Sas တွင် ရိုးရှင်းသော linear regression လုပ်ဆောင်နည်း
Simple linear regression သည် ကြိုတင်ခန့်မှန်းကိန်းရှင်နှင့် တုံ့ပြန်မှုကိန်းရှင် ကြား ဆက်နွယ်မှုကို နားလည်ရန် ကျွန်ုပ်တို့ အသုံးပြုနိုင်သည့် နည်းလမ်းတစ်ခုဖြစ်သည်။
ဤနည်းပညာသည် ဒေတာကို အကောင်းဆုံး “ အံဝင်ခွင်ကျ” သော မျဉ်းတစ်ကြောင်းကို ရှာဖွေပြီး အောက်ပါပုံစံကို ရယူသည်-
ŷ = b 0 + b 1 x
ရွှေ-
- ŷ : ခန့်မှန်းတုံ့ပြန်မှုတန်ဖိုး
- b 0 : ဆုတ်ယုတ်မှုမျဉ်း၏ မူလအစ
- b 1 : ဆုတ်ယုတ်မှုမျဉ်း၏ လျှောစောက်
ဤညီမျှခြင်းသည် ခန့်မှန်းသူကိန်းရှင်နှင့် တုံ့ပြန်မှုကိန်းရှင်ကြား ဆက်နွယ်မှုကို နားလည်ရန် ကူညီပေးသည်။
အောက်ဖော်ပြပါ အဆင့်ဆင့် ဥပမာသည် SAS တွင် ရိုးရှင်းသော မျဉ်းကြောင်းပြန်ဆုတ်ခြင်းကို မည်သို့လုပ်ဆောင်ရမည်ကို ပြသထားသည်။
အဆင့် 1: ဒေတာကိုဖန်တီးပါ။
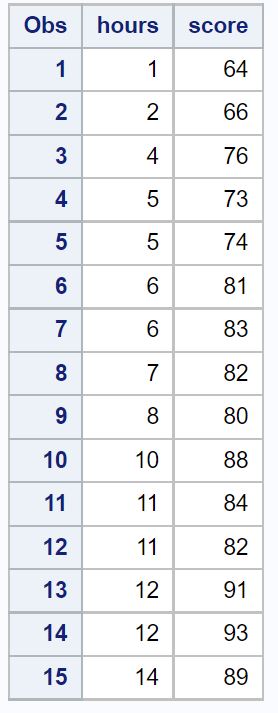
ဤဥပမာအတွက်၊ ကျွန်ုပ်တို့သည် ကျောင်းသား 15 ဦး၏ နောက်ဆုံးစာမေးပွဲဖြေဆိုချိန်နှင့် နောက်ဆုံးစာမေးပွဲအဆင့် ပါဝင်သော ဒေတာအတွဲတစ်ခုကို ဖန်တီးပါမည်။
ကြိုတင်ခန့်မှန်းကိန်းရှင်ကိန်းရှင်နှင့် တုံ့ပြန်မှုကိန်းရှင်အဖြစ် ရမှတ် အဖြစ် နာရီများကို အသုံးပြု၍ ရိုးရှင်းသောမျဉ်းကြောင်းဆုတ်ယုတ်မှုပုံစံကို ကျွန်ုပ်တို့ ဖြည့်ဆည်းပေးပါမည်။
အောက်ပါကုဒ်သည် ဤဒေတာအတွဲကို SAS တွင် မည်သို့ဖန်တီးရမည်ကို ပြသသည်-
/*create dataset*/ data exam_data; input hours score; datalines ; 1 64 2 66 4 76 5 73 5 74 6 81 6 83 7 82 8 80 10 88 11 84 11 82 12 91 12 93 14 89 ; run ; /*view dataset*/ proc print data =exam_data;
အဆင့် 2- ရိုးရှင်းသော linear regression model ကို ကိုက်ညီပါ။
ထို့နောက်၊ ရိုးရှင်းသော linear regression model နှင့်ကိုက်ညီရန် proc reg ကို အသုံးပြုပါမည်။
/*fit simple linear regression model*/ proc reg data =exam_data; model score = hours; run ;
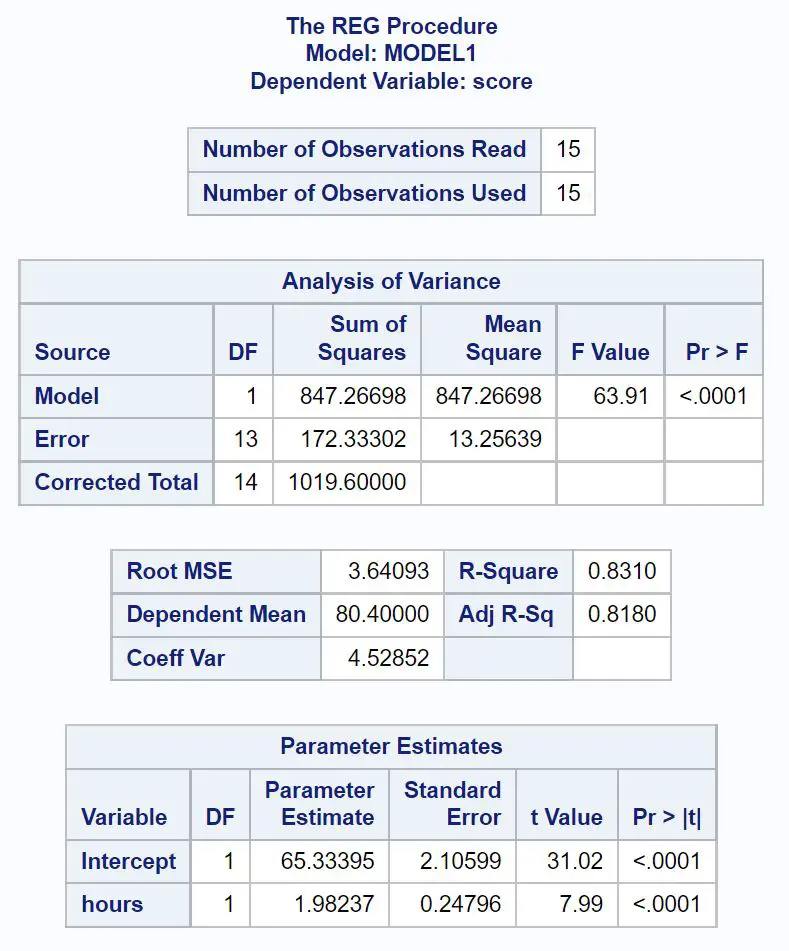
ရလဒ်တွင် ဇယားတစ်ခုစီမှ အရေးကြီးဆုံးတန်ဖိုးများကို အဓိပ္ပာယ်ဖွင့်ဆိုပုံမှာ အောက်ပါအတိုင်းဖြစ်သည်။
ကွာဟချက် ခွဲခြမ်းစိတ်ဖြာ ဇယား-
ဆုတ်ယုတ်မှုမော်ဒယ်၏ အလုံးစုံ F-တန်ဖိုး သည် 63.91 ဖြစ်ပြီး သက်ဆိုင်ရာ p-တန်ဖိုးမှာ <0.0001 ဖြစ်သည်။
ဤ p-value သည် 0.05 ထက်နည်းသောကြောင့်၊ regression model တစ်ခုလုံးသည် စာရင်းအင်းအရ သိသာထင်ရှားသည်ဟု ကျွန်ုပ်တို့ကောက်ချက်ချပါသည်။ တစ်နည်းအားဖြင့်ဆိုရသော် နာရီများသည် စာမေးပွဲရလဒ်များကို ခန့်မှန်းရန်အတွက် အသုံးဝင်သောပြောင်းလဲမှုတစ်ခုဖြစ်သည်။
မော်ဒယ်အံစာစားပွဲ
R-Square တန်ဖိုးသည် လေ့လာသည့် နာရီအရေအတွက်ဖြင့် ရှင်းပြနိုင်သည့် စာမေးပွဲရမှတ်များတွင် ကွဲလွဲမှုရာခိုင်နှုန်းကို ပြောပြသည်။
ယေဘူယျအားဖြင့်၊ regression model တစ်ခု၏ R-squared တန်ဖိုး ပိုကြီးလေ၊ ခန့်မှန်းသူ variable များသည် တုံ့ပြန်မှု variable ၏ တန်ဖိုးကို ခန့်မှန်းရာတွင် ပိုကောင်းလေဖြစ်သည်။
ဤကိစ္စတွင်၊ စာမေးပွဲရမှတ်များ ကွဲလွဲမှု၏ 83.1% ကို လေ့လာသည့် နာရီအရေအတွက်ဖြင့် ရှင်းပြနိုင်သည်။ ဤတန်ဖိုးသည် အလွန်မြင့်မားပြီး စာမေးပွဲရလဒ်များကို ခန့်မှန်းရာတွင် အလွန်အသုံးဝင်သော ကိန်းရှင်ဖြစ်ကြောင်း ညွှန်ပြပါသည်။
ကန့်သတ်ချက် ခန့်မှန်းချက်ဇယား-
ဤဇယားမှ တပ်ဆင်ထားသော ဆုတ်ယုတ်မှုညီမျှခြင်းကို ကျွန်ုပ်တို့ မြင်တွေ့နိုင်သည်-
ရမှတ် = 65.33 + 1.98*(နာရီ)
ထပ်လောင်းလေ့လာထားသောနာရီတိုင်းသည် စာမေးပွဲရမှတ်တွင် ပျမ်းမျှ 1.98 မှတ် တိုးလာခြင်းနှင့် ဆက်စပ်နေသည်ဟု ဆိုလိုခြင်းဖြစ်သည်ဟု ကျွန်ုပ်တို့ ဆိုလိုပါသည်။
မူရင်းတန်ဖိုးက သုညနာရီစာလေ့လာနေတဲ့ ကျောင်းသားတစ်ယောက်အတွက် ပျမ်းမျှစာမေးပွဲရမှတ်က 65.33 ဖြစ်တယ်လို့ ပြောထားပါတယ်။
ကျောင်းသားတစ်ဦး၏လေ့လာမှုနာရီအရေအတွက်အပေါ်အခြေခံ၍မျှော်လင့်ထားသောစာမေးပွဲရမှတ်ကိုရှာဖွေရန်ဤညီမျှခြင်းကိုလည်းအသုံးပြုနိုင်သည်။
ဥပမာအားဖြင့်၊ 10 နာရီကြာလေ့လာသော ကျောင်းသားသည် စာမေးပွဲရမှတ် 85.13 ရရှိသင့်သည် ။
ရမှတ် = 65.33 + 1.98*(10) = 85.13
နာရီ များအတွက် p-value (<0.0001) သည် ဤဇယားတွင် 0.05 ထက်နည်းသောကြောင့်၊ ၎င်းသည် ကိန်းဂဏန်းဆိုင်ရာ သိသာထင်ရှားသော ခန့်မှန်းပေးသူကိန်းရှင်ဖြစ်ကြောင်း ကျွန်ုပ်တို့ ကောက်ချက်ချပါသည်။
အဆင့် 3- ကျန်ရှိသောမြေကွက်များကို ပိုင်းခြားစိတ်ဖြာပါ။
ရိုးရှင်းသော linear regression သည် model အကြွင်းအကျန်များ နှင့် ပတ်သက်၍ အရေးကြီးသော ယူဆချက် နှစ်ခုကို ဖြစ်စေသည် ။
- အကြွင်းအကျန်များကို ပုံမှန်အတိုင်း ဖြန့်ဝေသည်။
- အကြွင်းအကျန်များသည် ကြိုတင်ခန့်မှန်းကိန်းရှင်၏ အဆင့်တစ်ခုစီတွင် တူညီသောကွဲလွဲမှု (“ homoscedasticity ”) ရှိသည်။
ဤယူဆချက်များနှင့် မကိုက်ညီပါက၊ ကျွန်ုပ်တို့၏ ဆုတ်ယုတ်မှုပုံစံ၏ ရလဒ်များသည် ယုံကြည်စိတ်ချနိုင်မည်မဟုတ်ပေ။
ဤယူဆချက်များနှင့် ကိုက်ညီကြောင်း အတည်ပြုရန်အတွက် SAS အထွက်တွင် အလိုအလျောက်ပြသသည့် ကျန်နေသောကွက်များကို ပိုင်းခြားစိတ်ဖြာနိုင်ပါသည်-
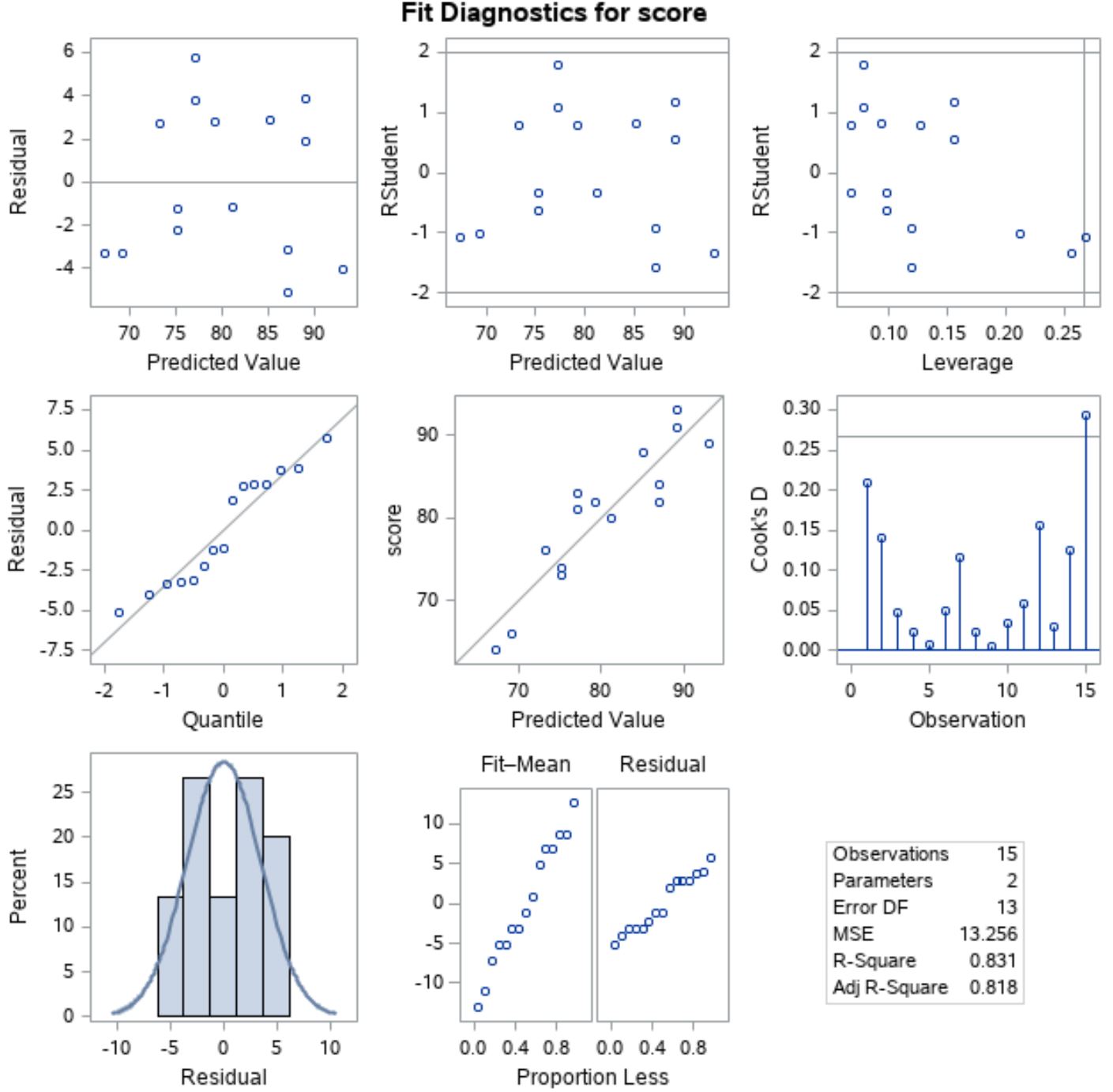
အကြွင်းအကျန်များကို ပုံမှန်ဖြန့်ဝေ ကြောင်း အတည်ပြုရန်၊ y-ဝင်ရိုးတစ်လျှောက် “ Quantile” ဖြင့် အလယ်မျဉ်း၏ ဘယ်ဘက်တွင် ကွက်ကွက်ကို ပိုင်းခြားစိတ်ဖြာနိုင်ပါသည်။
ဤကွက်ကွက်ကို QQ plot ဟုခေါ်သည်၊ “ quantile-quantile” ၏ အတိုကောက်ဖြစ်ပြီး ဒေတာကို ပုံမှန်ဖြန့်ဝေခြင်း ရှိ၊ မရှိ ဆုံးဖြတ်ရန် အသုံးပြုသည်။ ဒေတာကို ပုံမှန်အတိုင်း ဖြန့်ဝေပါက၊ QQ ကွက်ကွက်ရှိ အမှတ်များသည် ဖြောင့်သောထောင့်ဖြတ်မျဉ်းပေါ်တွင် ရှိနေမည်ဖြစ်သည်။
ဂရပ်မှ အမှတ်များသည် ဖြောင့်ထောင့်ဖြတ်မျဉ်းတစ်လျှောက် အကြမ်းဖျင်း တည်ရှိနေသည်ကို တွေ့နိုင်သောကြောင့် ကျန်အကြွင်းများကို ပုံမှန်အတိုင်း ဖြန့်ဝေသည်ဟု ကျွန်ုပ်တို့ ယူဆနိုင်ပါသည်။
ဆက်လက်၍ ကျန်ရှိသောအရာများသည် homoscedastic ဖြစ်ကြောင်းစစ်ဆေးရန်၊ y-ဝင်ရိုးတစ်လျှောက် “ Predicted value” ဖြင့် ပထမတန်း၏ဘယ်ဘက်အနေအထားတွင် ကွက်ကွက်ကို ကြည့်ရှုနိုင်ပါသည်။
ကွက်ကွက်အမှတ်များသည် ရှင်းရှင်းလင်းလင်းမရှိသော ပုံစံမရှိဘဲ သုညတွင် ကျပန်းကျပန်း ပြန့်ကျဲနေပါက အကြွင်းအကျန်များသည် homoskeastic ဖြစ်သည်ဟု ကျွန်ုပ်တို့ ယူဆနိုင်ပါသည်။
ကွက်ကွက်မှ အမှတ်များကို သုညတွင် ကျပန်းကျပန်း ဖြန့်ကျက်ထားသည်ကို ကွက်ကွက်တစ်လျှောက် အဆင့်တစ်ခုစီတွင် အနီးစပ်ဆုံး တူညီသောကွဲလွဲမှုဖြင့် သုညတွင် ပြန့်ကျဲနေသည်ကို တွေ့နိုင်သည်၊ ထို့ကြောင့် ကျန်သည့်အရာများသည် တစ်သားတည်းဖြစ်နေကြောင်း ကျွန်ုပ်တို့ ယူဆနိုင်သည်။
ယူဆချက်နှစ်ခုလုံးကို လိုက်လျောညီထွေဖြစ်စေသောကြောင့်၊ ရိုးရှင်းသော linear regression model ၏ရလဒ်များသည် ယုံကြည်စိတ်ချရသည်ဟု ကျွန်ုပ်တို့ ယူဆနိုင်ပါသည်။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် SAS တွင် အခြားဘုံအလုပ်များကို မည်သို့လုပ်ဆောင်ရမည်ကို ရှင်းပြသည်-
SAS တွင် one-way ANOVA လုပ်ဆောင်နည်း
SAS တွင် နှစ်လမ်းသွား ANOVA လုပ်ဆောင်နည်း
SAS တွင် ဆက်စပ်မှုကို တွက်ချက်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။