
Comment lire CSV sans en-têtes dans Pandas (avec exemple)
Vous pouvez utiliser la syntaxe de base suivante pour lire un fichier CSV sans en-têtes dans un DataFrame pandas :
df = pd.read_csv('my_data.csv', header=None)
L’argument header=None indique aux pandas que la première ligne ne doit pas être utilisée comme ligne d’en-tête.
L’exemple suivant montre comment utiliser cette syntaxe dans la pratique.
Exemple : lire un fichier CSV sans en-têtes dans Pandas
Supposons que nous ayons le fichier CSV suivant appelé Players_data.csv :
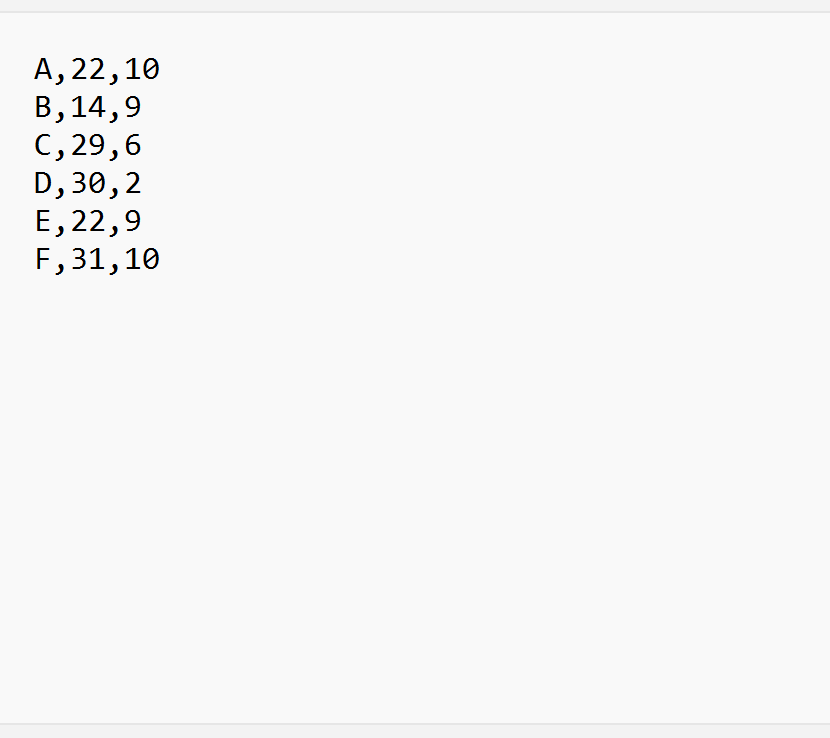
À partir du fichier, nous pouvons voir que la première ligne ne contient aucun nom de colonne.
Si nous importons le fichier CSV à l’aide de la fonction read_csv() , les pandas tenteront d’utiliser la première ligne comme ligne d’en-tête :
import pandas as pd #import CSV file df = pd.read_csv('players_data.csv') #view resulting DataFrame print(df) A 22 10 0 B 14 9 1 C 29 6 2 D 30 2 3 E 22 9 4 F 31 10
Cependant, nous pouvons spécifier header=None pour que les pandas sachent ne pas utiliser la première ligne comme ligne d’en-tête :
import pandas as pd #import CSV file without header df = pd.read_csv('players_data.csv', header=None) #view resulting DataFrame print(df) 0 1 2 0 A 22 10 1 B 14 9 2 C 29 6 3 D 30 2 4 E 22 9 5 F 31 10
Notez que la première ligne du fichier CSV n’est plus utilisée comme ligne d’en-tête.
Notez également que pandas utilise par défaut une plage de valeurs numériques (0, 1, 2) comme noms de colonnes.
Pour spécifier vos propres noms de colonnes lors de l’importation du fichier CSV, vous pouvez utiliser l’argument noms comme suit :
import pandas as pd #specify column names cols = ['team', 'points', 'rebounds'] #import CSV file without header and specify column names df = pd.read_csv('players_data.csv', header=None, names=cols) #view resulting DataFrame print(df) team points rebounds 0 A 22 10 1 B 14 9 2 C 29 6 3 D 30 2 4 E 22 9 5 F 31 10
Le DataFrame a désormais les noms de colonnes que nous avons spécifiés à l’aide de l’argument noms .
Remarque : Vous pouvez trouver la documentation complète de la fonction pandas read_csv() ici .
Ressources additionnelles
Les didacticiels suivants expliquent comment effectuer d’autres tâches courantes en Python :
Pandas : Comment ignorer des lignes lors de la lecture d’un fichier CSV
Pandas : Comment ajouter des données à un fichier CSV existant
Pandas : comment utiliser read_csv avec l’argument usecols
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus