R တွင် တစ်စိတ်တစ်ပိုင်း အနည်းဆုံးစတုရန်းများ (တစ်ဆင့်ပြီးတစ်ဆင့်)
machine learning တွင် သင်ကြုံတွေ့ရမည့် အဖြစ်များဆုံး ပြဿနာတစ်ခုမှာ multicollinearity ဖြစ်သည်။ ဒေတာအတွဲတစ်ခုရှိ ကြိုတင်ခန့်မှန်းကိန်းရှင် နှစ်ခု သို့မဟုတ် ထို့ထက်ပိုသော ကိန်းရှင်များသည် အလွန်ဆက်စပ်နေသောအခါ ၎င်းသည် ဖြစ်ပေါ်သည်။
ထိုသို့ဖြစ်လာသောအခါ မော်ဒယ်တစ်ခုသည် လေ့ကျင့်ရေးဒေတာအစုံကို ကောင်းစွာအံဝင်ခွင်ကျနိုင်သော်လည်း ၎င်းသည် လေ့ကျင့်ရေးဒေတာအစုံ နှင့် ကိုက်ညီသော ကြောင့် မမြင်ဖူးသော ဒေတာအတွဲအသစ်တွင် ညံ့ဖျင်းစွာလုပ်ဆောင်နိုင်မည်ဖြစ်သည်။ လေ့ကျင့်ရေးအစုံ။
ဤပြဿနာကို ဖြေရှင်းရန် နည်းလမ်းတစ်ခုမှာ အောက်ပါအတိုင်း လုပ်ဆောင်နိုင်သော partial least squares ဟုခေါ်သော နည်းလမ်းကို အသုံးပြုခြင်းဖြစ်သည်၊
- ခန့်မှန်းသူနှင့် တုံ့ပြန်မှုကိန်းရှင်များကို စံသတ်မှတ်ပါ။
- တုံ့ပြန်မှုကိန်းရှင်နှင့် ကြိုတင်ခန့်မှန်းကိန်းရှင်များ နှစ်ခုလုံးတွင် သိသာထင်ရှားသောပြောင်းလဲမှုပမာဏကို ရှင်းပြသည့် p မူလကြိုတင်ခန့်မှန်းကိန်းရှင် များ၏ M linear ပေါင်းစပ်မှုများ (“ PLS အစိတ်အပိုင်းများ” ) ကို တွက်ချက်ပါ ။
- ခန့်မှန်းချက်များအဖြစ် PLS အစိတ်အပိုင်းများကို အသုံးပြု၍ မျဉ်းကြောင်းဆုတ်ယုတ်မှုပုံစံနှင့်ကိုက်ညီရန် အနည်းဆုံးစတုရန်းနည်းလမ်းကိုသုံးပါ။
- မော်ဒယ်တွင် ထားရှိရန် အကောင်းဆုံး PLS အစိတ်အပိုင်းများကို ရှာဖွေရန် k-fold အပြန်အလှန် validation ကို သုံးပါ ။
ဤသင်ခန်းစာသည် R တွင် တစ်စိတ်တစ်ပိုင်း အနည်းဆုံးစတုရန်းများကို မည်သို့လုပ်ဆောင်ရမည်ကို အဆင့်ဆင့် ဥပမာပေးထားသည်။
အဆင့် 1- လိုအပ်သော ပက်ကေ့ခ်ျများကို တင်ပါ။
R တွင် တစ်စိတ်တစ်ပိုင်း အနည်းဆုံးစတုရန်းများကို လုပ်ဆောင်ရန် အလွယ်ဆုံးနည်းလမ်းမှာ pls package အတွင်းရှိ လုပ်ဆောင်ချက်များကို အသုံးပြုရန်ဖြစ်သည်။
#install pls package (if not already installed) install.packages(" pls ") load pls package library(pls)
အဆင့် 2- တစ်စိတ်တစ်ပိုင်း အနည်းဆုံး စတုရန်းပုံစံကို ကွက်တိပါ။
ဤဥပမာအတွက်၊ ကျွန်ုပ်တို့သည် ကားအမျိုးအစားအမျိုးမျိုးတွင် ဒေတာပါရှိသော mtcars ဟုခေါ်သော တပ်ဆင်ထားသည့် R ဒေတာအစုံကို အသုံးပြုပါမည်-
#view first six rows of mtcars dataset
head(mtcars)
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3,460 20.22 1 0 3 1
ဤဥပမာအတွက်၊ ကျွန်ုပ်တို့သည် တုံ့ပြန်မှုကိန်းရှင် အဖြစ် hp ကို အသုံးပြုကာ တစ်စိတ်တစ်ပိုင်းအနည်းဆုံးစတုရန်းများ (PLS) မော်ဒယ်နှင့် အံဝင်ခွင်ကျဖြစ်နိုင်သော ကိန်းရှင်များအဖြစ် အောက်ပါကိန်းရှင်များကို ဖြည့်ဆည်းပေးပါမည်။
- စိုင်းစိုင်းခမ်းလှိုင်
- ပြသခြင်း။
- ပြောရမှာပါ။
- ကိုယ်အလေးချိန်
- qsec
အောက်ပါ ကုဒ်သည် ဤဒေတာနှင့် PLS မော်ဒယ်ကို မည်သို့ အံဝင်ခွင်ကျ ဖြစ်စေရန် ဖော်ပြသည်။ အောက်ပါအငြင်းပွားမှုများကို သတိပြုပါ။
- scale=TRUE : ဒေတာအတွဲရှိ ကိန်းရှင်တစ်ခုစီကို 0 နှင့် 1 ၏ စံသွေဖည်မှုရှိရန် အတိုင်းအတာတစ်ခုစီကို ချိန်ညှိသင့်သည်ဟု R အားပြောပြသည်။ ၎င်းသည် မတူညီသောယူနစ်များဖြင့် တိုင်းတာပါက မော်ဒယ်တွင် ကိန်းဂဏန်းအလွန်အကျွံလွှမ်းမိုးမှုမရှိကြောင်း သေချာစေသည်။
- validation=”CV” – မော်ဒယ်စွမ်းဆောင်ရည်ကိုအကဲဖြတ်ရန် R သည် k-fold cross validation ကို အသုံးပြုရန်ပြောထားသည်။ ၎င်းသည် ပုံမှန်အားဖြင့် k=10 ခေါက်ကို အသုံးပြုကြောင်း သတိပြုပါ။ Leave-One-Out cross-validation လုပ်ဆောင်ရန် “ LOOCV” ကို သင် သတ်မှတ်နိုင်သည်ကိုလည်း သတိပြုပါ။
#make this example reproducible set.seed(1) #fit PCR model model <- plsr(hp~mpg+disp+drat+wt+qsec, data=mtcars, scale= TRUE , validation=" CV ")
အဆင့် 3: PLS အစိတ်အပိုင်းများ အရေအတွက်ကို ရွေးချယ်ပါ။
မော်ဒယ်ကို တပ်ဆင်ပြီးသည်နှင့် PLS အစိတ်အပိုင်း မည်မျှထားရှိရန် ဆုံးဖြတ်ရန် လိုအပ်သည်။
ဒါကိုလုပ်ဖို့၊ k-cross validation ဖြင့်တွက်ချက်ထားသော test root mean square error (test RMSE) ကိုကြည့်ပါ-
#view summary of model fitting
summary(model)
Data:
Y dimension: 32 1
Fit method: kernelpls
Number of components considered: 5
VALIDATION: RMSEP
Cross-validated using 10 random segments.
(Intercept) 1 comp 2 comps 3 comps 4 comps 5 comps
CV 69.66 40.57 35.48 36.22 36.74 36.67
adjCV 69.66 40.41 35.12 35.80 36.27 36.20
TRAINING: % variance explained
1 comp 2 comps 3 comps 4 comps 5 comps
X 68.66 89.27 95.82 97.94 100.00
hp 71.84 81.74 82.00 82.02 82.03
ရလဒ်တွင် စိတ်ဝင်စားစရာကောင်းသော ဇယားနှစ်ခုရှိသည်။
1. တရားဝင်- RMSEP
ဤဇယားသည် k-fold cross validation ဖြင့်တွက်ချက်ထားသော RMSE စာမေးပွဲကိုပြောပြသည်။ အောက်ပါတို့ကို ကျွန်ုပ်တို့ မြင်နိုင်သည်-
- မော်ဒယ်တွင် မူရင်းအခေါ်အဝေါ်ကိုသာ အသုံးပြုပါက၊ စမ်းသပ်မှု၏ RMSE သည် 69.66 ဖြစ်သည်။
- ကျွန်ုပ်တို့သည် ပထမ PLS အစိတ်အပိုင်းကို ထည့်ပါက၊ RMSE စမ်းသပ်မှုသည် 40.57 သို့ကျဆင်းသွားသည်။
- ကျွန်ုပ်တို့သည် ဒုတိယ PLS အစိတ်အပိုင်းကို ထည့်ပါက RMSE စမ်းသပ်မှုသည် 35.48 သို့ ကျဆင်းသွားသည်။
အပိုဆောင်း PLS အစိတ်အပိုင်းများကို ပေါင်းထည့်ခြင်းသည် စမ်းသပ်မှု၏ RMSE တိုးလာကြောင်း ကျွန်ုပ်တို့တွေ့မြင်နိုင်ပါသည်။ ထို့ကြောင့် နောက်ဆုံးမော်ဒယ်တွင် PLS အစိတ်အပိုင်းနှစ်ခုကိုသာ အသုံးပြုခြင်းသည် အကောင်းဆုံးဖြစ်ဟန်တူသည်။
2. လေ့ကျင့်ရေး- ကွဲလွဲမှု % ကို ရှင်းပြသည်။
ဤဇယားသည် PLS အစိတ်အပိုင်းများဖြင့် ရှင်းပြထားသော တုံ့ပြန်မှုကိန်းရှင်တွင် ကွဲလွဲမှုရာခိုင်နှုန်းကို ပြောပြသည်။ အောက်ပါတို့ကို ကျွန်ုပ်တို့ မြင်နိုင်သည်-
- ပထမ PLS အစိတ်အပိုင်းကိုသာ အသုံးပြု၍ တုံ့ပြန်မှု variable တွင် ကွဲလွဲမှု 68.66% ကို ရှင်းပြနိုင်ပါသည်။
- ဒုတိယ PLS အစိတ်အပိုင်းကို ပေါင်းထည့်ခြင်းဖြင့် တုံ့ပြန်မှု variable တွင် ကွဲလွဲမှု 89.27% ကို ရှင်းပြနိုင်သည်။
PLS အစိတ်အပိုင်းများကို ပိုမိုအသုံးပြုခြင်းဖြင့် ကျွန်ုပ်တို့သည် ပိုမိုကွဲပြားမှုကို ရှင်းပြနိုင်ဆဲဖြစ်သည်ကို သတိပြုပါ၊ သို့သော် PLS အစိတ်အပိုင်းနှစ်ခုထက်ပိုထည့်ခြင်းသည် များစွာအားဖြင့် ရှင်းပြထားသော ကွဲလွဲမှုရာခိုင်နှုန်းကို အမှန်တကယ်မတိုးကြောင်း သတိပြုပါ။
validationplot() လုပ်ဆောင်ချက်ကို အသုံးပြု၍ PLS အစိတ်အပိုင်းများ အရေအတွက်၏ လုပ်ဆောင်ချက်အဖြစ် RMSE စာမေးပွဲ (MSE နှင့် R-squared စမ်းသပ်မှုနှင့်အတူ) ကို မြင်ယောင်နိုင်သည်။
#visualize cross-validation plots validationplot(model) validationplot(model, val.type=" MSEP ") validationplot(model, val.type=" R2 ")
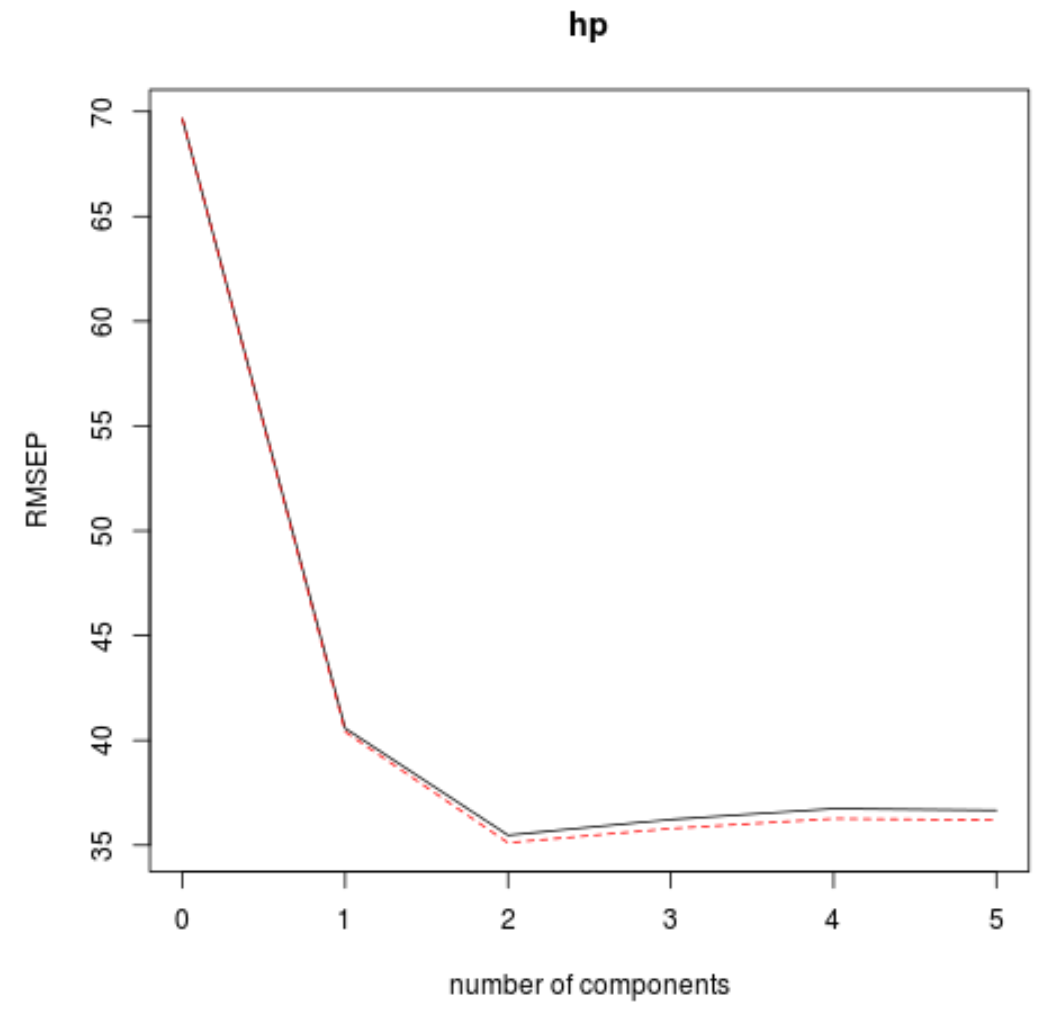
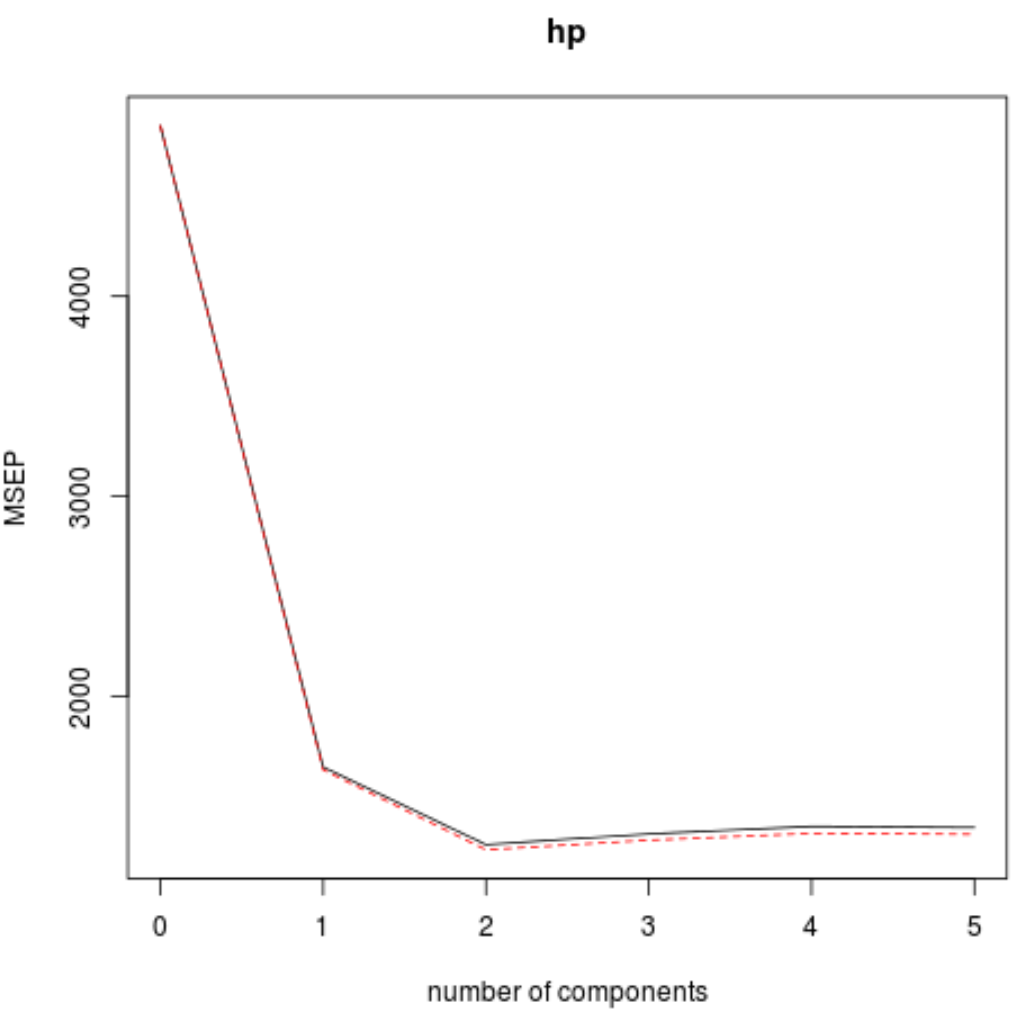
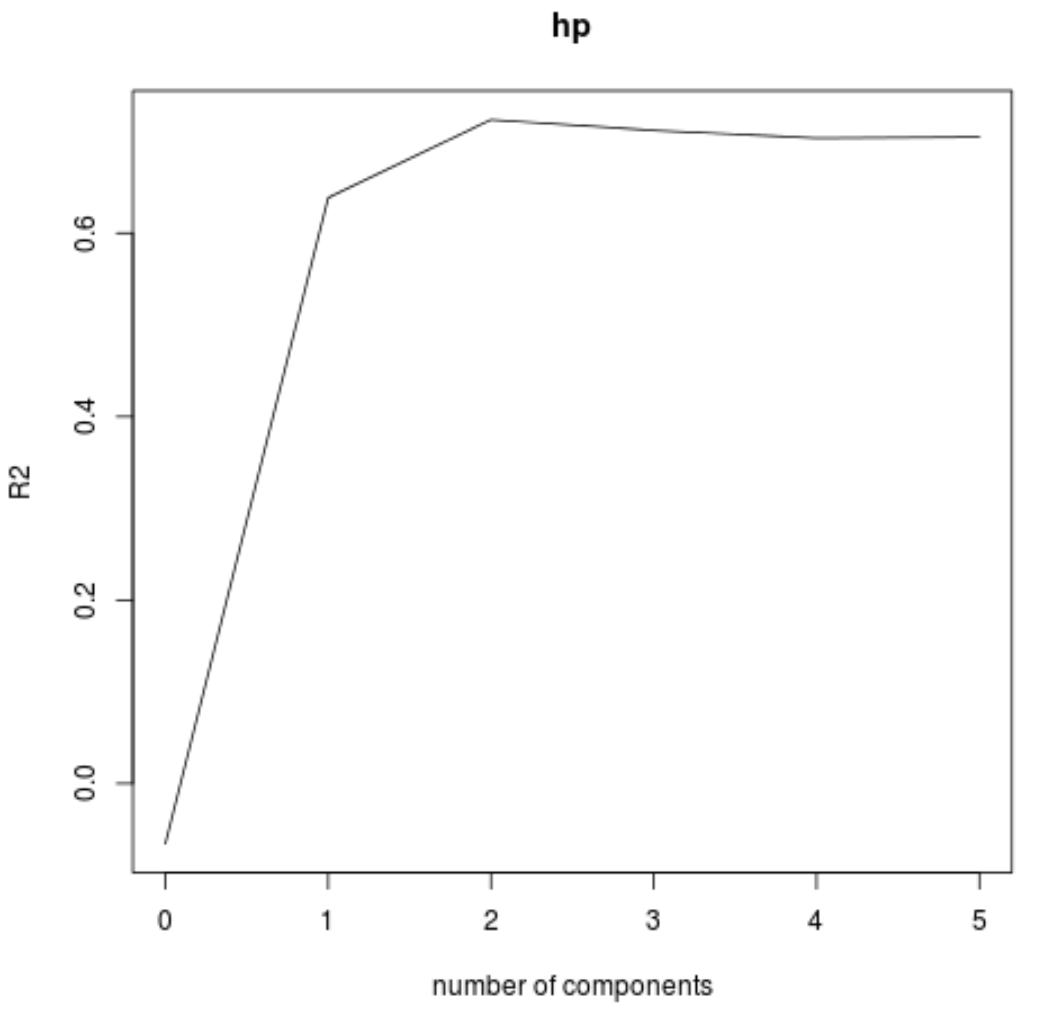
ဂရပ်တစ်ခုစီတွင်၊ PLS အစိတ်အပိုင်းနှစ်ခုကို ပေါင်းထည့်ခြင်းဖြင့် မော်ဒယ်သည် အံဝင်ခွင်ကျဖြစ်နေသည်ကို ကျွန်ုပ်တို့တွေ့မြင်နိုင်သော်လည်း PLS အစိတ်အပိုင်းများကို ထပ်ထည့်သောအခါတွင် ယိုယွင်းသွားတတ်သည်။
ထို့ကြောင့် အကောင်းဆုံးမော်ဒယ်တွင် ပထမ PLS အစိတ်အပိုင်းနှစ်ခုသာ ပါဝင်ပါသည်။
အဆင့် 4- ခန့်မှန်းချက်များကို ပြုလုပ်ရန် နောက်ဆုံးပုံစံကို အသုံးပြုပါ။
လေ့လာတွေ့ရှိချက်အသစ်များနှင့်ပတ်သက်၍ ခန့်မှန်းချက်များပြုလုပ်ရန် PLS အစိတ်အပိုင်းနှစ်ခုပါသည့် နောက်ဆုံးမော်ဒယ်ကို ကျွန်ုပ်တို့အသုံးပြုနိုင်ပါသည်။
အောက်ပါကုဒ်သည် မူရင်းဒေတာအစုံကို လေ့ကျင့်ရေးနှင့် စမ်းသပ်မှုအဖြစ် ပိုင်းခြားပုံပြသပြီး စမ်းသပ်မှုအစီအစဉ်တွင် ခန့်မှန်းချက်များပြုလုပ်ရန် PLS အစိတ်အပိုင်းနှစ်ခုဖြင့် နောက်ဆုံးမော်ဒယ်ကို အသုံးပြုပါ။
#define training and testing sets train <- mtcars[1:25, c("hp", "mpg", "disp", "drat", "wt", "qsec")] y_test <- mtcars[26: nrow (mtcars), c("hp")] test <- mtcars[26: nrow (mtcars), c("mpg", "disp", "drat", "wt", "qsec")] #use model to make predictions on a test set model <- plsr(hp~mpg+disp+drat+wt+qsec, data=train, scale= TRUE , validation=" CV ") pcr_pred <- predict(model, test, ncomp= 2 ) #calculate RMSE sqrt ( mean ((pcr_pred - y_test)^2)) [1] 54.89609
စာမေးပွဲ၏ RMSE သည် 54.89609 ဖြစ်သွားသည်ကို ကျွန်ုပ်တို့မြင်ရသည်။ ၎င်းသည် ခန့်မှန်းထားသော hp တန်ဖိုးနှင့် စမ်းသပ်မှုအစုအဝေးအတွက် လေ့လာတွေ့ရှိထားသော hp တန်ဖိုးကြား ပျမ်းမျှသွေဖည်မှုဖြစ်သည်။
အဓိကအစိတ်အပိုင်းနှစ်ခုပါသော တူညီသောအဓိကအစိတ်အပိုင်းများဆုတ်ယုတ်မှုပုံစံသည် စမ်းသပ်မှု RMSE 56.86549 ကိုထုတ်ပေးကြောင်း သတိပြုပါ။ ထို့ကြောင့် PLS မော်ဒယ်သည် ဤဒေတာအတွဲအတွက် PCR မော်ဒယ်ထက် အနည်းငယ်သာလွန်သည်။
ဤဥပမာတွင် R ကုဒ်၏ အပြည့်အဝအသုံးပြုမှုကို ဤနေရာတွင် တွေ့နိုင်ပါသည်။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။