Beslissingsboom versus willekeurige forests: wat is het verschil?
Een beslissingsboom is een type machine learning-model dat wordt gebruikt wanneer de relatie tussen een reeks voorspellende variabelen en een responsvariabele niet-lineair is.
Het basisidee achter een beslissingsboom is het construeren van een „boom“ met behulp van een reeks voorspellende variabelen die de waarde van een responsvariabele voorspelt met behulp van beslissingsregels.
We kunnen bijvoorbeeld de voorspellende variabelen ‘gespeelde jaren’ en ‘gemiddelde homeruns’ gebruiken om het jaarsalaris van professionele honkbalspelers te voorspellen.
Met behulp van deze dataset zou het beslisboommodel er zo uit kunnen zien:
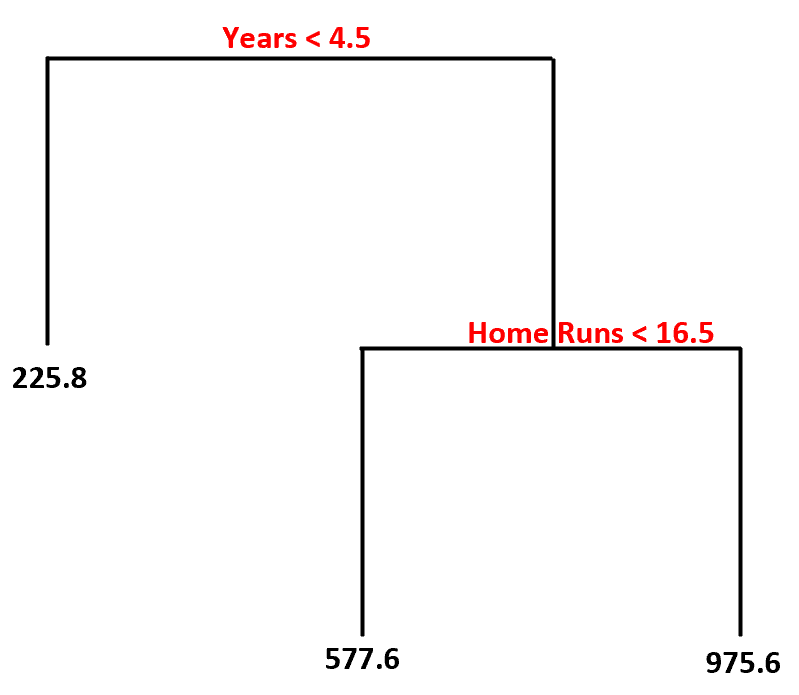
Hier ziet u hoe we deze beslisboom zouden interpreteren:
- Spelers die minder dan 4,5 jaar hebben gespeeld, hebben een verwacht salaris van $225,8k .
- Spelers die gemiddeld meer dan 4,5 jaar of langer en minder dan 16,5 homeruns hebben gespeeld, hebben een verwacht salaris van $577,6K .
- Spelers met 4,5 jaar of meer ervaring en gemiddeld 16,5 of meer homeruns hebben een verwacht salaris van $975,6K .
Het belangrijkste voordeel van een beslisboom is dat deze snel kan worden aangepast aan een dataset en dat het uiteindelijke model duidelijk kan worden gevisualiseerd en geïnterpreteerd met behulp van een „boomdiagram“ zoals hierboven.
Het belangrijkste nadeel is dat een beslissingsboom de neiging heeft om een trainingsdataset te overbelasten , wat betekent dat deze waarschijnlijk slecht presteert op onzichtbare gegevens. Dit kan ook sterk worden beïnvloed door uitbijters in de dataset.
Een uitbreiding van de beslissingsboom is een model dat bekend staat als willekeurig bos , wat in wezen een reeks beslissingsbomen is.
Dit zijn de stappen die we gebruiken om een willekeurig bosmodel te maken:
1. Neem bootstrap-voorbeelden uit de originele dataset.
2. Maak voor elke bootstrapsteekproef een beslissingsboom met behulp van een willekeurige subset van voorspellende variabelen.
3. Gemiddelde van de voorspellingen van elke boom om een definitief model te verkrijgen.
Het voordeel van willekeurige forests is dat ze veel beter presteren dan beslisbomen op ongeziene gegevens en minder gevoelig zijn voor uitschieters.
Het nadeel van willekeurige forests is dat er geen manier is om het uiteindelijke model te visualiseren en dat het bouwen ervan lang kan duren als je niet over voldoende rekenkracht beschikt of als de dataset waarmee je werkt extreem omvangrijk is.
Voor- en nadelen: beslisbomen vs. Willekeurige bossen
De volgende tabel vat de voor- en nadelen van beslissingsbomen samen in vergelijking met willekeurige bossen:
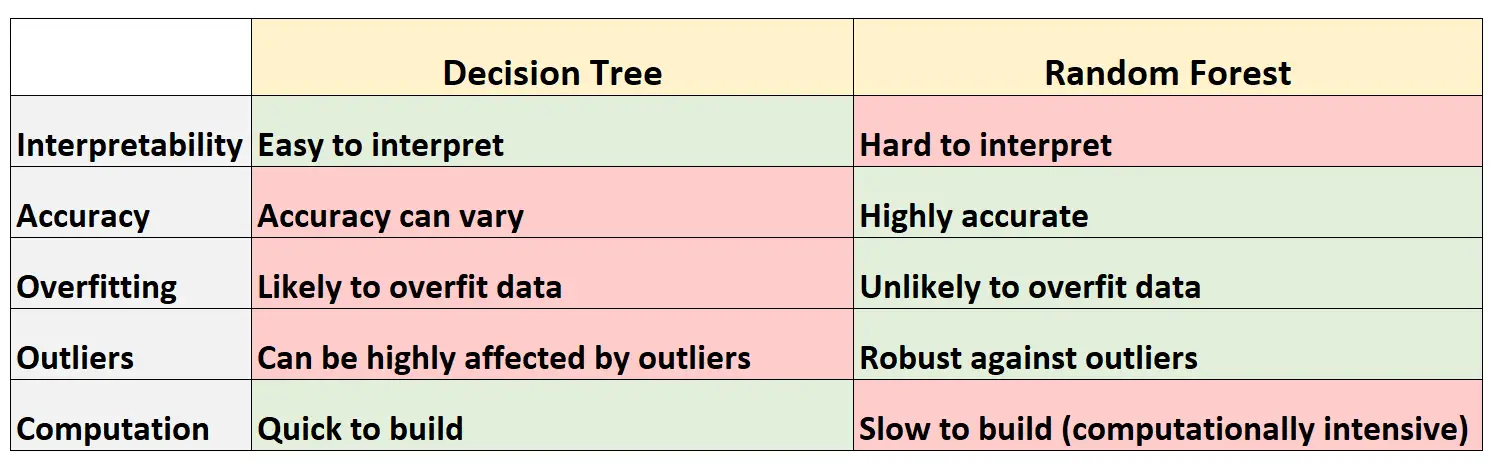
Hier volgt een korte uitleg van elke rij in de tabel:
1. Interpreteerbaarheid
Beslisbomen zijn gemakkelijk te interpreteren omdat we een boomdiagram kunnen maken om het uiteindelijke model te visualiseren en te begrijpen.
Omgekeerd kunnen we geen willekeurig bos visualiseren en kan het vaak moeilijk zijn om te begrijpen hoe het uiteindelijke willekeurige bosmodel beslissingen neemt.
2. Nauwkeurigheid
Omdat beslissingsbomen waarschijnlijk een trainingsdataset overbelasten, presteren ze doorgaans slechter op onzichtbare datasets.
Omgekeerd zijn willekeurige forests doorgaans zeer nauwkeurig op onzichtbare datasets, omdat ze voorkomen dat trainingsdatasets overmatig worden aangepast.
3. Overfitting
Zoals eerder vermeld passen beslissingsbomen vaak te veel trainingsgegevens toe: dit betekent dat ze zich waarschijnlijk zullen aanpassen aan de „ruis“ van een dataset, in tegenstelling tot het echte onderliggende model.
Omgekeerd, omdat willekeurige bossen alleen bepaalde voorspellende variabelen gebruiken om elke individuele beslissingsboom te construeren, zijn de uiteindelijke bomen vaak gedecoreerd, wat betekent dat het onwaarschijnlijk is dat willekeurige bosmodellen datasets overbelasten.
4. Uitschieters
Beslisbomen zijn zeer gevoelig voor beïnvloeding door uitschieters.
Omgekeerd, omdat een willekeurig bosmodel veel individuele beslissingsbomen bouwt en vervolgens het gemiddelde van de voorspellingen uit die bomen neemt, is de kans veel kleiner dat het wordt beïnvloed door uitschieters.
5. Berekening
Beslisbomen kunnen snel worden aangepast aan datasets.
Omgekeerd zijn willekeurige forests veel rekenintensiever en kan het lang duren om ze te creëren, afhankelijk van de grootte van de dataset.
Wanneer beslisbomen of willekeurige bossen gebruiken?
Over het algemeen:
U moet een beslisboom gebruiken als u snel een niet-lineair model wilt maken en gemakkelijk wilt kunnen interpreteren hoe het model beslissingen neemt.
U moet echter een willekeurig forest gebruiken als u over veel rekenkracht beschikt en een model wilt maken dat waarschijnlijk zeer nauwkeurig is, zonder dat u zich zorgen hoeft te maken over de interpretatie van het model.
In de echte wereld gebruiken machine learning-ingenieurs en datawetenschappers vaak willekeurige forests omdat ze zeer nauwkeurig zijn en moderne computers en systemen vaak grote datasets kunnen verwerken die voorheen niet konden worden verwerkt.
Aanvullende bronnen
De volgende tutorials bieden een inleiding tot beslissingsbomen en willekeurige bosmodellen:
In de volgende tutorials wordt uitgelegd hoe u beslissingsbomen en willekeurige forests in R kunt passen:
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder