Sas တွင် principal component analysis ကို မည်သို့လုပ်ဆောင်ရမည်နည်း
Principal component analysis (PCA) သည် အဓိက အစိတ်အပိုင်းများ – ခန့်မှန်းသူ ကိန်းရှင်များ ၏ linear ပေါင်းစပ်မှုများကို ရှာဖွေရန် ရှာဖွေသည့် ကြီးကြပ်ကွပ်ကဲမှု မရှိသော စက်သင်ယူမှု နည်းပညာတစ်ခုဖြစ်ပြီး ဒေတာအတွဲတစ်ခုအတွင်း ကွဲလွဲမှု၏ အများအပြားကို ရှင်းပြပေးပါသည်။
SAS တွင် PCA လုပ်ဆောင်ရန် အရိုးရှင်းဆုံးနည်းလမ်းမှာ အောက်ပါအခြေခံ syntax ကိုအသုံးပြုသည့် PROC PRINCOMP ထုတ်ပြန်ချက်ကို အသုံးပြုခြင်းဖြစ်သည်-
proc princomp data =my_data out =out_data outstat =stats; var var1 var2 var3; run ;
ဤသည်မှာ ညွှန်ကြားချက်တစ်ခုစီတိုင်း လုပ်ဆောင်သည်-
- ဒေတာ – PCA အတွက် အသုံးပြုရန် ဒေတာအတွဲအမည်
- out : မူရင်းဒေတာအပေါင်းနှင့် အဓိကအစိတ်အပိုင်းရမှတ်များပါရှိသော ဖန်တီးရန် ဒေတာအတွဲအမည်
- outstat : နည်းလမ်းများ၊ စံသွေဖည်မှုများ၊ ဆက်စပ်မှုကိန်းဂဏန်းများ၊ eigenvalues နှင့် eigenvectors များပါဝင်သော ဒေတာအစုံကို ဖန်တီးသင့်သည်ဟု သတ်မှတ်သည်။
- var : ထည့်သွင်းဒေတာအတွဲမှ PCA အတွက် အသုံးပြုရန် ကိန်းရှင်များ။
အောက်ဖော်ပြပါ အဆင့်ဆင့် ဥပမာသည် SAS တွင် အဓိကအစိတ်အပိုင်းများခွဲခြမ်းစိတ်ဖြာမှုကို လုပ်ဆောင်ရန် လက်တွေ့တွင် PROC PRINCOMP ထုတ်ပြန်ချက်ကို မည်သို့အသုံးပြုရမည်ကို ပြသထားသည်။
အဆင့် 1- ဒေတာအတွဲတစ်ခု ဖန်တီးပါ။
ကျွန်ုပ်တို့တွင် ဘတ်စကက်ဘောကစားသမား 20 နှင့်ပတ်သက်သည့် အချက်အလက်အမျိုးမျိုးပါဝင်သော အောက်ပါဒေတာအတွဲကို ဆိုပါစို့။
/*create dataset*/ data my_data; input points assists rebounds; datalines ; 22 8 4 29 7 3 10 4 12 5 5 15 35 6 2 8 3 10 10 4 8 8 4 3 2 5 17 4 5 19 9 9 4 7 6 4 31 5 3 4 6 13 5 7 8 8 8 4 10 4 8 20 4 6 25 8 8 18 8 3 ; run ; /*view dataset*/ proc print data =my_data;
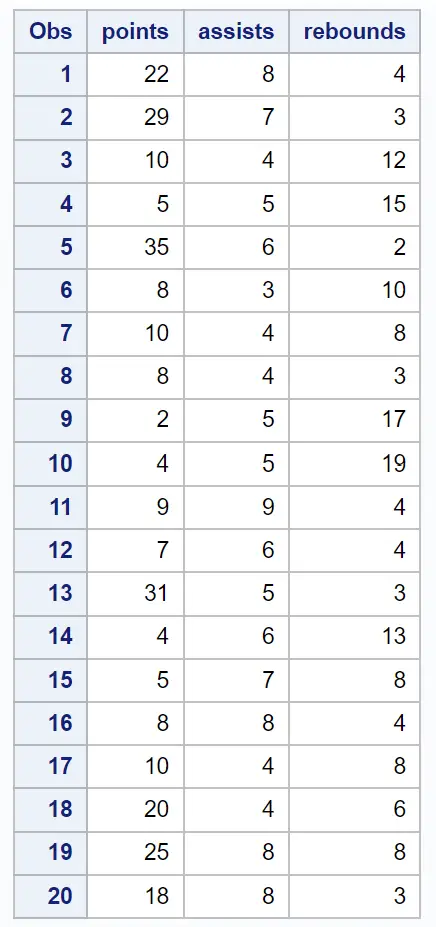
အဆင့် 2- အဓိကအစိတ်အပိုင်းများကို ခွဲခြမ်းစိတ်ဖြာပါ။
ကျွန်ုပ်တို့သည် ဒေတာအတွဲ၏ အမှတ်များ ၊ ကူညီမှုများ နှင့် ဘောင်ပြောင်းနိုင်သော ကိန်းရှင်များကို အသုံးပြုကာ PROC PRINCOMP ထုတ်ပြန်ချက်ကို အသုံးပြု၍ အဓိကအစိတ်အပိုင်းခွဲခြမ်းစိတ်ဖြာမှုကို လုပ်ဆောင်နိုင်သည်-
/*perform principal components analysis*/ proc princomp data =my_data out =out_data outstat =stats; var points assists rebounds; run ;
output ၏ပထမပိုင်းသည် input variable တစ်ခုစီ၏ပျမ်းမျှနှင့်စံသွေဖည်မှုများအပါအဝင် အမျိုးမျိုးသောသရုပ်ဖော်ကိန်းဂဏန်းအချက်အလက်များကိုပြသသည်-
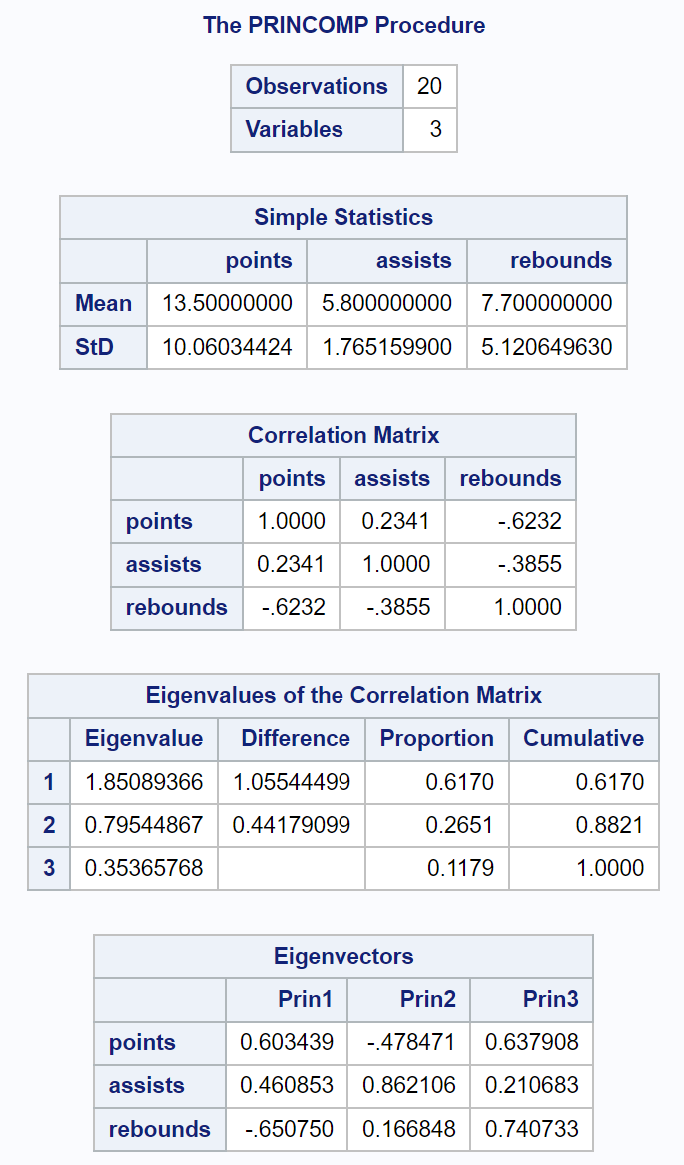
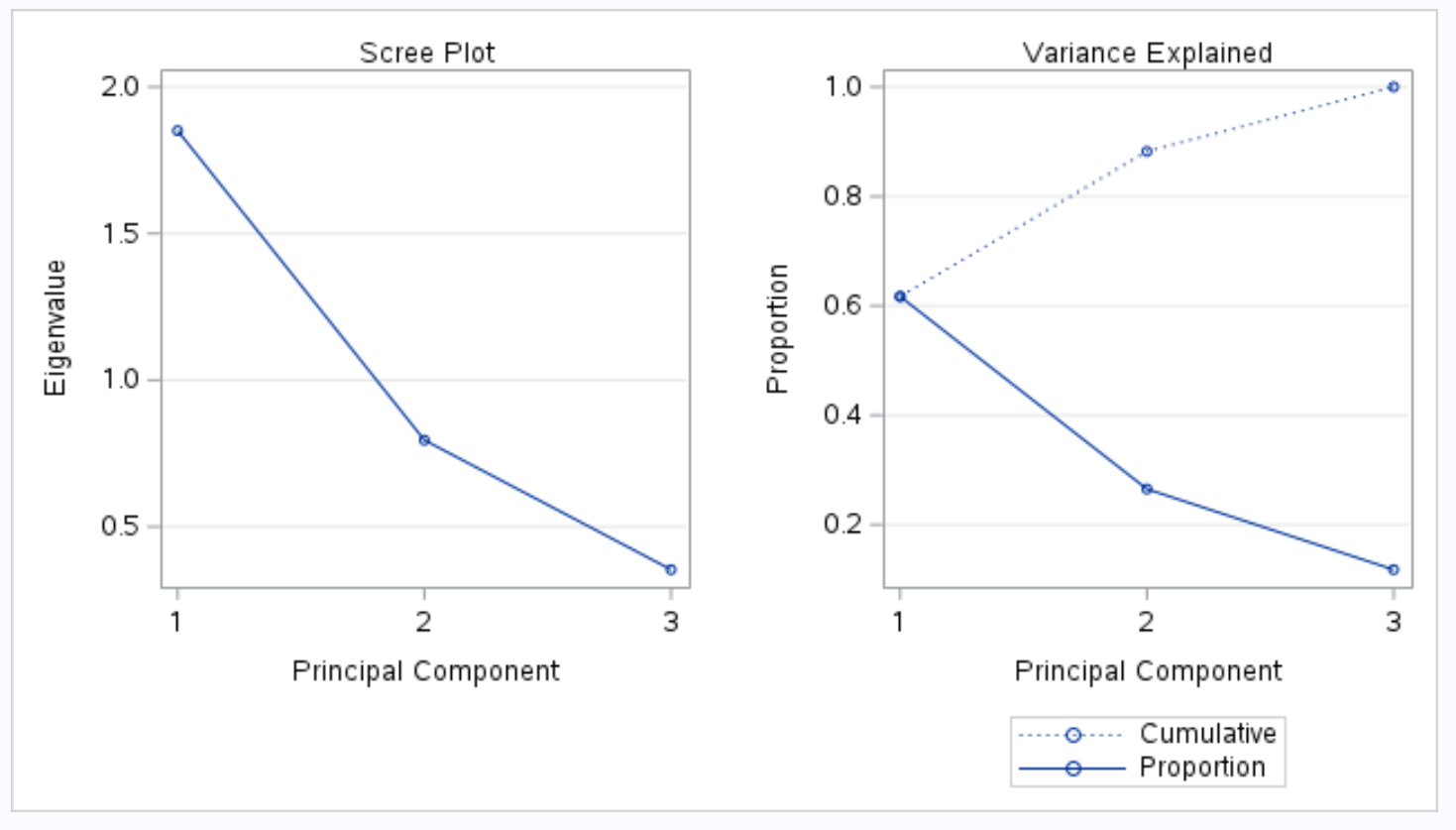
output ၏နောက်အပိုင်းသည် scree plot နှင့် ရှင်းပြထားသော varianance plot ကိုပြသသည်-
ကျွန်ုပ်တို့ PCA ကိုလုပ်ဆောင်သောအခါ၊ ကျွန်ုပ်တို့သည် ဒေတာအတွဲတစ်ခုစီတွင် အဓိကအစိတ်အပိုင်းတစ်ခုစီမှ ရှင်းပြနိုင်သည့် စုစုပေါင်းကွဲလွဲမှုရာခိုင်နှုန်းကို မကြာခဏနားလည်လိုပါသည်။
Correlation Matrix Eigenvalues ခေါင်းစဉ်တပ်ထားသော ရလဒ်ဇယားသည် ကျွန်ုပ်တို့အား အဓိကအစိတ်အပိုင်းတစ်ခုစီမှ ရှင်းပြထားသည့် စုစုပေါင်းကွဲလွဲမှု၏ ရာခိုင်နှုန်းမည်မျှရာခိုင်နှုန်းကို အတိအကျမြင်နိုင်စေသည်-
- ပထမအဓိကအစိတ်အပိုင်းသည် ဒေတာအတွဲတွင် စုစုပေါင်းကွဲလွဲမှု၏ 61.7% ကို ရှင်းပြထားသည်။
- ဒုတိယအဓိကအစိတ်အပိုင်းသည် ဒေတာအတွဲရှိ စုစုပေါင်းကွဲလွဲမှု၏ 26.51% ကို ရှင်းပြထားသည်။
- တတိယ အဓိက အစိတ်အပိုင်းသည် ဒေတာအတွဲတွင် စုစုပေါင်းကွဲလွဲမှု 11.79% ကို ရှင်းပြထားသည်။
ရာခိုင်နှုန်းအားလုံး 100% အထိ ပေါင်းထည့်ကြောင်း သတိပြုပါ။
Variance Explained ဟူသော ဇာတ်ကွက်သည် ကျွန်ုပ်တို့အား ဤတန်ဖိုးများကို မြင်ယောင်နိုင်စေပါသည်။
x-axis သည် အဓိကအစိတ်အပိုင်းကိုပြသပြီး y-axis သည် အဓိကအစိတ်အပိုင်းတစ်ခုစီမှ ရှင်းပြထားသော စုစုပေါင်းကွဲလွဲမှုရာခိုင်နှုန်းကို ပြသသည်။
အဆင့် 3- ရလဒ်များကိုမြင်ယောင်ရန် biplot တစ်ခုဖန်တီးပါ။
ပေးထားသည့်ဒေတာအတွဲတစ်ခုအတွက် PCA ၏ရလဒ်များကိုမြင်ယောင်နိုင်ရန်၊ ပထမအဓိကအစိတ်အပိုင်းနှစ်ခုဖြင့်ဖွဲ့စည်းထားသောလေယာဉ်ပေါ်ရှိ dataset တစ်ခုစီတွင်ကြည့်ရှုမှုတစ်ခုစီကိုပြသသည့် biplot တစ်ခုကိုဖန်တီးနိုင်သည်။
biplot တစ်ခုကို ဖန်တီးရန် SAS တွင် အောက်ပါ syntax ကို အသုံးပြုနိုင်ပါသည်။
/*create dataset with column called obs to represent row numbers of original data*/
data biplot_data;
set out_data;
obs=_n_;
run ;
/*create biplot using values from first two principal components*/
proc sgplot data =biplot_data;
scatter x =Prin1 y =Prin2 / datalabel =obs;
run ;
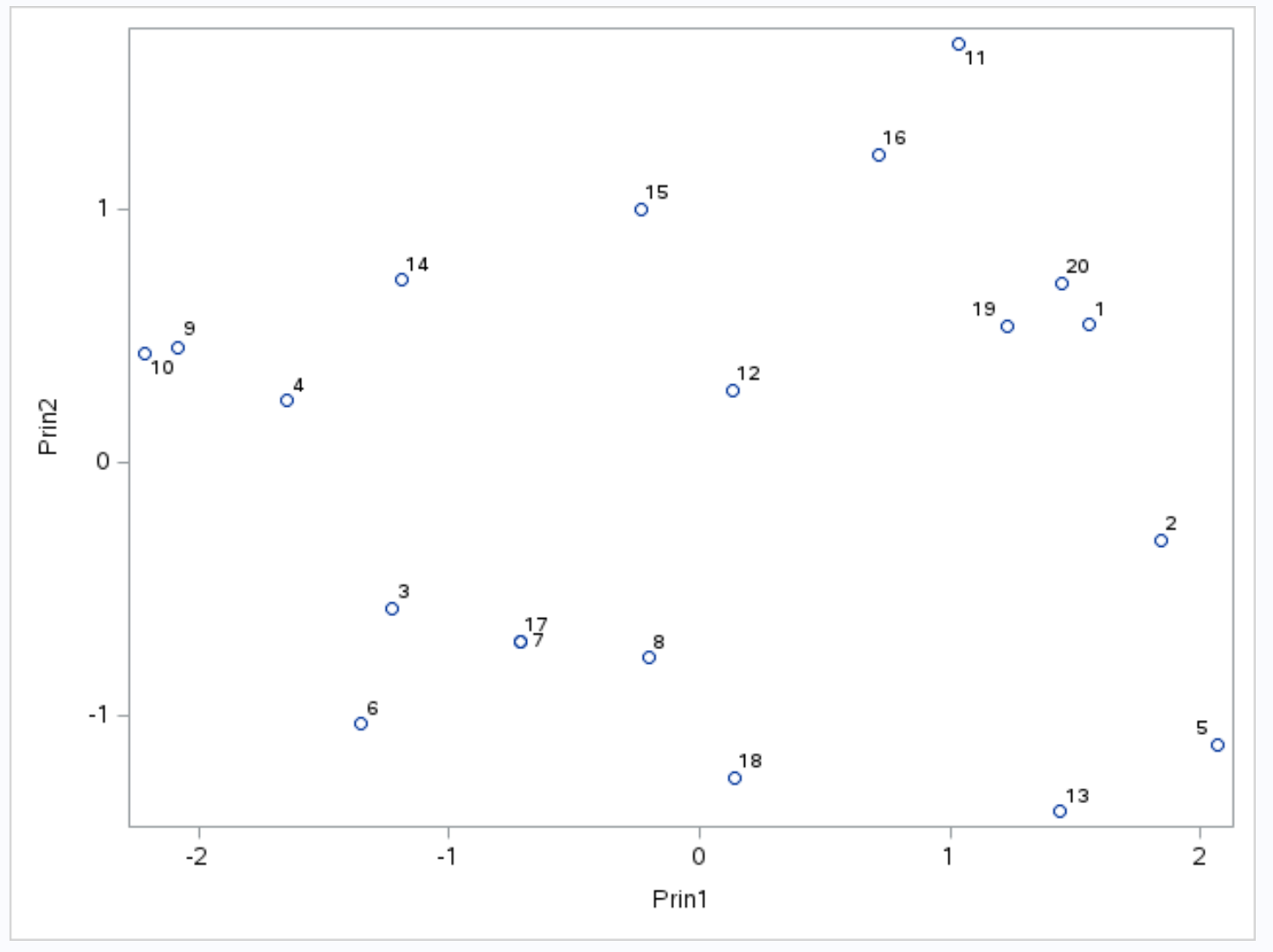
x-axis သည် ပထမအဓိကအစိတ်အပိုင်းကိုပြသသည်၊ y-axis သည် ဒုတိယအဓိကအစိတ်အပိုင်းကိုပြသပြီး dataset မှတစ်ဦးချင်းစီ လေ့လာတွေ့ရှိချက်များကို ဂရပ်အတွင်းတွင် စက်ဝိုင်းငယ်များအဖြစ်ပြသပါသည်။
ဂရပ်ပေါ်တွင် ဘေးချင်းကပ်လျက် ရှိနေသော လေ့လာတွေ့ရှိချက်များသည် အမှတ်များ ၊ assists နှင့် rebounds သုံးခုအတွက် အလားတူတန်ဖိုးများရှိသည်။
ဥပမာအားဖြင့်၊ ဂရပ်၏ဘယ်ဘက်အစွန်တွင်၊ #9 နှင့် #10 တို့သည် တစ်ခုနှင့်တစ်ခု အလွန်နီးကပ်နေကြောင်း ကျွန်ုပ်တို့တွေ့မြင်နိုင်ပါသည်။
မူရင်းဒေတာအတွဲကို ကိုးကားပါက၊ ဤလေ့လာတွေ့ရှိချက်များအတွက် အောက်ပါတန်ဖိုးများကို ကျွန်ုပ်တို့ မြင်တွေ့နိုင်သည်-
- Observation n°9 : 2 မှတ်၊ 5 assists ၊ 17 rebounds
- အကဲဖြတ်ချက် #10 : 4 မှတ်၊ 5 ကြိမ်၊ 19 ပြန်ခုန်
တန်ဖိုးများသည် ကိန်းရှင် သုံးခုမှ တစ်ခုစီအတွက် ဆင်တူသည်၊ ၎င်းသည် biplot တွင် ဤလေ့လာတွေ့ရှိချက်များသည် တစ်ခုနှင့်တစ်ခု အဘယ်ကြောင့် အလွန်နီးကပ်နေကြောင်း ရှင်းပြသည်။
Correlation Matrix Eigenvalues ခေါင်းစဉ်တပ်ထားသော ရလဒ်ဇယားတွင် ပထမအဓိကအစိတ်အပိုင်းနှစ်ခုသည် ဒေတာအတွဲရှိ စုစုပေါင်းကွဲလွဲမှု၏ 88.21% ဖြစ်သည်ကို ကျွန်ုပ်တို့တွေ့ခဲ့ရသည်။
ဤရာခိုင်နှုန်းသည် အလွန်မြင့်မားသောကြောင့်၊ biplot တွင် မည်သည့်လေ့လာတွေ့ရှိချက်များသည် တစ်ခုနှင့်တစ်ခု နီးကပ်နေသည်၊ အကြောင်းမှာ biplot တွင်ပါဝင်သည့် အဓိကအစိတ်အပိုင်းနှစ်ခုသည် dataset တွင်ကွဲလွဲမှုအားလုံးနီးပါးအတွက် ခွဲခြမ်းစိတ်ဖြာရန် မှန်ကန်ပါသည်။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် SAS တွင် အခြားဘုံအလုပ်များကို မည်သို့လုပ်ဆောင်ရမည်ကို ရှင်းပြသည်-
SAS တွင် ရိုးရှင်းသော linear regression လုပ်ဆောင်နည်း
SAS တွင် မျဉ်းကြောင်းပြန်ဆုတ်ခြင်းများစွာကို မည်သို့လုပ်ဆောင်ရမည်နည်း။
SAS တွင် logistic regression ကိုမည်သို့လုပ်ဆောင်ရမည်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။