R တွင် အလေးချိန် အနည်းဆုံး စတုရန်း ဆုတ်ယုတ်မှုကို မည်သို့လုပ်ဆောင်ရမည်နည်း
linear regression ၏ အဓိက ယူဆချက် တစ်ခုမှာ အကြွင်းအကျန်များကို ကြိုတင်ခန့်မှန်းကိန်းရှင် အဆင့်တစ်ခုစီတွင် တူညီသောကွဲလွဲမှုဖြင့် ဖြန့်ဝေပေးခြင်းဖြစ်သည်။ ဤယူဆချက်ကို homoscedasticity ဟုခေါ်သည်။
ဤယူဆချက်ကို မလေးစားပါက အကြွင်းအ ကျန်များတွင် ရှိနေသည်ဟု ဆိုပါသည်။ ထိုသို့ဖြစ်လာသောအခါ၊ ဆုတ်ယုတ်မှုရလဒ်များသည် ယုံကြည်စိတ်ချရခြင်းမရှိပေ။
ဤပြဿနာကိုဖြေရှင်းရန်နည်းလမ်းတစ်ခုမှာ အမှားကွဲလွဲမှုနည်းသော လေ့လာသုံးသပ်ချက်များ အတွက် အလေးများသတ်မှတ်ပေးသည့် အလေးချိန်အနည်းဆုံးစတုရန်းဆုတ်ယုတ်မှု ကိုအသုံးပြုခြင်းဖြစ်ပြီး အမှားကွဲလွဲမှုနည်းပါးသူများသည် အလေးချိန်ပိုမိုရရှိသောကြောင့် ၎င်းတို့တွင်အချက်အလက်များပိုမိုပါဝင်သောကြောင့် ၎င်းတို့တွင် အမှားအယွင်းကွဲလွဲမှုပိုများသောလေ့လာသုံးသပ်မှုများနှင့်နှိုင်းယှဉ်ပါ။
ဤသင်ခန်းစာသည် R တွင် အလေးချိန်အနည်းဆုံးစတုရန်းဆုတ်ယုတ်မှုလုပ်ဆောင်ပုံအဆင့်ဆင့်ကို ဥပမာပေးထားသည်။
အဆင့် 1: ဒေတာကိုဖန်တီးပါ။
အောက်ပါကုဒ်သည် သင်ကြားခဲ့သည့် နာရီအရေအတွက်နှင့် ကျောင်းသား 16 ဦးအတွက် သက်ဆိုင်ရာ စာမေးပွဲရမှတ်များပါရှိသော ဒေတာဘောင်တစ်ခုကို ဖန်တီးသည်-
df <- data.frame(hours=c(1, 1, 2, 2, 2, 3, 4, 4, 4, 5, 5, 5, 6, 6, 7, 8),
score=c(48, 78, 72, 70, 66, 92, 93, 75, 75, 80, 95, 97, 90, 96, 99, 99))
အဆင့် 2- Linear Regression လုပ်ဆောင်ပါ။
ထို့နောက်၊ ကျွန်ုပ်တို့သည် ခန့်မှန်းကိန်းရှင်ကိန်းရှင်အဖြစ် နာရီကိုအသုံးပြုကာ တုံ့ပြန်မှုကိန်းရှင် အဖြစ် ရမှတ်ကိုအသုံးပြုသည့် ရိုးရှင်းသောမျဉ်းကြောင်းဆုတ်ယုတ်မှုပုံစံ နှင့်ကိုက်ညီရန် lm() လုပ်ဆောင်ချက်ကို အသုံးပြုပါမည်။
#fit simple linear regression model model <- lm(score ~ hours, data = df) #view summary of model summary(model) Call: lm(formula = score ~ hours, data = df) Residuals: Min 1Q Median 3Q Max -17,967 -5,970 -0.719 7,531 15,032 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 60,467 5,128 11,791 1.17e-08 *** hours 5,500 1,127 4,879 0.000244 *** --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 9.224 on 14 degrees of freedom Multiple R-squared: 0.6296, Adjusted R-squared: 0.6032 F-statistic: 23.8 on 1 and 14 DF, p-value: 0.0002438
အဆင့် 3- မျိုးရိုးလိုက်ခြင်းအတွက် စမ်းသပ်ပါ။
ထို့နောက်၊ ကျွန်ုပ်တို့သည် မျိုးရိုးလိုက်ခြင်းအတွက် အမြင်အာရုံဖြင့် စစ်ဆေးရန် ကျန်ရှိသော အကွက်များနှင့် တပ်ဆင်ထားသော တန်ဖိုးများကို ဖန်တီးပါမည်။
#create residual vs. fitted plot plot( fitted (model), resid (model), xlab=' Fitted Values ', ylab=' Residuals ') #add a horizontal line at 0 abline(0,0)
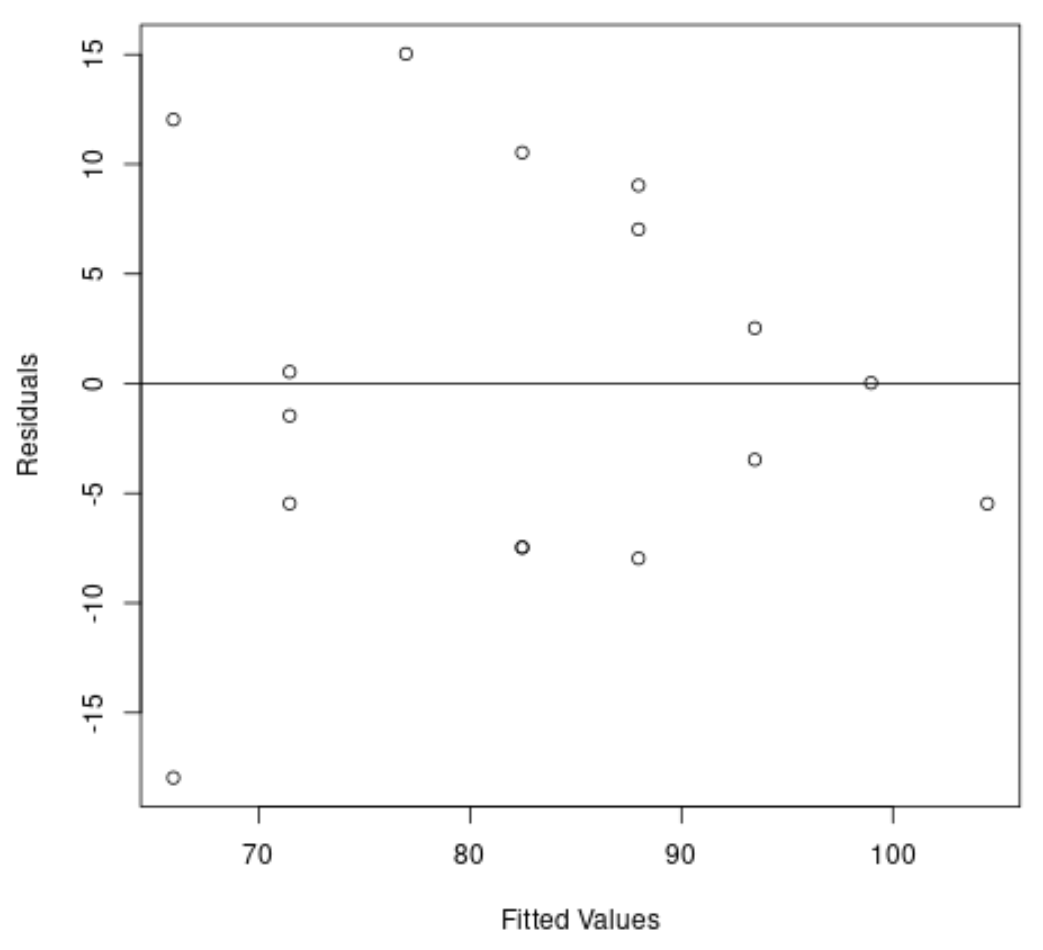
အကြွင်းအကျန်များသည် “ ပုံးပုံ” ပုံသဏ္ဍာန်ရှိသည်ကို ဂရပ်ဖ်မှမြင်နိုင်သည်- ၎င်းတို့သည် ဂရပ်တစ်လျှောက်လုံးတူညီသောကွဲလွဲမှုဖြင့် မဖြန့်ဝေပါ။
မျိုးကွဲကွဲပြားမှုအတွက်တရားဝင်စမ်းသပ်ရန်၊ ကျွန်ုပ်တို့သည် Breusch-Pagan စမ်းသပ်မှုကိုလုပ်ဆောင်နိုင်သည်-
#load lmtest package library (lmtest) #perform Breusch-Pagan test bptest(model) studentized Breusch-Pagan test data: model BP = 3.9597, df = 1, p-value = 0.0466
Breusch-Pagan စမ်းသပ်မှုတွင် အောက်ပါ null နှင့် အခြားအခြားသော အယူအဆများကို အသုံးပြုသည် ။
- Null hypothesis (H 0 ) : homoscedasticity ရှိနေသည် (ကျန်အကြွင်းများကို တူညီသောကွဲလွဲမှုဖြင့် ဖြန့်ဝေသည်)
- အစားထိုး အယူအဆ ( HA ) : heteroscedasticity ရှိနေသည် (ကျန်အကြွင်းများကို တူညီသောကွဲလွဲမှုဖြင့် မဖြန့်ဝေပါ)
စစ်ဆေးမှု၏ p-value သည် 0.0466 ဖြစ်သောကြောင့်၊ ကျွန်ုပ်တို့သည် null hypothesis ကို ပယ်ချပြီး heteroscedasticity သည် ဤပုံစံတွင် ပြဿနာတစ်ခုဖြစ်ကြောင်း ကောက်ချက်ချပါမည်။
အဆင့် 4- အလေးချိန်အနည်းဆုံးစတုရန်းဆုတ်ယုတ်မှုကိုလုပ်ဆောင်ပါ။
heteroscedasticity ရှိနေပြီဖြစ်သောကြောင့်၊ အောက်ပိုင်းကွဲလွဲမှုဖြင့် လေ့လာတွေ့ရှိချက်များသည် အလေးချိန်ပိုမိုရရှိစေသည့် အလေးချိန်များကို သတ်မှတ်ခြင်းဖြင့် အနည်းဆုံး လေးထောင့်အလေးချိန်များကို လုပ်ဆောင်ပါမည်။
#define weights to use
wt <- 1 / lm( abs (model$residuals) ~ model$fitted. values )$fitted. values ^2
#perform weighted least squares regression
wls_model <- lm(score ~ hours, data = df, weights=wt)
#view summary of model
summary(wls_model)
Call:
lm(formula = score ~ hours, data = df, weights = wt)
Weighted Residuals:
Min 1Q Median 3Q Max
-2.0167 -0.9263 -0.2589 0.9873 1.6977
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 63.9689 5.1587 12.400 6.13e-09 ***
hours 4.7091 0.8709 5.407 9.24e-05 ***
---
Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.199 on 14 degrees of freedom
Multiple R-squared: 0.6762, Adjusted R-squared: 0.6531
F-statistic: 29.24 on 1 and 14 DF, p-value: 9.236e-05
ရလဒ်များမှ၊ နာရီ ခန့်မှန်းပေးသူ variable အတွက် ကိန်းဂဏန်း ခန့်မှန်းချက်သည် အနည်းငယ် ပြောင်းလဲသွားပြီး အလုံးစုံ မော်ဒယ်နှင့် အံဝင်ခွင်ကျ တိုးတက်လာသည်ကို တွေ့နိုင်ပါသည်။
အလေးချိန်အနည်းဆုံးစတုရန်းမော်ဒယ်သည် မူလရိုးရှင်းသောမျဉ်းကြောင်းဆုတ်ယုတ်မှုပုံစံတွင် 9.224 နှင့် နှိုင်းယှဉ်ပါက ကျန်ရှိသောစံနှုန်းအမှား 1.199 ရှိသည်။
အလေးချိန်အနည်းဆုံးစတုရန်းမော်ဒယ်မှထုတ်လုပ်သော ခန့်မှန်းတန်ဖိုးများသည် ရိုးရှင်းသော linear regression model မှထုတ်လုပ်သော ခန့်မှန်းတန်ဖိုးများနှင့် နှိုင်းယှဉ်ပါက အမှန်တကယ်လေ့လာတွေ့ရှိချက်များနှင့် များစွာနီးစပ်ကြောင်း ညွှန်ပြပါသည်။
အလေးချိန်အနည်းဆုံးစတုရန်းပုံစံတွင် မူလရိုးရှင်းသောမျဉ်းကြောင်းဆုတ်ယုတ်မှုပုံစံရှိ 0.6296 နှင့် နှိုင်းယှဉ်ပါက R-squared 0.6762 ရှိသည်။
၎င်းသည် အလေးချိန်အနည်းဆုံးစတုရန်းပုံစံသည် ရိုးရှင်းသောမျဉ်းဖြောင့်ဆုတ်ယုတ်မှုပုံစံထက် စာမေးပွဲရမှတ်များတွင် ကွဲလွဲမှုကို ပိုမိုရှင်းပြနိုင်သည်ကို ဖော်ပြသည်။
ဤတိုင်းတာချက်များအရ အလေးချိန်အနည်းဆုံးစတုရန်းပုံစံသည် ရိုးရှင်းသော linear regression model နှင့် နှိုင်းယှဉ်ပါက data နှင့် ပိုမိုကိုက်ညီမှုရှိသည်ကို ဖော်ပြသည်။
ထပ်လောင်းအရင်းအမြစ်များ
R တွင် ရိုးရှင်းသော linear regression လုပ်နည်း
R တွင် linear regression အများအပြားလုပ်ဆောင်နည်း
R တွင် Quantile Regression ကို မည်သို့လုပ်ဆောင်ရမည်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။