စွာ ဖန်တီးနိုင်သည်-
rnorm(n, mean=0, sd=1)
ရွှေ-
- n- လေ့လာတွေ့ရှိချက်အရေအတွက်။
- ဆိုလိုသည်မှာ- ပုံမှန်ဖြန့်ဖြူးမှု၏ပျမ်းမျှ။ မူရင်းတန်ဖိုးသည် 0 ဖြစ်သည်။
- sd- ပုံမှန်ဖြန့်ဖြူးမှု၏ စံသွေဖည်မှု။ မူရင်းတန်ဖိုးမှာ 1 ဖြစ်သည်။
ဤသင်ခန်းစာတွင် R တွင် ပုံမှန်ဖြန့်ဝေမှုတစ်ခုကို ဖန်တီးရန် ဤလုပ်ဆောင်ချက်ကို အသုံးပြုခြင်း၏ ဥပမာကို ပြသထားသည်။
ဆက်စပ်- R တွင် dnorm၊ pnorm၊ qnorm နှင့် rnorm လမ်းညွှန်
ဥပမာ- R ဖြင့် ပုံမှန်ဖြန့်ဖြူးမှုကို ဖန်တီးခြင်း။
အောက်ဖော်ပြပါ ကုဒ်သည် R တွင် ပုံမှန်ဖြန့်ဝေမှုတစ်ခုကို မည်သို့ထုတ်လုပ်ရမည်ကို ပြသသည်-
#make this example reproducible set.seed(1) #generate sample of 200 obs. that follows normal dist. with mean=10 and sd=3 data <- rnorm(200, mean=10, sd=3) #view first 6 observations in sample head(data) [1] 8.120639 10.550930 7.493114 14.785842 10.988523 7.538595
ဤဖြန့်ဖြူးမှု၏ ပျမ်းမျှနှင့် စံသွေဖည်မှုကို လျင်မြန်စွာ တွေ့ရှိနိုင်သည်-
#find mean of sample
mean(data)
[1] 10.10662
#find standard deviation of sample
sd(data)
[1] 2.787292
ဒေတာတန်ဖိုးများ ဖြန့်ဖြူးမှုကို မြင်သာစေရန် အမြန် histogram တစ်ခုကိုလည်း ဖန်တီးနိုင်သည်-
hist(data, col=' steelblue ')
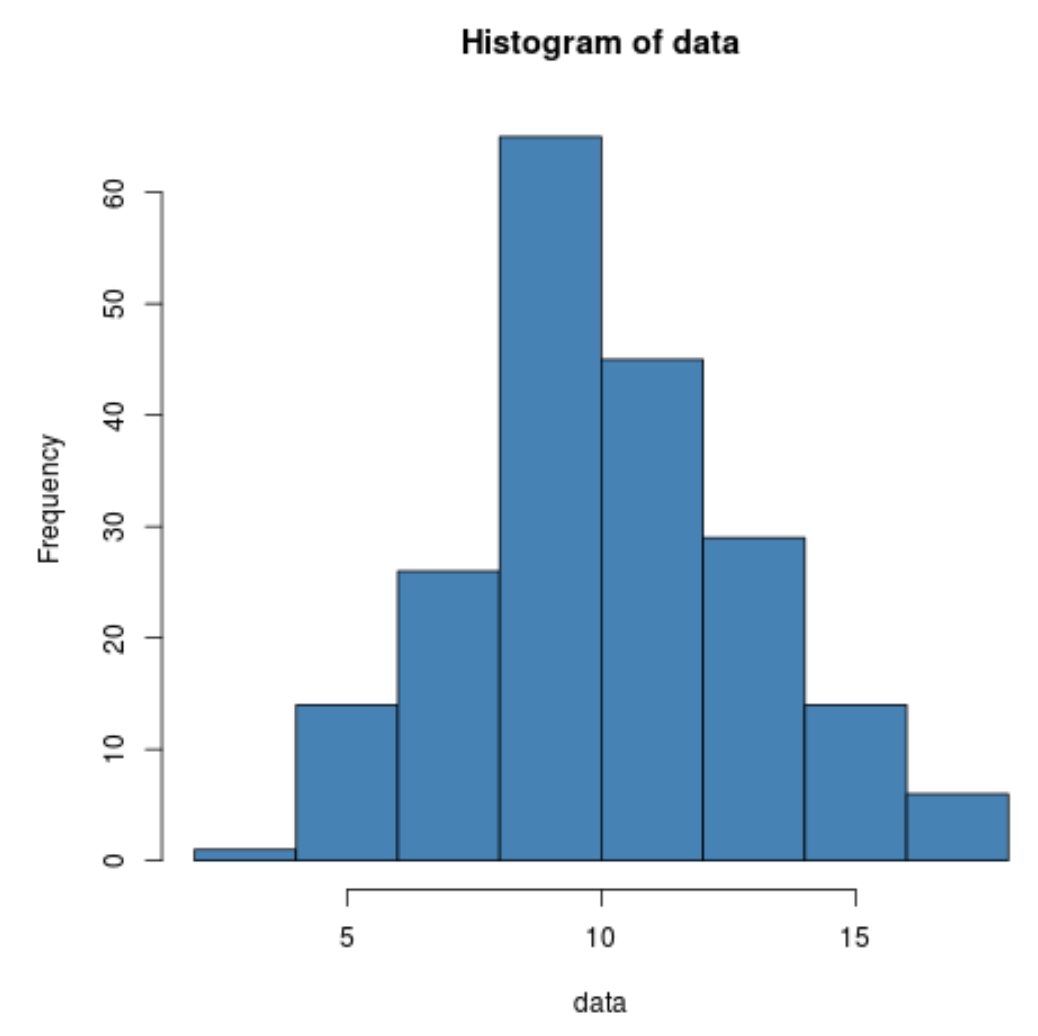
ဒေတာအတွဲသည် သာမန်လူဦးရေမှ ဆင်းသက်ခြင်းရှိ၊ မရှိ စစ်ဆေးရန် Shapiro-Wilk စမ်းသပ်မှုကို ပင် လုပ်ဆောင်နိုင်သည်-
shapiro.test(data)
Shapiro-Wilk normality test
data:data
W = 0.99274, p-value = 0.4272
စမ်းသပ်မှု၏ p-တန်ဖိုးသည် 0.4272 ဖြစ်လာသည်။ ဤတန်ဖိုးသည် 0.05 ထက်မနည်းသောကြောင့်၊ နမူနာဒေတာသည် ပုံမှန်ဖြန့်ဝေထားသော လူဦးရေမှလာသည်ဟု ကျွန်ုပ်တို့ ယူဆနိုင်ပါသည်။
rnorm() လုပ်ဆောင်ချက်ကို အသုံးပြု၍ ဒေတာကို ပုံမှန်ဖြန့်ဝေခြင်းမှ ဒေတာ၏ ကျပန်းနမူနာကို သဘာဝအတိုင်း ထုတ်လုပ်ပေးသောကြောင့် ဤရလဒ်သည် အံ့သြစရာမဟုတ်ပါ။
ထပ်လောင်းအရင်းအမြစ်များ
R ဖြင့် ပုံမှန်ဖြန့်ဖြူးနည်း
R တွင် dnorm၊ pnorm၊ qnorm နှင့် rnorm လမ်းညွှန်
R တွင်ပုံမှန်ဖြစ်ရန်အတွက် Shapiro-Wilk စမ်းသပ်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။