R တွင် အဓိကအစိတ်အပိုင်း ဆုတ်ယုတ်မှု (အဆင့်ဆင့်)
p ကြိုတင်ခန့်မှန်းကိန်းရှင် ကိန်းရှင်အစုတစ်ခုနှင့် တုံ့ပြန်မှုကိန်းရှင်တစ်ခုအား ပေးထားသည့် မျဉ်းကြောင်းပြန်ဆုတ်မှု အများအပြားသည် ကျန်ရှိသောစတုရန်း၏ပေါင်းလဒ် (RSS) ကို လျှော့ချရန် အနည်းဆုံးစတုရန်းဟု ခေါ်သည့် နည်းလမ်းကို အသုံးပြုသည်-
RSS = Σ(y i – ŷ i ) ၂
ရွှေ-
- ∑ : ပေါင်းလဒ် ဟု အဓိပ္ပာယ်ရသော ဂရိသင်္ကေတ
- y i : အိုင်တီ လေ့လာခြင်းအတွက် အမှန်တကယ် တုံ့ပြန်မှုတန်ဖိုး
- ŷ i : Multiple linear regression model ကို အခြေခံ၍ ခန့်မှန်းထားသော တုံ့ပြန်မှုတန်ဖိုး
သို့ရာတွင်၊ ကြိုတင်ခန့်မှန်းနိုင်သောကိန်းရှင်များသည် အလွန်ဆက်စပ်နေသောအခါတွင်၊ ကော်လိုင်းပေါင်းစုံသည် ပြဿနာဖြစ်လာနိုင်သည်။ ၎င်းသည် မော်ဒယ်ဖော်ကိန်း ခန့်မှန်းချက်များကို ယုံကြည်စိတ်ချမှုမရှိစေဘဲ ကွဲပြားမှုမြင့်မားမှုကို ပြသနိုင်သည်။
ဤပြဿနာကို ရှောင်ရှားရန် နည်းလမ်းတစ်ခုမှာ မူလ p ကြိုတင်တွက်ဆမှုများ၏ M linear ပေါင်းစပ်မှုများ (“ principal components” ဟုခေါ်သည်) ကိုရှာပေးသည့် အဓိကအစိတ်အပိုင်းများ ဆုတ်ယုတ်မှု ကို အသုံးပြုပြီး ပင်မအစိတ်အပိုင်းများကို ကြိုတင်ဟောကိန်းထုတ်သူများအဖြစ် အသုံးပြုကာ အနိမ့်ဆုံးစတုရန်းများကို အသုံးပြုခြင်းဖြစ်သည်။
ဤသင်ခန်းစာသည် R တွင် အဓိကအစိတ်အပိုင်းများ ဆုတ်ယုတ်ခြင်းကို လုပ်ဆောင်ပုံအဆင့်ဆင့်ကို ဥပမာပေးထားသည်။
အဆင့် 1- လိုအပ်သော ပက်ကေ့ခ်ျများကို တင်ပါ။
R တွင်အဓိကအစိတ်အပိုင်းများဆုတ်ယုတ်ခြင်းကိုလုပ်ဆောင်ရန်အလွယ်ကူဆုံးနည်းလမ်းမှာ pls package အတွင်းရှိလုပ်ဆောင်ချက်များကိုအသုံးပြုရန်ဖြစ်သည်။
#install pls package (if not already installed) install.packages(" pls ") load pls package library(pls)
အဆင့် 2- PCR မော်ဒယ်ကို ချိန်ညှိပါ။
ဤဥပမာအတွက်၊ ကျွန်ုပ်တို့သည် ကားအမျိုးအစားအမျိုးမျိုးတွင် ဒေတာပါရှိသော mtcars ဟုခေါ်သော တပ်ဆင်ထားသည့် R ဒေတာအစုံကို အသုံးပြုပါမည်-
#view first six rows of mtcars dataset
head(mtcars)
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3,460 20.22 1 0 3 1
ဤဥပမာအတွက်၊ ကျွန်ုပ်တို့သည် တုံ့ပြန်မှုကိန်း ရှင်အဖြစ် hp ကို အသုံးပြုကာ အဓိကအစိတ်အပိုင်းများဆုတ်ယုတ်မှု (PCR) မော်ဒယ်ကို ဖြည့်သွင်းပေးမည်ဖြစ်ပြီး၊
- စိုင်းစိုင်းခမ်းလှိုင်
- ပြသခြင်း။
- ပြောရမှာပါ။
- ကိုယ်အလေးချိန်
- qsec
အောက်ဖော်ပြပါကုဒ်သည် PCR မော်ဒယ်ကို ဤဒေတာနှင့် မည်သို့ အံဝင်ခွင်ကျဖြစ်စေရန် ဖော်ပြသည်။ အောက်ပါအငြင်းပွားမှုများကို သတိပြုပါ။
- scale=TRUE : ခန့်မှန်းသူ variable တစ်ခုစီသည် 0 နှင့် 1 ၏ စံသွေဖည်မှုရှိရန် အတိုင်းအတာတစ်ခုစီရှိသင့်သည်ဟု R ကိုပြောပြသည်။ ၎င်းသည် မတူညီသောယူနစ်များဖြင့် တိုင်းတာပါက မော်ဒယ်တွင် မည်မျှသြဇာလွှမ်းမိုးနိုင်သည်ကို သေချာစေပါသည်။ .
- validation=”CV” – မော်ဒယ်စွမ်းဆောင်ရည်ကိုအကဲဖြတ်ရန် R သည် k-fold cross validation ကို အသုံးပြုရန်ပြောထားသည်။ ၎င်းသည် ပုံမှန်အားဖြင့် k=10 ခေါက်ကို အသုံးပြုကြောင်း သတိပြုပါ။ Leave-One-Out cross-validation လုပ်ဆောင်ရန် “ LOOCV” ကို သင် သတ်မှတ်နိုင်သည်ကိုလည်း သတိပြုပါ။
#make this example reproducible set.seed(1) #fit PCR model model <- pcr(hp~mpg+disp+drat+wt+qsec, data=mtcars, scale= TRUE , validation=" CV ")
အဆင့် 3- အဓိက အစိတ်အပိုင်း အရေအတွက်ကို ရွေးပါ။
ကျွန်ုပ်တို့သည် မော်ဒယ်ကို ချိန်ညှိပြီးသည်နှင့်၊ ကျွန်ုပ်တို့သည် အဓိက အစိတ်အပိုင်းများ မည်မျှ ထိန်းသိမ်းထားသင့်သည်ကို ဆုံးဖြတ်ရန် လိုအပ်ပါသည်။
ဒါကိုလုပ်ဖို့၊ k-cross validation ဖြင့်တွက်ချက်ထားသော test root mean square error (test RMSE) ကိုကြည့်ပါ-
#view summary of model fitting
summary(model)
Data:
Y dimension: 32 1
Fit method: svdpc
Number of components considered: 5
VALIDATION: RMSEP
Cross-validated using 10 random segments.
(Intercept) 1 comp 2 comps 3 comps 4 comps 5 comps
CV 69.66 44.56 35.64 35.83 36.23 36.67
adjCV 69.66 44.44 35.27 35.43 35.80 36.20
TRAINING: % variance explained
1 comp 2 comps 3 comps 4 comps 5 comps
X 69.83 89.35 95.88 98.96 100.00
hp 62.38 81.31 81.96 81.98 82.03
ရလဒ်တွင် စိတ်ဝင်စားစရာကောင်းသော ဇယားနှစ်ခုရှိသည်။
1. တရားဝင်- RMSEP
ဤဇယားသည် k-fold cross validation ဖြင့်တွက်ချက်ထားသော RMSE စာမေးပွဲကိုပြောပြသည်။ အောက်ပါတို့ကို ကျွန်ုပ်တို့ မြင်နိုင်သည်-
- မော်ဒယ်တွင် မူရင်းအခေါ်အဝေါ်ကိုသာ အသုံးပြုပါက၊ စမ်းသပ်မှု၏ RMSE သည် 69.66 ဖြစ်သည်။
- ကျွန်ုပ်တို့သည် ပထမအဓိကအစိတ်အပိုင်းကို ပေါင်းထည့်ပါက RMSE စမ်းသပ်မှုသည် 44.56 သို့ကျဆင်းသွားသည်။
- ကျွန်ုပ်တို့သည် ဒုတိယအဓိကအစိတ်အပိုင်းကို ပေါင်းထည့်ပါက RMSE စမ်းသပ်မှုသည် 35.64 သို့ကျဆင်းသွားသည်။
အပိုဆောင်းအဓိကအစိတ်အပိုင်းများကို ပေါင်းထည့်ခြင်းသည် စမ်းသပ်မှု၏ RMSE တိုးလာကြောင်း ကျွန်ုပ်တို့တွေ့မြင်နိုင်ပါသည်။ ထို့ကြောင့် နောက်ဆုံးမော်ဒယ်တွင် အဓိကအစိတ်အပိုင်းနှစ်ခုကိုသာ အသုံးပြုခြင်းသည် အကောင်းဆုံးဖြစ်ဟန်တူသည်။
2. လေ့ကျင့်ရေး- ကွဲလွဲမှု % ကို ရှင်းပြသည်။
ဤဇယားတွင် အဓိကအစိတ်အပိုင်းများဖြင့် ရှင်းပြထားသည့် တုံ့ပြန်မှုကိန်းရှင်တွင် ကွဲလွဲမှုရာခိုင်နှုန်းကို ပြောပြသည်။ အောက်ပါတို့ကို ကျွန်ုပ်တို့ မြင်နိုင်သည်-
- ပထမ အဓိက အစိတ်အပိုင်းကို အသုံးပြု၍ တုံ့ပြန်မှု ကိန်းရှင်တွင် ကွဲလွဲမှု 69.83% ကို ရှင်းပြနိုင်ပါသည်။
- ဒုတိယအဓိကအစိတ်အပိုင်းကို ပေါင်းထည့်ခြင်းဖြင့် တုံ့ပြန်မှုကိန်းရှင်တွင် ကွဲလွဲမှု 89.35% ကို ရှင်းပြနိုင်ပါသည်။
အဓိက အစိတ်အပိုင်းများကို အသုံးပြုခြင်းဖြင့် ကျွန်ုပ်တို့သည် ပိုမိုကွဲလွဲမှုကို ရှင်းပြနိုင်ဆဲဖြစ်သည်ကို သတိပြုပါ၊ သို့သော် အဓိကအစိတ်အပိုင်းနှစ်ခုထက်ပိုထည့်ခြင်းသည် ရှင်းပြထားသည့်ကွဲလွဲမှုရာခိုင်နှုန်းကို အမှန်တကယ်မတိုးကြောင်း သတိပြုပါ။
validationplot() လုပ်ဆောင်ချက်ကို အသုံးပြု၍ အဓိကအစိတ်အပိုင်းအရေအတွက်၏ လုပ်ဆောင်မှုအဖြစ် RMSE စာမေးပွဲ (MSE နှင့် R-squared စမ်းသပ်မှုနှင့်အတူ) ကို မြင်ယောင်နိုင်သည်။
#visualize cross-validation plots
validationplot(model)
validationplot(model, val.type="MSEP")
validationplot(model, val.type="R2")
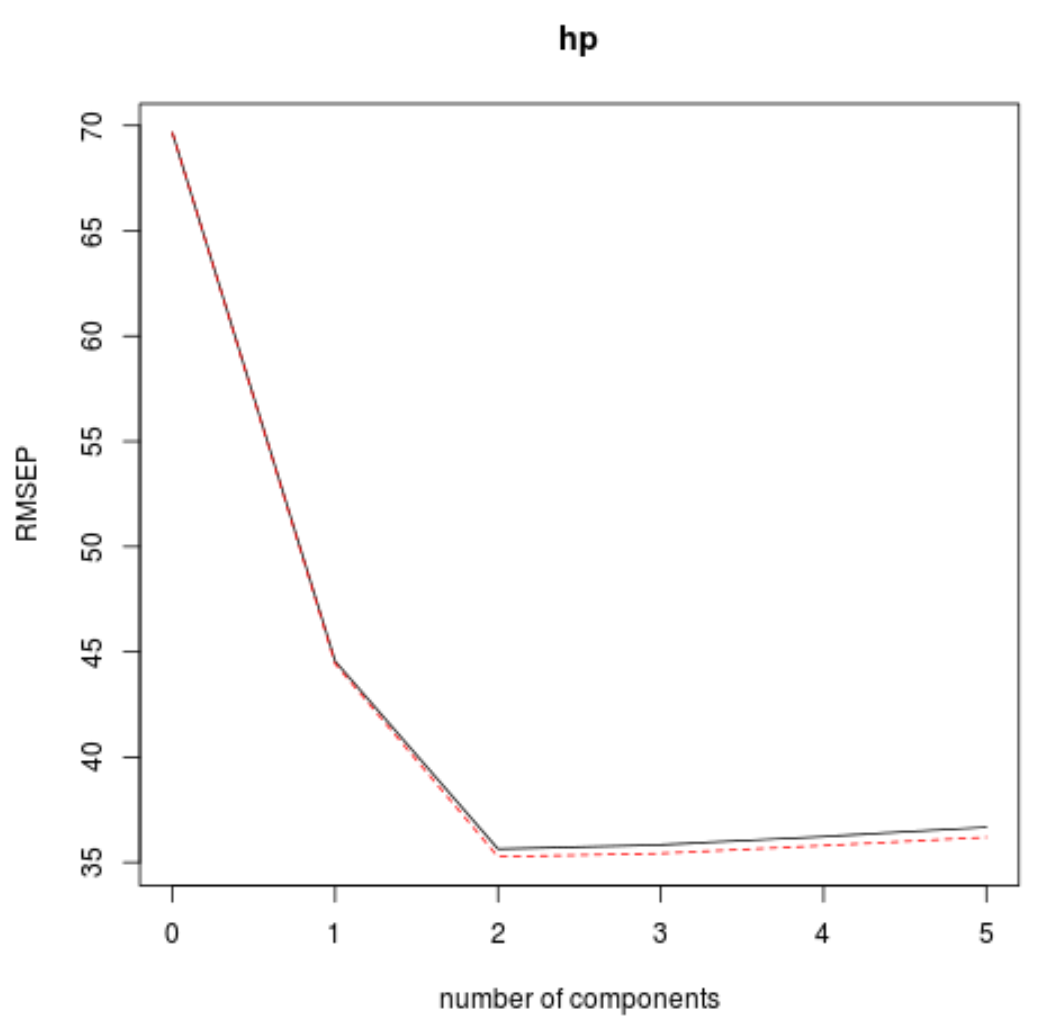
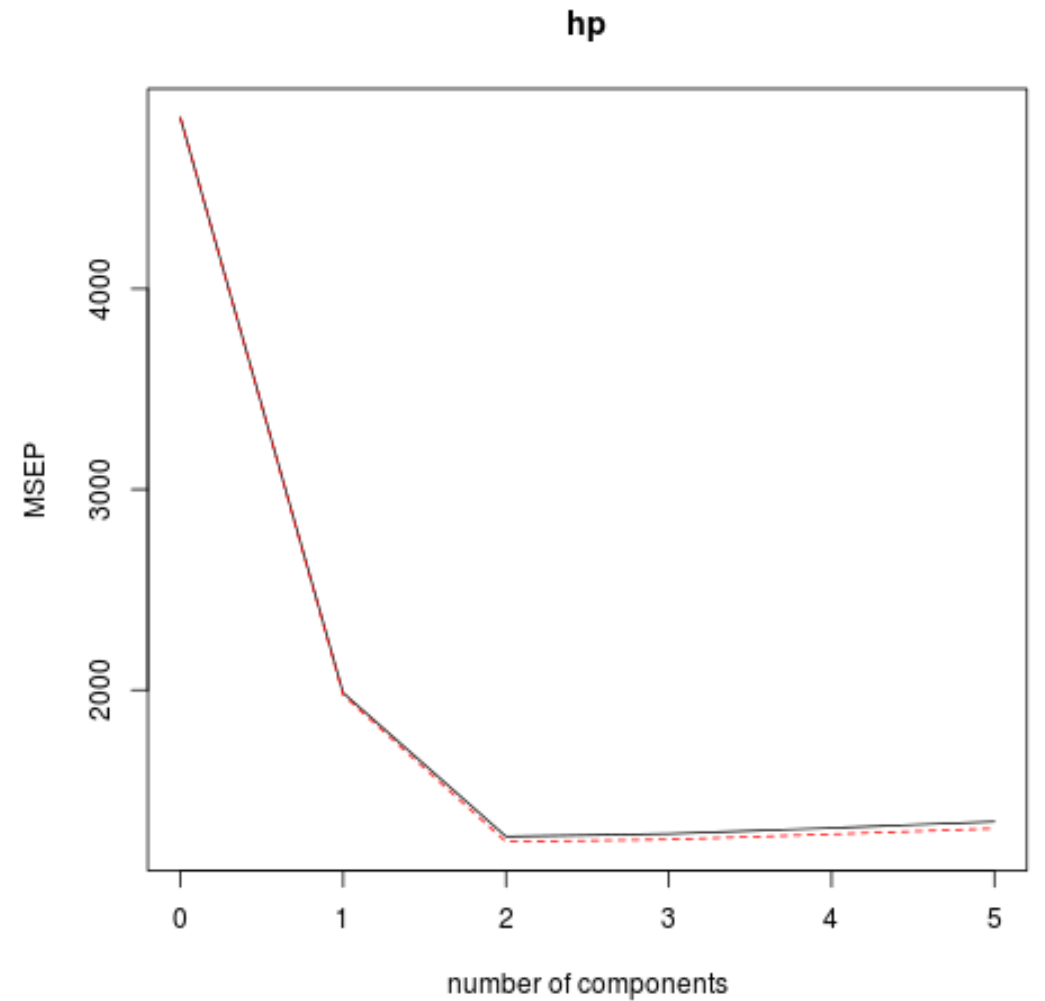
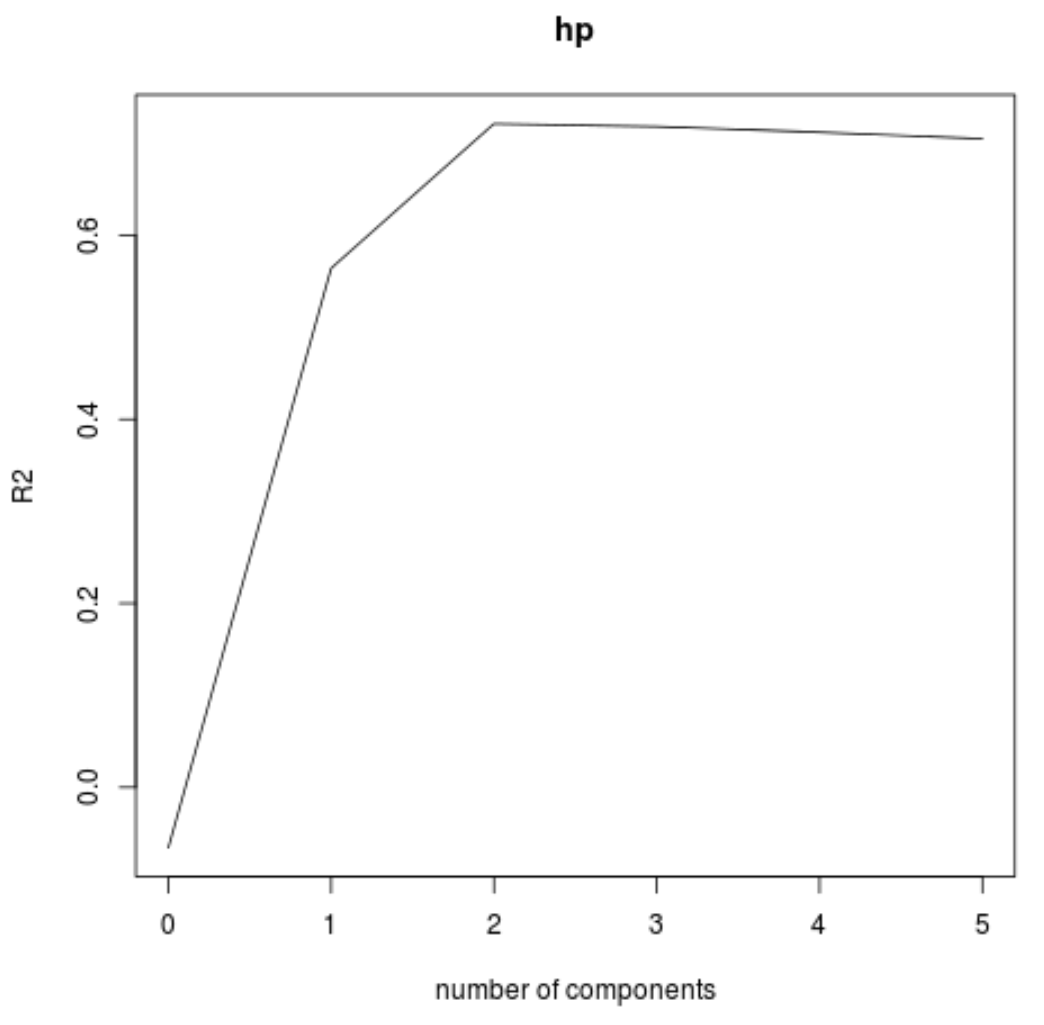
ဂရပ်တစ်ခုစီတွင်၊ အဓိကအစိတ်အပိုင်းနှစ်ခုကိုထည့်ခြင်းဖြင့် မော်ဒယ်သည် အံဝင်ခွင်ကျဖြစ်နေသည်ကို ကျွန်ုပ်တို့တွေ့မြင်နိုင်သော်လည်း အဓိကအစိတ်အပိုင်းများကို ကျွန်ုပ်တို့ထပ်ထည့်သောအခါတွင် ဆိုးရွားသွားတတ်သည်။
ထို့ကြောင့် အကောင်းဆုံးမော်ဒယ်တွင် ပထမအဓိကအစိတ်အပိုင်းနှစ်ခုသာ ပါဝင်ပါသည်။
အဆင့် 4- ခန့်မှန်းချက်များကို ပြုလုပ်ရန် နောက်ဆုံးပုံစံကို အသုံးပြုပါ။
လေ့လာတွေ့ရှိချက်အသစ်များနှင့်ပတ်သက်၍ ခန့်မှန်းချက်များပြုလုပ်ရန် နောက်ဆုံးအဓိကအစိတ်အပိုင်းနှစ်ခု PCR မော်ဒယ်ကို ကျွန်ုပ်တို့အသုံးပြုနိုင်ပါသည်။
အောက်ပါကုဒ်သည် မူရင်းဒေတာအစုံကို လေ့ကျင့်ရေးနှင့် စမ်းသပ်မှုအဖြစ် ပိုင်းခြားပုံပြသပြီး စမ်းသပ်မှုအစုတွင် ခန့်မှန်းချက်များပြုလုပ်ရန် အဓိကအစိတ်အပိုင်းနှစ်ခုပါရှိသော PCR မော်ဒယ်ကို အသုံးပြုပါ။
#define training and testing sets train <- mtcars[1:25, c("hp", "mpg", "disp", "drat", "wt", "qsec")] y_test <- mtcars[26: nrow (mtcars), c("hp")] test <- mtcars[26: nrow (mtcars), c("mpg", "disp", "drat", "wt", "qsec")] #use model to make predictions on a test set model <- pcr(hp~mpg+disp+drat+wt+qsec, data=train, scale= TRUE , validation=" CV ") pcr_pred <- predict(model, test, ncomp= 2 ) #calculate RMSE sqrt ( mean ((pcr_pred - y_test)^2)) [1] 56.86549
စာမေးပွဲ၏ RMSE သည် 56.86549 ဖြစ်သွားသည်ကို ကျွန်ုပ်တို့မြင်ရသည်။ ၎င်းသည် ခန့်မှန်းထားသော hp တန်ဖိုးနှင့် စမ်းသပ်မှုအစုအဝေးအတွက် လေ့လာတွေ့ရှိထားသော hp တန်ဖိုးကြား ပျမ်းမျှသွေဖည်မှုဖြစ်သည်။
ဤဥပမာတွင် R ကုဒ်၏ အပြည့်အဝအသုံးပြုမှုကို ဤနေရာတွင် တွေ့နိုင်ပါသည်။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။