R တွင် ဗဟိုကန့်သတ်သီအိုရီကို မည်ကဲ့သို့ကျင့်သုံးရမည်နည်း (ဥပမာများဖြင့်)
လူဦးရေ ဖြန့်ဝေမှုသည် ပုံမှန်မဟုတ်သော်လည်း နမူနာအရွယ်အစား လုံလောက်စွာကြီးမားပါက နမူနာ၏ နမူနာဖြန့်ဝေမှုသည် ပုံမှန်မဟုတ်ကြောင်း ဗဟိုကန့်သတ်သီအိုရီက ဖော်ပြသည်။
ဗဟိုကန့်သတ်သီအိုရီတွင်လည်း နမူနာဖြန့်ဝေမှုတွင် အောက်ပါဂုဏ်သတ္တိများ ပါလိမ့်မည်-
1. နမူနာဖြန့်ဝေမှု၏ပျမ်းမျှသည် လူဦးရေဖြန့်ဖြူးမှု၏ပျမ်းမျှနှင့် ညီမျှသည်-
x = µ
2. နမူနာ ဖြန့်ဝေမှု၏ စံသွေဖည်မှုသည် နမူနာအရွယ်အစားဖြင့် ပိုင်းခြားထားသော လူဦးရေ ဖြန့်ဖြူးမှု၏ စံသွေဖည်မှုနှင့် ညီမျှသည်-
s = σ / n
အောက်ဖော်ပြပါ ဥပမာသည် R တွင် ဗဟိုကန့်သတ်သီအိုရီကို မည်သို့အသုံးပြုရမည်ကို ပြသထားသည်။
ဥပမာ- R တွင် ဗဟိုကန့်သတ်သီအိုရီကို အသုံးပြုခြင်း။
လိပ်ခွံ၏ အကျယ်သည် အနိမ့်ဆုံးအကျယ် 2 လက်မ နှင့် အများဆုံး အကျယ် 6 လက်မ ရှိသော ယူနီဖောင်း ဖြန့်ချီမှု နောက်တွင် ဆိုပါစို့။
ဆိုလိုသည်မှာ၊ ကျွန်ုပ်တို့သည် ကျပန်းရွေးချယ်ပြီး ၎င်း၏အခွံ၏အကျယ်ကို တိုင်းတာပါက၊ ၎င်းသည် အကျယ် 2 လက်မမှ 6 လက်မကြားရှိနိုင်သည်။
အောက်ဖော်ပြပါ ကုဒ်သည် လိပ် 1,000 ၏ carapace အကျယ်ကို တိုင်းတာမှုများပါရှိသော R တွင် ဒေတာအစုံကို ဖန်တီးနည်းကို ပြသထားပြီး 2 နှင့် 6 လက်မအကြား အညီအမျှ ဖြန့်ဝေသည်-
#make this example reproducible
set. seeds (0)
#create random variable with sample size of 1000 that is uniformly distributed
data <- runif(n=1000, min=2, max=6)
#create histogram to visualize distribution of turtle shell widths
hist(data, col=' steelblue ', main=' Histogram of Turtle Shell Widths ')
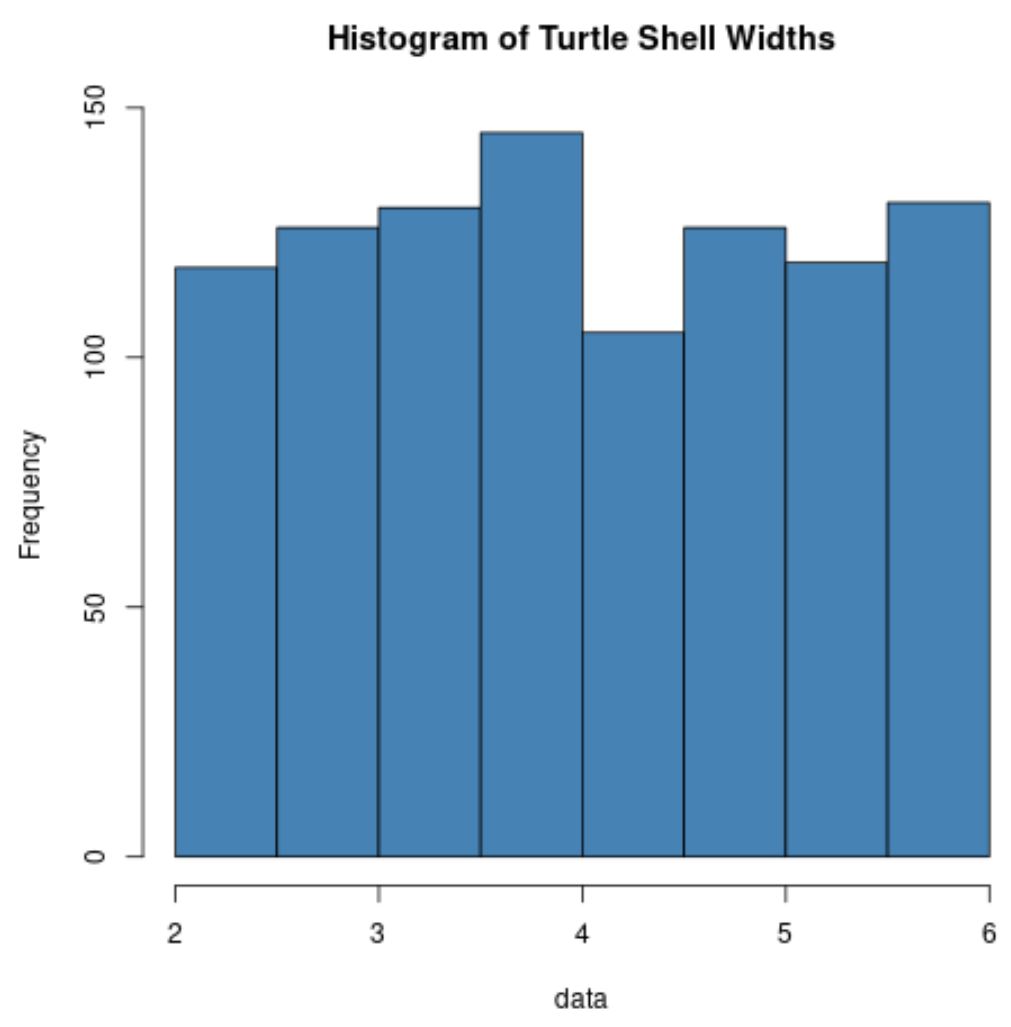
လိပ်ခွံအကျယ်များကို ပုံမှန်အားဖြင့် ဖြန့်ဝေခြင်း လုံးဝမရှိကြောင်း သတိပြုပါ။
ယခု ကျွန်ုပ်တို့သည် ဤလူဦးရေမှ လိပ် 5 ကောင်၏ ကျပန်းနမူနာများကို ယူ၍ နမူနာ ဆိုလိုချက်ကို ထပ်ခါထပ်ခါ တိုင်းတာကြည့်ရန် စိတ်ကူးကြည့်ပါ။
အောက်ဖော်ပြပါ ကုဒ်သည် ဤလုပ်ငန်းစဉ်ကို R တွင် မည်သို့လုပ်ဆောင်ရမည်ကို ပြသပြီး နမူနာ၏ ဖြန့်ဖြူးမှုကို မြင်သာစေရန် ဟစ်စတိုဂရမ်ကို ဖန်တီးသည်-
#create empty vector to hold sample means
sample5 <- c()
#take 1,000 random samples of size n=5
n = 1000
for (i in 1:n){
sample5[i] = mean(sample(data, 5, replace= TRUE ))
}
#calculate mean and standard deviation of sample means
mean(sample5)
[1] 4.008103
sd(sample5)
[1] 0.5171083
#create histogram to visualize sampling distribution of sample means
hist(sample5, col = ' steelblue ', xlab=' Turtle Shell Width ', main=' Sample size = 5 ')
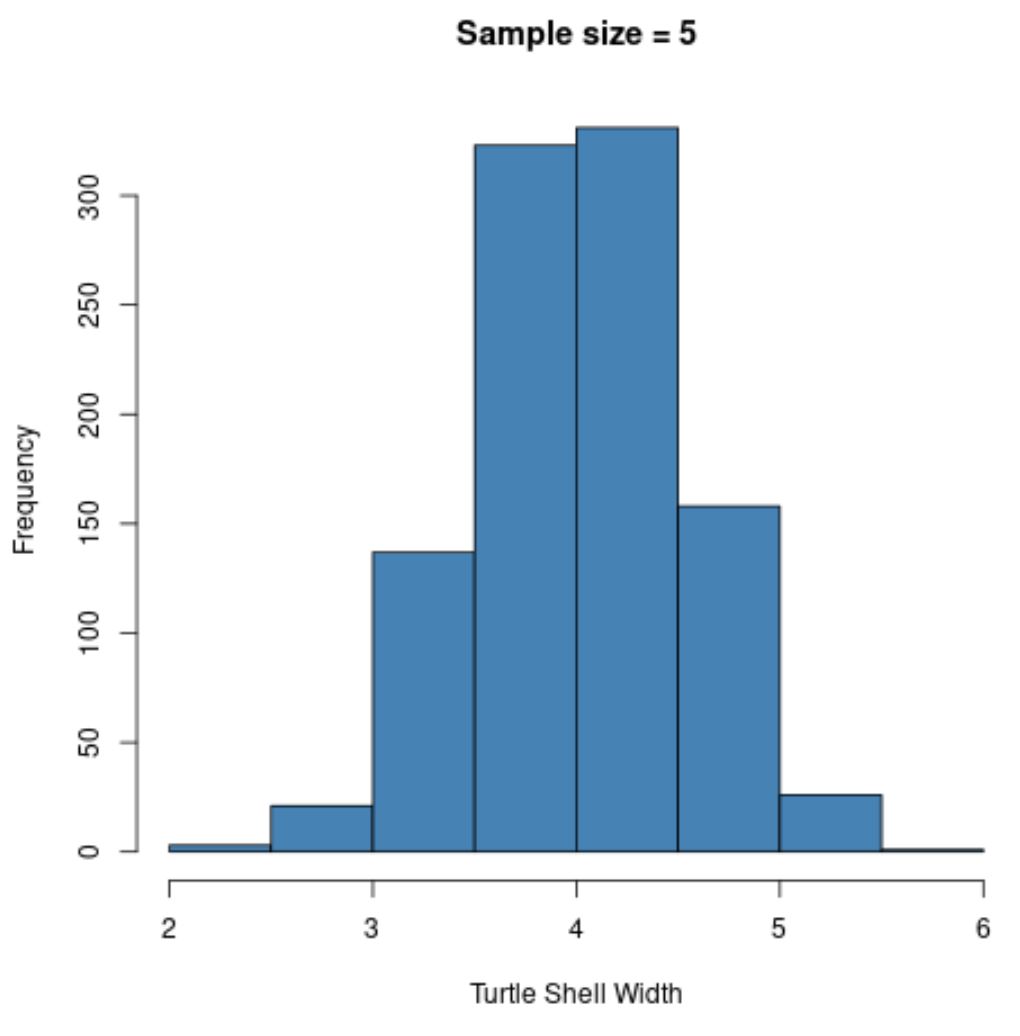
နမူနာများ ဖြန့်ဝေခြင်းဆိုသည်မှာ နမူနာများ ဖြန့်ဝေခြင်းမှ ပုံမှန်ဖြန့်ဝေခြင်းမဟုတ်သော်လည်း နမူနာဖြန့်ဝေခြင်းဆိုသည်မှာ ပုံမှန်အတိုင်း ဖြန့်ဝေပုံပေါ်သည်ကို သတိပြုပါ။
ဤနမူနာဖြန့်ဝေမှုအတွက် နမူနာပျမ်းမျှနှင့် နမူနာစံသွေဖည်မှုကိုလည်း သတိပြုပါ-
- x̄ : ၄.၀၀၈
- s : 0.517
ယခုကျွန်ုပ်တို့အသုံးပြုသောနမူနာအရွယ်အစားကို n=5 မှ n=30 သို့တိုးမြှင့်ပြီး နမူနာ၏ histogram ကို ပြန်လည်ဖန်တီးမည်ဆိုပါစို့။
#create empty vector to hold sample means
sample30 <- c()
#take 1,000 random samples of size n=30
n = 1000
for (i in 1:n){
sample30[i] = mean(sample(data, 30, replace= TRUE ))
}
#calculate mean and standard deviation of sample means
mean(sample30)
[1] 4.000472
sd(sample30)
[1] 0.2003791
#create histogram to visualize sampling distribution of sample means
hist(sample30, col = ' steelblue ', xlab=' Turtle Shell Width ', main=' Sample size = 30 ')
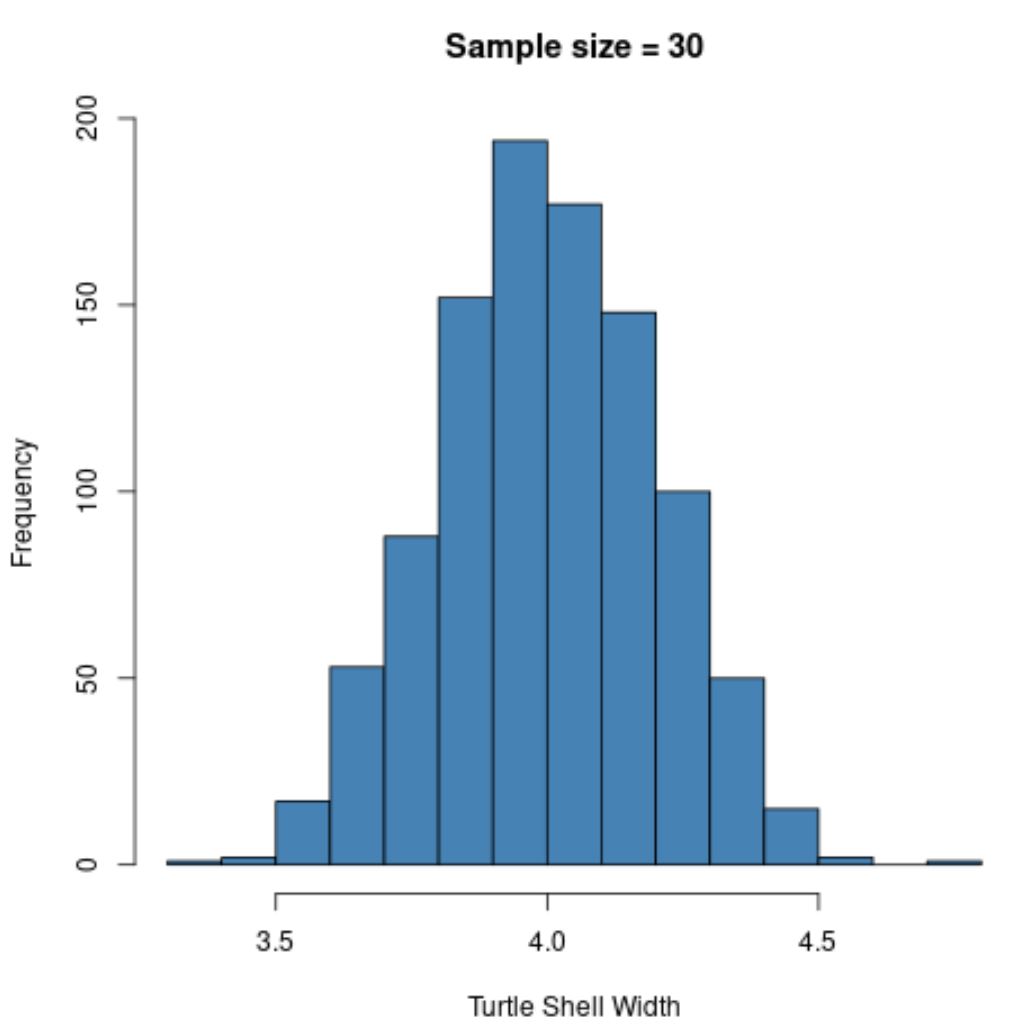
နမူနာဖြန့်ဝေမှုကို ပုံမှန်အတိုင်း ပြန်လည်ဖြန့်ဝေ သော်လည်း နမူနာစံသွေဖည်မှုမှာ ပို၍သေးငယ်သည်-
- s : 0.200
၎င်းမှာ ယခင်နမူနာ (n=5) နှင့် နှိုင်းယှဉ်ပါက ပိုကြီးသောနမူနာအရွယ်အစား (n=30) ကိုအသုံးပြုထားသောကြောင့်၊ ထို့ကြောင့် နမူနာဆိုလိုသည်၏ စံသွေဖည်မှုမှာ ပို၍သေးငယ်ပါသည်။
ကျွန်ုပ်တို့သည် ပိုမိုကြီးမားသောနမူနာများကို ဆက်လက်အသုံးပြုပါက၊ နမူနာစံသွေဖည်မှု သေးငယ်သည်နှင့် သေးငယ်လာသည်ကို ကျွန်ုပ်တို့ တွေ့ရှိမည်ဖြစ်ပါသည်။
၎င်းသည် လက်တွေ့တွင် ဗဟိုကန့်သတ်သီအိုရီကို သရုပ်ဖော်သည်။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါအရင်းအမြစ်များသည် ဗဟိုကန့်သတ်သီအိုရီနှင့်ပတ်သက်သော နောက်ထပ်အချက်အလက်များကို ပေးဆောင်သည်-
Central Limit Theorem နိဒါန်း
Central Limit Theorem ဂဏန်းတွက်စက်
5 လက်တွေ့ဘဝတွင် ဗဟိုကန့်သတ်သီအိုရီကို အသုံးပြုခြင်း ဥပမာများ
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။