
Pandas : importez du CSV avec un nombre différent de colonnes par ligne
Vous pouvez utiliser la syntaxe de base suivante pour importer un fichier CSV dans pandas lorsqu’il y a un nombre différent de colonnes par ligne :
df = pd.read_csv('uneven_data.csv', header=None, names=range(4))
La valeur à l’intérieur de la fonction range() doit être le nombre de colonnes dans la ligne avec le nombre maximum de colonnes.
L’exemple suivant montre comment utiliser cette syntaxe dans la pratique.
Exemple : importer du CSV dans Pandas avec un nombre différent de colonnes par ligne
Supposons que nous ayons le fichier CSV suivant appelé uneven_data.csv :
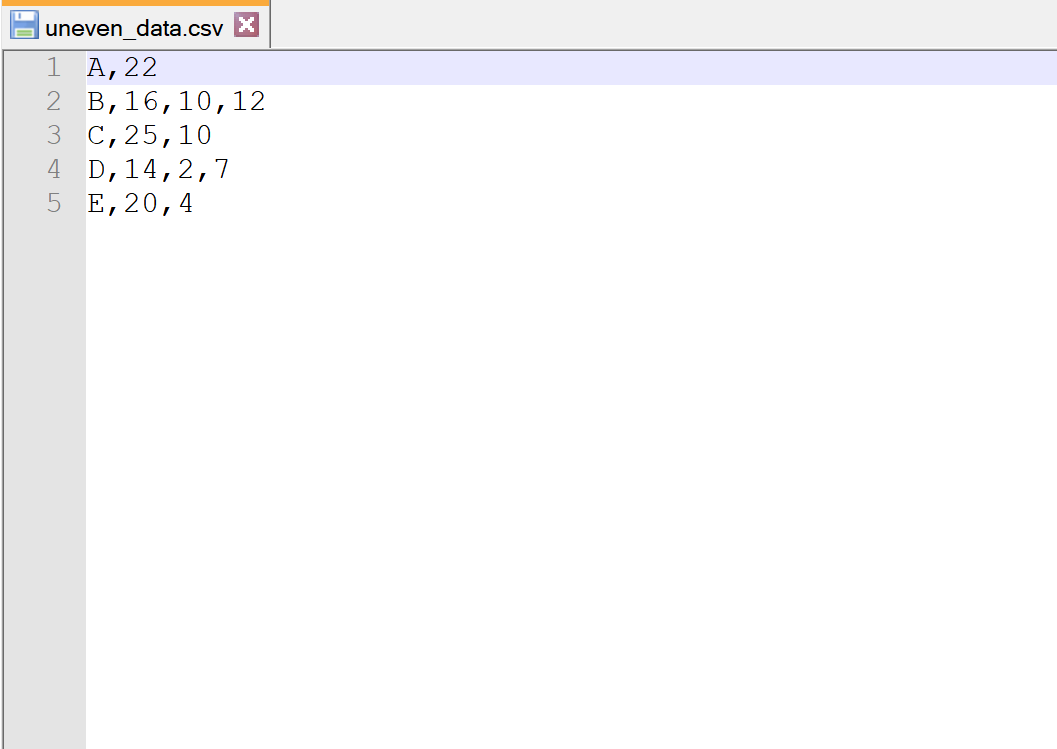
Notez que chaque ligne n’a pas le même nombre de colonnes.
Si nous essayons d’utiliser la fonction read_csv() pour importer ce fichier CSV dans un DataFrame pandas, nous recevrons une erreur :
import pandas as pd #attempt to import CSV file with differing number of columns per row df = pd.read_csv('uneven_data.csv', header=None) ParserError: Error tokenizing data. C error: Expected 2 fields in line 2, saw 4
Nous recevons une ParserError qui nous indique que les pandas attendaient 2 champs (puisqu’il s’agissait du nombre de colonnes dans la première ligne) mais il en a vu 4 .
Cette erreur nous indique que le nombre maximum de colonnes dans une ligne donnée est 4 .
Ainsi, nous pouvons importer le fichier CSV et fournir une valeur de range(4) à l’argument noms :
import pandas as pd #import CSV file with differing number of columns per row df = pd.read_csv('uneven_data.csv', header=None, names=range(4))) #view DataFrame print(df) 0 1 2 3 0 A 22 NaN NaN 1 B 16 10.0 12.0 2 C 25 10.0 NaN 3 D 14 2.0 7.0 4 E 20 4.0 NaN
Notez que nous sommes en mesure d’importer avec succès le fichier CSV dans un DataFrame pandas sans aucune erreur puisque nous avons explicitement dit aux pandas de s’attendre à 4 colonnes.
Par défaut, pandas remplit toutes les valeurs manquantes dans chaque ligne avec NaN.
Si vous souhaitez que les valeurs manquantes apparaissent comme zéro, vous pouvez utiliser la fonction fillna() comme suit :
#fill NaN values with zeros df_new = df.fillna(0) #view new DataFrame print(df_new) 0 1 2 3 0 A 22 0.0 0.0 1 B 16 10.0 12.0 2 C 25 10.0 0.0 3 D 14 2.0 7.0 4 E 20 4.0 0.0
Chaque valeur NaN du DataFrame a désormais été remplacée par un zéro.
Remarque : Vous pouvez trouver la documentation complète de la fonction pandas read_csv() ici .
Ressources additionnelles
Les didacticiels suivants expliquent comment effectuer d’autres tâches courantes en Python :
Pandas : Comment ignorer des lignes lors de la lecture d’un fichier CSV
Pandas : Comment ajouter des données à un fichier CSV existant
Pandas : Comment spécifier les types lors de l’importation d’un fichier CSV
Pandas : définir les noms de colonnes lors de l’importation d’un fichier CSV
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus