
Pandas : ignorer des colonnes spécifiques lors de l’importation d’un fichier Excel
Vous pouvez utiliser la syntaxe de base suivante pour ignorer des colonnes spécifiques lors de l’importation d’un fichier Excel dans un DataFrame pandas :
#define columns to skip skip_cols = [1, 2] #define columns to keep keep_cols = [i for i in range(4) if i not in skip_cols] #import Excel file and skip specific columns df = pd.read_excel('my_data.xlsx', usecols=keep_cols)
Cet exemple particulier ignorera les colonnes des positions d’index 1 et 2 lors de l’importation du fichier Excel appelé my_data.xlsx dans pandas.
L’exemple suivant montre comment utiliser cette syntaxe dans la pratique.
Exemple : ignorer des colonnes spécifiques lors de l’importation d’un fichier Excel dans Pandas
Supposons que nous ayons le fichier Excel suivant appelé player_data.xlsx :
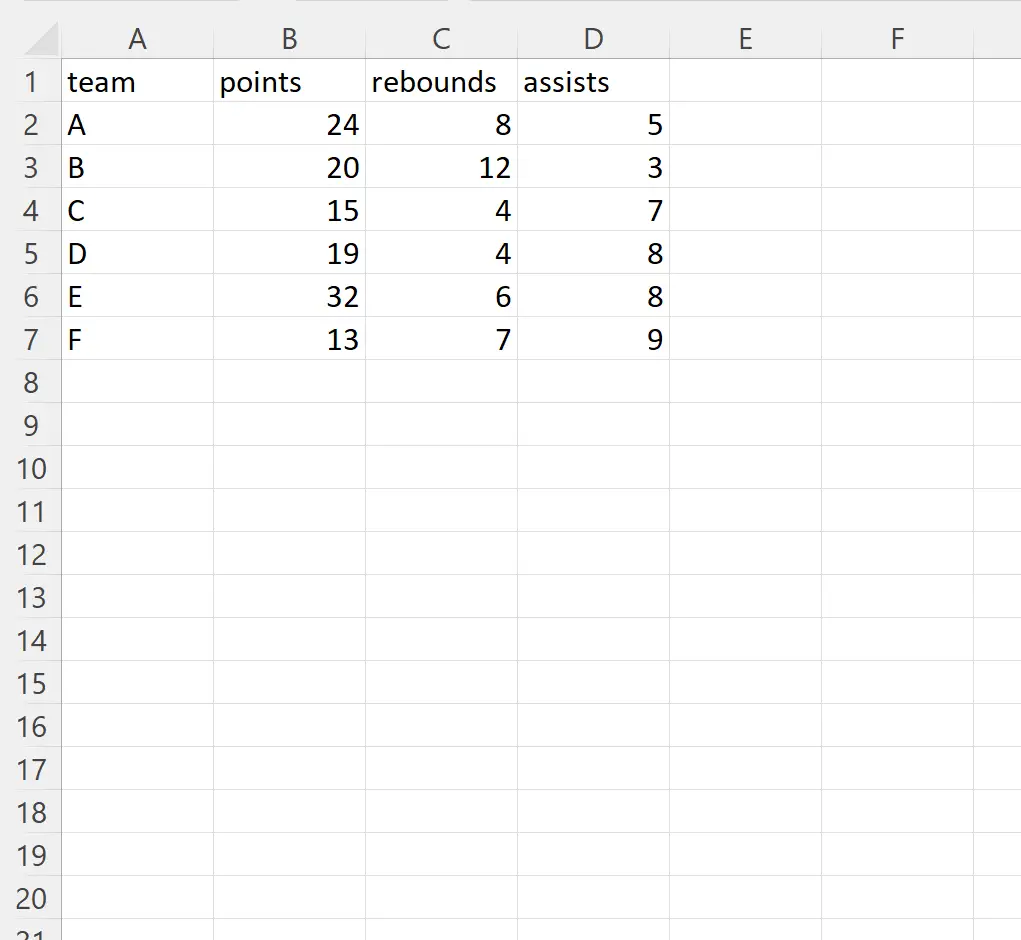
Nous pouvons utiliser la syntaxe suivante pour importer ce fichier dans un DataFrame pandas et ignorer les colonnes des positions d’index 1 et 2 (les colonnes de points et de rebonds) lors de l’importation :
#define columns to skip skip_cols = [1, 2] #define columns to keep keep_cols = [i for i in range(4) if i not in skip_cols] #import Excel file and skip specific columns df = pd.read_excel('player_data.xlsx', usecols=keep_cols) #view DataFrame print(df) team assists 0 A 5 1 B 3 2 C 7 3 D 8 4 E 8 5 F 9
Notez que toutes les colonnes du fichier Excel, à l’exception des colonnes des positions d’index 1 et 2 (les colonnes de points et de rebonds) ont été importées dans le DataFrame pandas.
Notez que cette méthode suppose que vous sachiez au préalable combien de colonnes se trouvent dans le fichier Excel.
Puisque nous savions qu’il y avait 4 colonnes au total dans le fichier, nous avons utilisé range(4) pour définir les colonnes que nous souhaitions conserver.
Remarque : Vous pouvez trouver la documentation complète de la fonction pandas read_excel() ici .
Ressources additionnelles
Les didacticiels suivants expliquent comment effectuer d’autres tâches courantes dans les pandas :
Pandas : Comment sauter des lignes lors de la lecture d’un fichier Excel
Pandas : Comment spécifier les types lors de l’importation d’un fichier Excel
Pandas : Comment combiner plusieurs feuilles Excel
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus