R တွင် အမျိုးအစားခွဲခြင်းနှင့် ဆုတ်ယုတ်ခြင်းသစ်ပင်များနှင့် အံကိုက်လုပ်နည်း
ကြိုတင်ခန့်မှန်းကိန်းရှင်အစုတစ်ခုနှင့် တုံ့ပြန်မှုကိန်းရှင် ကြားရှိ ဆက်နွှယ်မှုသည် တစ်ပြေးညီဖြစ်နေသောအခါ၊ များစွာသောမျဉ်းကြောင်းဆုတ်ယုတ်မှု ကဲ့သို့သော နည်းလမ်းများသည် တိကျသောကြိုတင်ခန့်မှန်းမှုပုံစံများကို ထုတ်ပေးနိုင်သည်။
သို့ရာတွင်၊ ကြိုတင်ခန့်မှန်းသူအစုအဝေးနှင့် တုံ့ပြန်မှုကြားဆက်ဆံရေးသည် ပိုမိုရှုပ်ထွေးသောအခါ၊ လိုင်းမဟုတ်သောနည်းလမ်းများသည် မကြာခဏ ပိုမိုတိကျသောမော်ဒယ်များကို ထုတ်လုပ်နိုင်သည်။
ထိုနည်းလမ်းမှာ အမျိုးအစားခွဲခြင်းနှင့် ဆုတ်ယုတ်မှုသစ်ပင်များ (CART) သည် တုံ့ပြန်မှုကိန်းရှင်၏တန်ဖိုးကို ခန့်မှန်းသည့် ဆုံးဖြတ်ချက်သစ်များဖန်တီးရန် ကြိုတင်ခန့်မှန်းကိန်းရှင်များအစုအဝေးကို အသုံးပြုသည်။
တုံ့ပြန်မှုကိန်းရှင်သည် စဉ်ဆက်မပြတ်ဖြစ်နေပါက ကျွန်ုပ်တို့သည် ဆုတ်ယုတ်မှုသစ်ပင်များကို တည်ဆောက်နိုင်ပြီး တုံ့ပြန်မှုကိန်းရှင်သည် အမျိုးအစားခွဲခြားပါက အမျိုးအစားခွဲခြင်းသစ်ပင်များကို တည်ဆောက်နိုင်သည်။
ဤသင်ခန်းစာသည် R တွင် ဆုတ်ယုတ်ခြင်းနှင့် အမျိုးအစားခွဲခြင်းသစ်ပင်များဖန်တီးနည်းကို ရှင်းပြထားသည်။
ဥပမာ 1- R တွင် Regression Tree တစ်ခုတည်ဆောက်ခြင်း။
ဤဥပမာအတွက်၊ ကျွန်ုပ်တို့သည် ပရော်ဖက်ရှင်နယ်ဘေ့စ်ဘောကစားသမား ၂၆၃ ဦး၏ အချက်အလက်များစွာပါရှိသော ISLR ပက်ကေ့ခ်ျမှ Hitters ဒေတာအတွဲကို အသုံးပြုပါမည်။
ပေးထားသော ကစားသမား၏ လစာကို ခန့်မှန်းရန် အိမ်တွင်းပြေးပွဲများ နှင့် ကစားသည့်နှစ်များ၏ ခန့်မှန်းကိန်းများကို အသုံးပြုသည့် ဆုတ်ယုတ်မှုသစ်ပင်ကို တည်ဆောက်ရန် ဤဒေတာအတွဲကို အသုံးပြုပါမည်။
ဤဆုတ်ယုတ်မှုသစ်ပင်ကို ဖန်တီးရန် အောက်ပါအဆင့်များကို အသုံးပြုပါ။
အဆင့် 1- လိုအပ်သော ပက်ကေ့ခ်ျများကို တင်ပါ။
ပထမဦးစွာ၊ ဤဥပမာအတွက် လိုအပ်သော ပက်ကေ့ဂျ်များကို တင်ပေးပါမည်။
library (ISLR) #contains Hitters dataset library (rpart) #for fitting decision trees library (rpart.plot) #for plotting decision trees
အဆင့် 2- ကနဦးဆုတ်ယုတ်မှုသစ်ပင်ကို တည်ဆောက်ပါ။
ပထမဦးစွာ ကျွန်ုပ်တို့သည် ကြီးမားသော ကနဦးဆုတ်ယုတ်မှုသစ်ပင်ကို တည်ဆောက်ပါမည်။ “ ရှုပ်ထွေးမှု ကန့်သတ်ဘောင်” ၏ အတိုကောက်ဖြစ်သော cp အတွက် တန်ဖိုးအနည်းငယ်ကို အသုံးပြုခြင်းဖြင့် သစ်ပင်ကြီးသည် ကျွန်ုပ်တို့ အာမခံနိုင်ပါသည်။
ဆိုလိုသည်မှာ မော်ဒယ်၏ R-squared သည် cp မှသတ်မှတ်ထားသောတန်ဖိုးအနည်းဆုံးဖြင့် တိုးလာသရွေ့ regression tree တွင် နောက်ထပ်ခွဲခြမ်းမှုများကို လုပ်ဆောင်ရမည်ဖြစ်ပါသည်။
ထို့နောက် မော်ဒယ်ရလဒ်များကို ပရင့်ထုတ်ရန် printcp() လုပ်ဆောင်ချက်ကို အသုံးပြုပါမည်။
#build the initial tree
tree <- rpart(Salary ~ Years + HmRun, data=Hitters, control=rpart. control (cp= .0001 ))
#view results
printcp(tree)
Variables actually used in tree construction:
[1] HmRun Years
Root node error: 53319113/263 = 202734
n=263 (59 observations deleted due to missingness)
CP nsplit rel error xerror xstd
1 0.24674996 0 1.00000 1.00756 0.13890
2 0.10806932 1 0.75325 0.76438 0.12828
3 0.01865610 2 0.64518 0.70295 0.12769
4 0.01761100 3 0.62652 0.70339 0.12337
5 0.01747617 4 0.60891 0.70339 0.12337
6 0.01038188 5 0.59144 0.66629 0.11817
7 0.01038065 6 0.58106 0.65697 0.11687
8 0.00731045 8 0.56029 0.67177 0.11913
9 0.00714883 9 0.55298 0.67881 0.11960
10 0.00708618 10 0.54583 0.68034 0.11988
11 0.00516285 12 0.53166 0.68427 0.11997
12 0.00445345 13 0.52650 0.68994 0.11996
13 0.00406069 14 0.52205 0.68988 0.11940
14 0.00264728 15 0.51799 0.68874 0.11916
15 0.00196586 16 0.51534 0.68638 0.12043
16 0.00016686 17 0.51337 0.67577 0.11635
17 0.00010000 18 0.51321 0.67576 0.11615
n=263 (59 observations deleted due to missingness)
အဆင့် 3: သစ်ပင်ကို ခုတ်ထစ်ပါ။
ထို့နောက်၊ အနိမ့်ဆုံးစမ်းသပ်မှုအမှားသို့ ဦးတည်စေသော cp (ရှုပ်ထွေးမှု ကန့်သတ်ဘောင်) အတွက် အသုံးပြုရန် အကောင်းဆုံးတန်ဖိုးကို ရှာဖွေရန် ဆုတ်ယုတ်မှုသစ်ပင်ကို ဖြတ်တောက်ပါမည်။
cp အတွက် အကောင်းဆုံးတန်ဖိုးသည် ယခင်ထွက်ရှိမှုတွင် အနိမ့်ဆုံး x-error သို့ ဦးတည်စေသည်၊ ၎င်းသည် အပြန်အလှန်စစ်ဆေးခြင်းဒေတာမှ မှတ်သားမှုများအပေါ် မှားယွင်းမှုကို ကိုယ်စားပြုကြောင်း သတိပြုပါ။
#identify best cp value to use
best <- tree$cptable[which. min (tree$cptable[," xerror "])," CP "]
#produce a pruned tree based on the best cp value
pruned_tree <- prune (tree, cp=best)
#plot the pruned tree
prp(pruned_tree,
faclen= 0 , #use full names for factor labels
extra= 1 , #display number of obs. for each terminal node
roundint= F , #don't round to integers in output
digits= 5 ) #display 5 decimal places in output

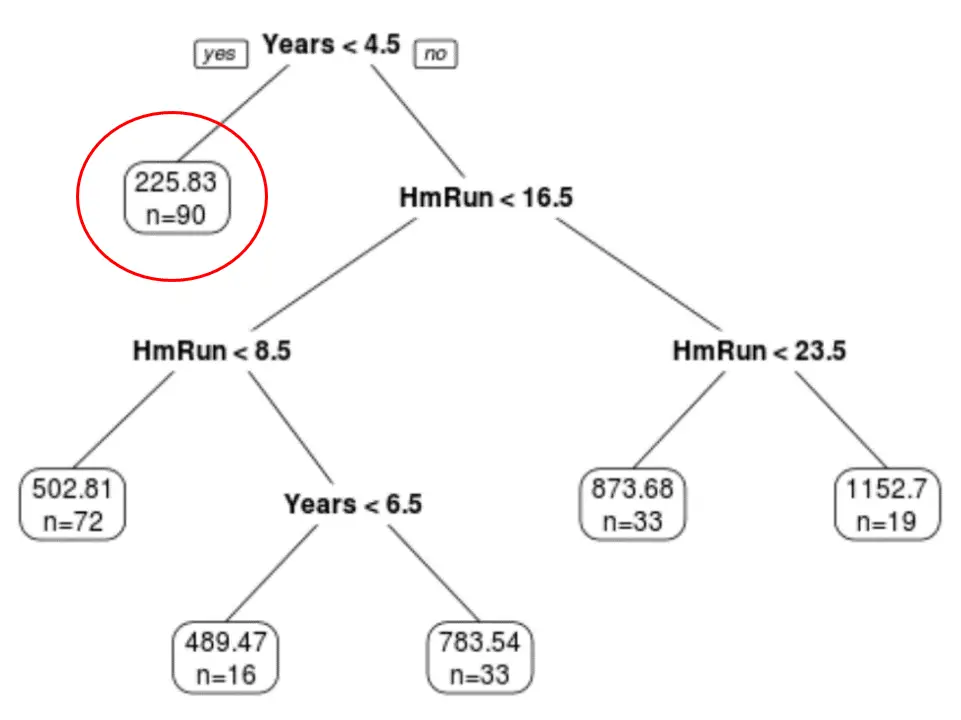
နောက်ဆုံး ဖြတ်တောက်ထားသော သစ်ပင်တွင် terminal node ခြောက်ခုပါရှိသည်ကို ကျွန်ုပ်တို့ တွေ့နိုင်ပါသည်။ အရွက် Node တစ်ခုစီသည် ထို node အတွင်းရှိ ကစားသမားများ၏ ခန့်မှန်းလစာနှင့် ထိုအဆင့်နှင့် သက်ဆိုင်သည့် မူရင်းဒေတာအတွဲမှ လေ့လာတွေ့ရှိချက်အရေအတွက်ကို ပြသသည်။
ဥပမာအားဖြင့်၊ မူရင်းဒေတာအတွဲတွင် အတွေ့အကြုံ 4.5 နှစ်အောက် ကစားသမား 90 ရှိပြီး ၎င်းတို့၏ ပျမ်းမျှလစာမှာ $225.83K ရှိကြောင်း ကျွန်ုပ်တို့တွေ့နိုင်သည်။
အဆင့် 4- ခန့်မှန်းချက်များပြုလုပ်ရန် သစ်ပင်ကိုသုံးပါ။
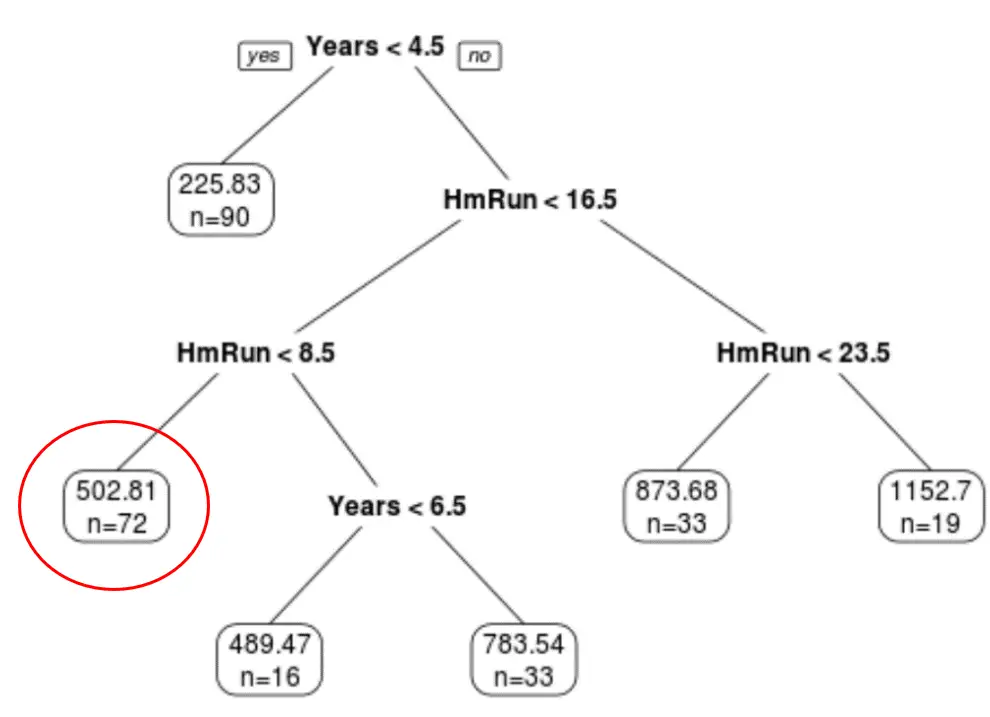
ကစားသမားတစ်ဦး၏ အတွေ့အကြုံနှစ်များနှင့် ပျမ်းမျှအိမ်ပြေးနှုန်းပေါ်မူတည်၍ ပေးထားသည့် ကစားသမား၏လစာကို ခန့်မှန်းရန် နောက်ဆုံးဖြတ်ထားသောသစ်ပင်ကို ကျွန်ုပ်တို့ အသုံးပြုနိုင်ပါသည်။
ဥပမာအားဖြင့်၊ အတွေ့အကြုံ 7 နှစ်ရှိပြီး အိမ်ကွင်း 4 ကြိမ်ပြေးသည့် ကစားသမားတစ်ဦးသည် ပျမ်းမျှလစာ $502.81k ရှိသည်။
ဒါကို အတည်ပြုဖို့ R မှာရှိတဲ့ predict() လုပ်ဆောင်ချက်ကို အသုံးပြုနိုင်ပါတယ်။
#define new player
new <- data.frame(Years=7, HmRun=4)
#use pruned tree to predict salary of this player
predict(pruned_tree, newdata=new)
502.8079
ဥပမာ 2- R တွင် အမျိုးအစားခွဲသည့်သစ်ပင်တစ်ခုတည်ဆောက်ခြင်း။
ဤဥပမာအတွက်၊ တိုက်တန်းနစ်သင်္ဘောပေါ်ရှိ ခရီးသည်များနှင့်ပတ်သက်သော အချက်အလက်အမျိုးမျိုးပါရှိသော rpart.plot ပက်ကေ့ခ်ျမှ ptitanic dataset ကို အသုံးပြုပါမည်။
ပေးထားသောခရီးသည် အသက်ရှင်ခြင်း ရှိ၊မရှိကို ခန့်မှန်းရန် အမျိုးအစား ခွဲ ခြင်း သစ်ပင်ကို ဖန်တီးရန် ဤဒေတာအတွဲကို ကျွန်ုပ်တို့အသုံးပြုပါမည်။
ဤအမျိုးအစားခွဲခြားမှုသစ်ပင်ကိုဖန်တီးရန် အောက်ပါအဆင့်များကို အသုံးပြုပါ။
အဆင့် 1- လိုအပ်သော ပက်ကေ့ခ်ျများကို တင်ပါ။
ပထမဦးစွာ၊ ဤဥပမာအတွက် လိုအပ်သော ပက်ကေ့ဂျ်များကို တင်ပေးပါမည်။
library (rpart) #for fitting decision trees library (rpart.plot) #for plotting decision trees
အဆင့် 2- ကနဦး အမျိုးအစားခွဲခြင်းသစ်ပင်ကို တည်ဆောက်ပါ။
ပထမဦးစွာ ကျွန်ုပ်တို့သည် ကြီးမားသော ကနဦးအမျိုးအစားခွဲခြားသစ်ပင်ကို တည်ဆောက်ပါမည်။ “ ရှုပ်ထွေးမှု ကန့်သတ်ဘောင်” ၏ အတိုကောက်ဖြစ်သော cp အတွက် တန်ဖိုးအနည်းငယ်ကို အသုံးပြုခြင်းဖြင့် သစ်ပင်ကြီးသည် ကျွန်ုပ်တို့ အာမခံနိုင်ပါသည်။
ဆိုလိုသည်မှာ cp ဖြင့်သတ်မှတ်ထားသော မော်ဒယ်အားလုံးသည် အနည်းဆုံးသတ်မှတ်ထားသောတန်ဖိုးဖြင့် အလုံးစုံကိုက်ညီမှုရှိသရွေ့ အမျိုးအစားခွဲခြားမှုသစ်ပင်ပေါ်တွင် နောက်ထပ်ခွဲခြမ်းမှုများကို လုပ်ဆောင်သွားမည်ဖြစ်ကြောင်း ဆိုလိုသည်။
ထို့နောက် မော်ဒယ်ရလဒ်များကို ပရင့်ထုတ်ရန် printcp() လုပ်ဆောင်ချက်ကို အသုံးပြုပါမည်။
#build the initial tree
tree <- rpart(survived~pclass+sex+age, data=ptitanic, control=rpart. control (cp= .0001 ))
#view results
printcp(tree)
Variables actually used in tree construction:
[1] age pclass sex
Root node error: 500/1309 = 0.38197
n=1309
CP nsplit rel error xerror xstd
1 0.4240 0 1.000 1.000 0.035158
2 0.0140 1 0.576 0.576 0.029976
3 0.0095 3 0.548 0.578 0.030013
4 0.0070 7 0.510 0.552 0.029517
5 0.0050 9 0.496 0.528 0.029035
6 0.0025 11 0.486 0.532 0.029117
7 0.0020 19 0.464 0.536 0.029198
8 0.0001 22 0.458 0.528 0.029035
အဆင့် 3: သစ်ပင်ကို ခုတ်ထစ်ပါ။
ထို့နောက်၊ အနိမ့်ဆုံးစမ်းသပ်မှုအမှားသို့ ဦးတည်စေသော cp (ရှုပ်ထွေးမှု ကန့်သတ်ဘောင်) အတွက် အသုံးပြုရန် အကောင်းဆုံးတန်ဖိုးကို ရှာဖွေရန် ဆုတ်ယုတ်မှုသစ်ပင်ကို ဖြတ်တောက်ပါမည်။
cp အတွက် အကောင်းဆုံးတန်ဖိုးသည် ယခင်ထွက်ရှိမှုတွင် အနိမ့်ဆုံး x-error သို့ ဦးတည်စေသည်၊ ၎င်းသည် အပြန်အလှန်စစ်ဆေးခြင်းဒေတာမှ မှတ်သားမှုများအပေါ် မှားယွင်းမှုကို ကိုယ်စားပြုကြောင်း သတိပြုပါ။
#identify best cp value to use
best <- tree$cptable[which. min (tree$cptable[," xerror "])," CP "]
#produce a pruned tree based on the best cp value
pruned_tree <- prune (tree, cp=best)
#plot the pruned tree
prp(pruned_tree,
faclen= 0 , #use full names for factor labels
extra= 1 , #display number of obs. for each terminal node
roundint= F , #don't round to integers in output
digits= 5 ) #display 5 decimal places in output
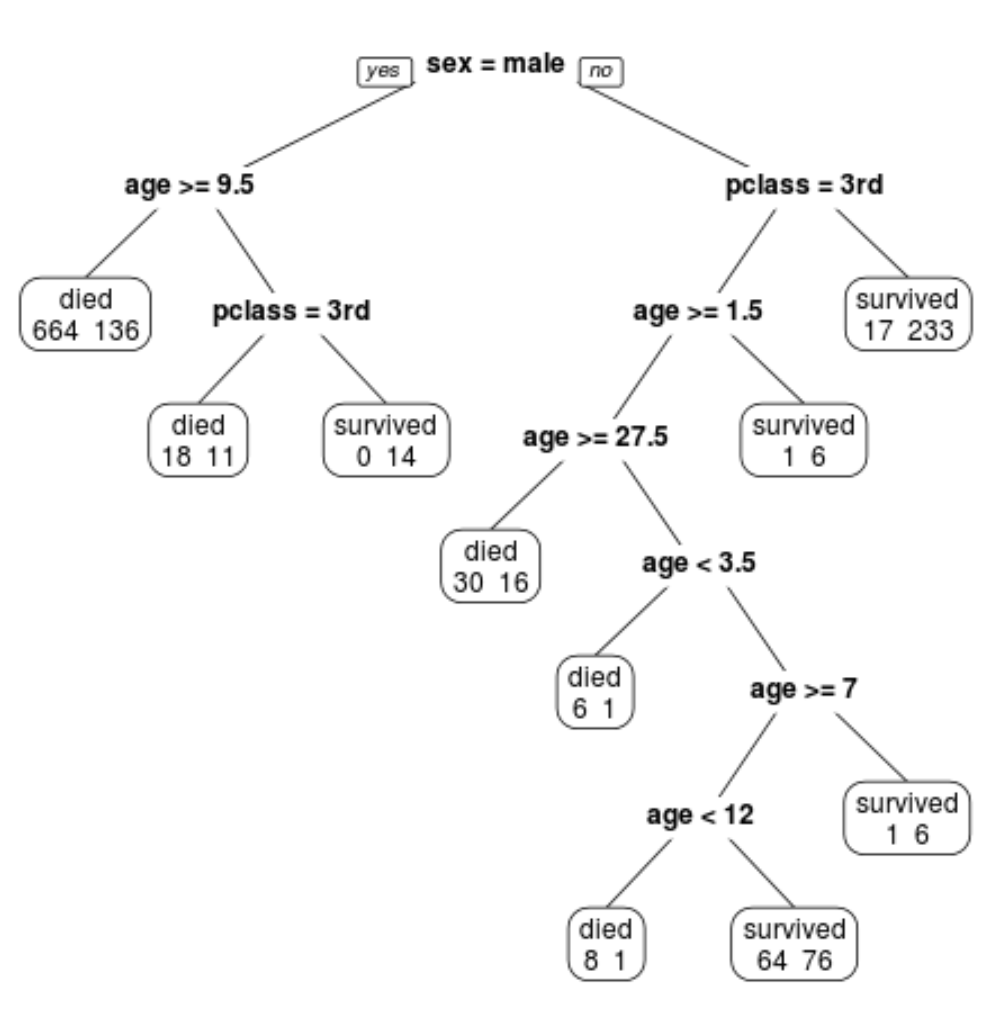
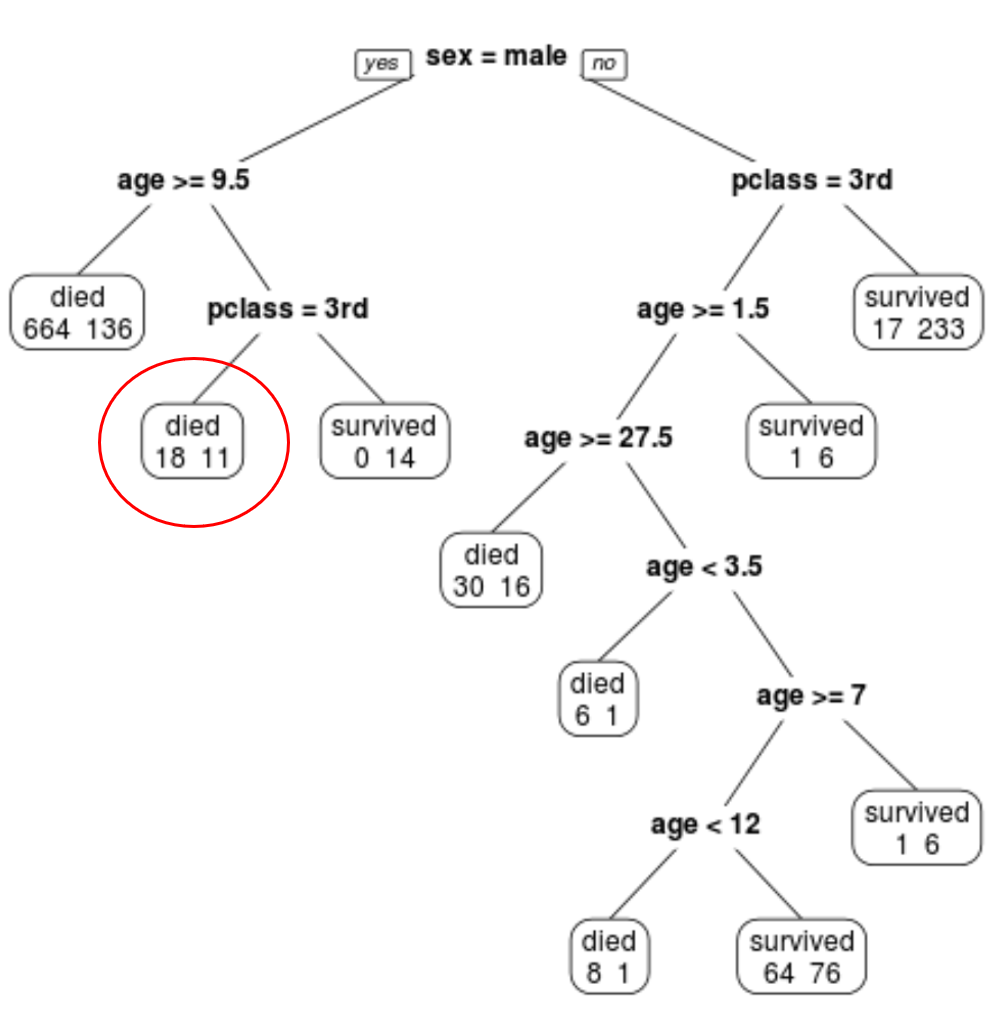
နောက်ဆုံး ဖြတ်တောက်ထားသော သစ်ပင်တွင် terminal node 10 ခု ရှိသည်ကို တွေ့နိုင်သည်။ Terminal node တစ်ခုစီသည် သေဆုံးသွားသောခရီးသည်အရေအတွက်နှင့် အသက်ရှင်ကျန်ရစ်သူအရေအတွက်ကို ညွှန်ပြသည်။
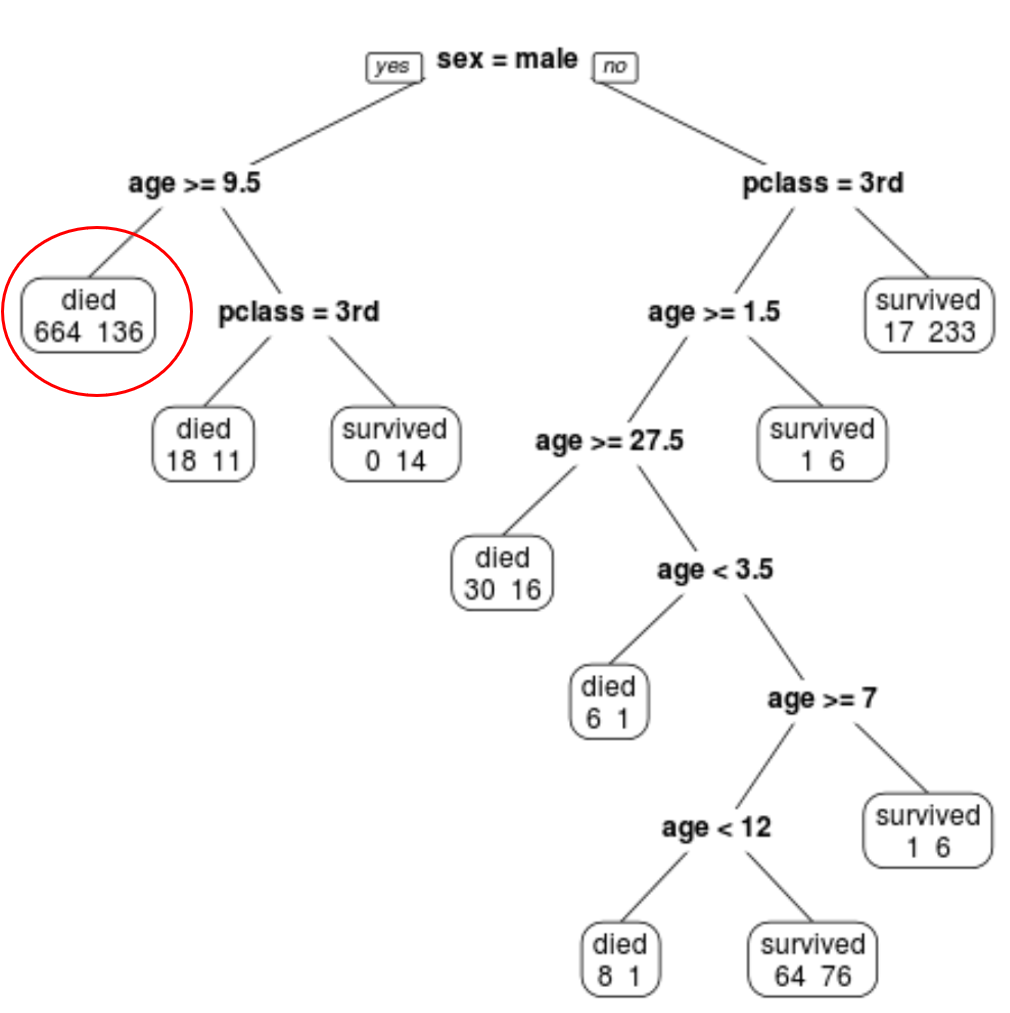
ဥပမာအားဖြင့်၊ လက်ဝဲစွန်းခုံတွင် ခရီးသည် 664 ဦး သေဆုံးပြီး 136 ဦး အသက်ရှင်ကျန်ရစ်သည်ကို ကျွန်ုပ်တို့တွေ့မြင်ရသည်။
အဆင့် 4- ခန့်မှန်းချက်များပြုလုပ်ရန် သစ်ပင်ကိုသုံးပါ။
ပေးထားသောခရီးသည် အသက်ရှင်ကျန်နိုင်ခြေကို ၎င်းတို့၏အတန်းအစား၊ အသက်နှင့် ကျား၊
ဥပမာအားဖြင့်၊ အသက် 8 နှစ်နှင့် 1st တန်းတွင် အမျိုးသားခရီးသည်တစ်ဦးသည် အသက်ရှင်ကျန်နိုင်ခြေ 11/29 = 37.9% ရှိသည်။
ဤနမူနာများတွင် အသုံးပြုထားသော R ကုဒ်အပြည့်အစုံကို ဤနေရာတွင် ရှာဖွေနိုင်ပါသည်။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။