Wprowadzenie do regresji grzbietu
W zwykłej wielokrotnej regresji liniowej używamy zestawu p zmiennych predykcyjnych i zmiennej odpowiedzi , aby dopasować model w postaci:
Y = β 0 + β 1 X 1 + β 2 X 2 + … + β p
Złoto:
- Y : Zmienna odpowiedzi
- X j : j- ta zmienna predykcyjna
- β j : Średni wpływ na Y jednojednostkowego wzrostu X j , przy założeniu, że wszystkie inne predyktory są stałe
- ε : Termin błędu
Wartości β 0 , β 1 , B 2 , …, β p dobieramy metodą najmniejszych kwadratów , która minimalizuje sumę kwadratów reszt (RSS):
RSS = Σ(y i – ŷ i ) 2
Złoto:
- Σ : Grecki symbol oznaczający sumę
- y i : rzeczywista wartość odpowiedzi dla i-tej obserwacji
- ŷ i : Przewidywana wartość odpowiedzi na podstawie modelu wielokrotnej regresji liniowej
Jednakże, gdy zmienne predykcyjne są silnie skorelowane, współliniowość może stać się problemem. Może to sprawić, że szacunki współczynników modelu będą niewiarygodne i będą wykazywać dużą wariancję.
Jednym ze sposobów obejścia tego problemu bez całkowitego usuwania niektórych zmiennych predykcyjnych z modelu jest zastosowanie metody znanej jako regresja grzbietowa , która zamiast tego ma na celu zminimalizowanie następujących czynników:
RSS + λΣβ j 2
gdzie j przechodzi od 1 do p i λ ≥ 0.
Ten drugi człon równania nazywany jest karą za wycofanie .
Gdy λ = 0, ten składnik kary nie ma żadnego efektu, a regresja grzbietowa daje takie same szacunki współczynników, jak metoda najmniejszych kwadratów. Jednakże, gdy λ zbliża się do nieskończoności, kara za skurcz staje się bardziej wpływowa, a szacunki szczytowego współczynnika regresji zbliżają się do zera.
Ogólnie rzecz biorąc, najmniej wpływowe zmienne predykcyjne w modelu będą najszybciej spadać do zera.
Dlaczego warto stosować regresję grzbietu?
Przewagą regresji Ridge’a nad regresją metodą najmniejszych kwadratów jest kompromis w postaci odchylenia wariancji .
Przypomnijmy, że błąd średniokwadratowy (MSE) to metryka, za pomocą której możemy zmierzyć dokładność danego modelu i oblicza się go w następujący sposób:
MSE = Var( f̂( x 0 )) + [Odchylenie( f̂( x 0 ))] 2 + Var(ε)
MSE = wariancja + błąd 2 + błąd nieredukowalny
Podstawową ideą regresji Ridge’a jest wprowadzenie małego błędu systematycznego, dzięki czemu wariancja może zostać znacznie zmniejszona, co prowadzi do niższego ogólnego MSE.
Aby to zilustrować, rozważ następujący wykres:

Należy zauważyć, że wraz ze wzrostem λ wariancja znacznie maleje przy bardzo małym wzroście obciążenia. Jednak powyżej pewnego punktu wariancja maleje wolniej, a spadek współczynników prowadzi do ich znacznego niedoszacowania, co prowadzi do gwałtownego wzrostu obciążenia systematycznego.
Z wykresu widzimy, że MSE testu jest najniższe, gdy wybierzemy wartość λ, która zapewnia optymalny kompromis między obciążeniem a wariancją.
Gdy λ = 0, składnik karny w regresji grzbietowej nie ma żadnego wpływu i dlatego daje takie same oszacowania współczynników, jak metoda najmniejszych kwadratów. Jednakże, zwiększając λ do pewnego punktu, możemy zmniejszyć całkowite MSE testu.
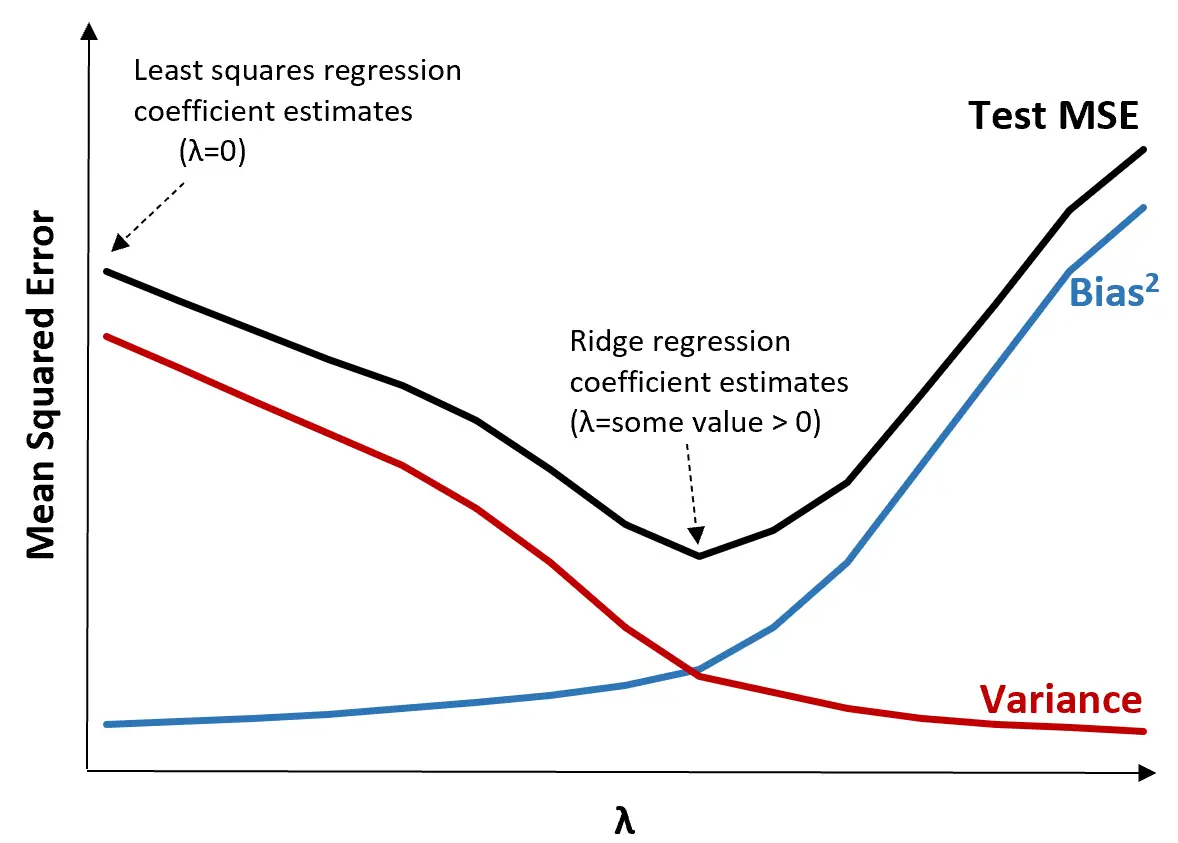
Oznacza to, że dopasowanie modelu metodą regresji grzbietowej spowoduje mniejsze błędy testowe niż dopasowanie modelu metodą najmniejszych kwadratów.
Kroki wykonywania regresji grzbietu w praktyce
Do przeprowadzenia regresji grzbietu można zastosować następujące kroki:
Krok 1: Oblicz macierz korelacji i wartości VIF dla zmiennych predykcyjnych.
Najpierw musimy stworzyć macierz korelacji i obliczyć wartości VIF (współczynnik inflacji wariancji) dla każdej zmiennej predykcyjnej.
Jeśli wykryjemy silną korelację między zmiennymi predykcyjnymi a wysokimi wartościami VIF (niektóre teksty definiują „wysoką” wartość VIF na 5, podczas gdy inne używają 10), wówczas prawdopodobnie właściwa będzie regresja grzbietu.
Jeśli jednak w danych nie występuje współliniowość, wykonanie regresji grzbietowej może nie być konieczne. Zamiast tego możemy wykonać zwykłą regresję metodą najmniejszych kwadratów.
Krok 2: Standaryzuj każdą zmienną predykcyjną.
Przed wykonaniem regresji grzbietowej musimy przeskalować dane w taki sposób, aby każda zmienna predykcyjna miała średnią 0 i odchylenie standardowe 1. Dzięki temu żadna pojedyncza zmienna predykcyjna nie będzie miała nadmiernego wpływu podczas przeprowadzania regresji grzbietowej.
Krok 3: Dopasuj model regresji grzbietu i wybierz wartość λ.
Nie ma dokładnego wzoru, którego moglibyśmy użyć, aby określić, jaką wartość zastosować dla λ. W praktyce istnieją dwa popularne sposoby wyboru λ:
(1) Utwórz wykres śladu grzbietu. Jest to wykres wizualizujący wartości szacunków współczynnika w miarę wzrostu λ w kierunku nieskończoności. Zazwyczaj wybieramy λ jako wartość, przy której większość szacunków współczynników zaczyna się stabilizować.
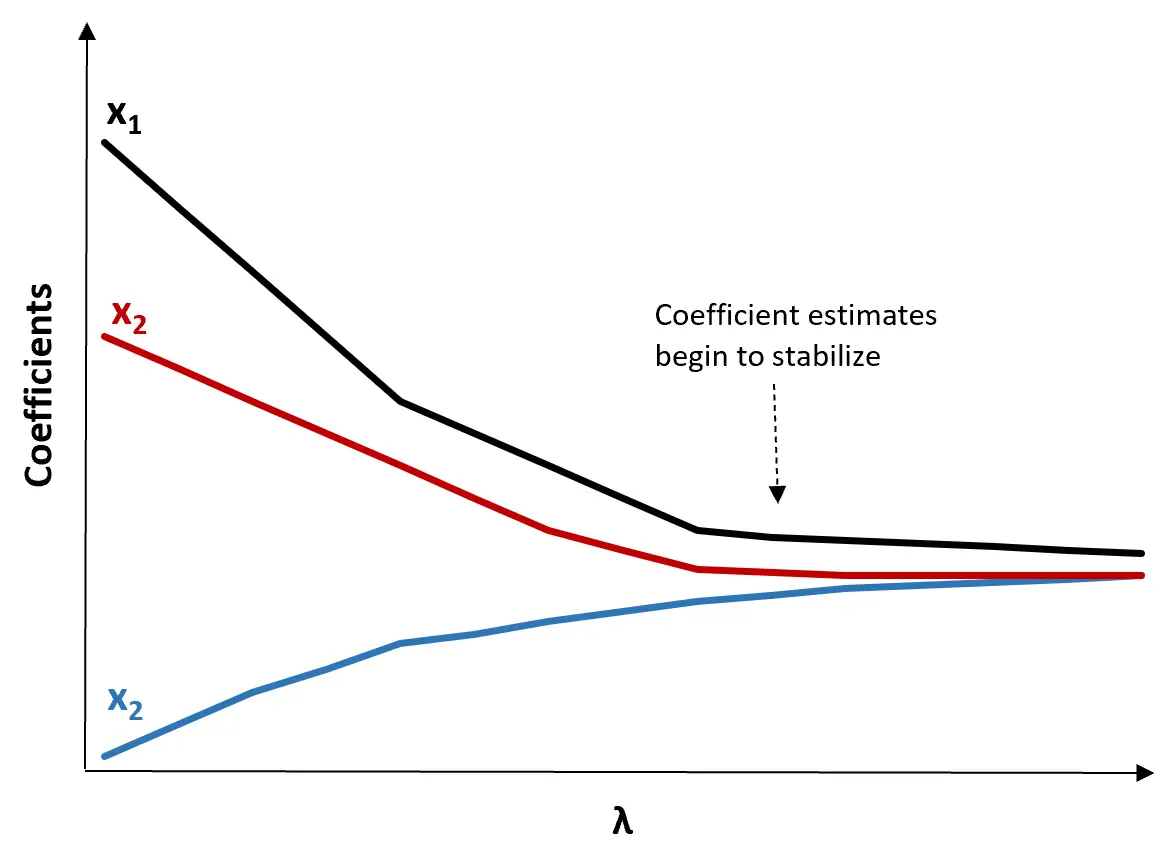
(2) Oblicz test MSE dla każdej wartości λ.
Innym sposobem wyboru λ jest po prostu obliczenie testowego MSE każdego modelu z różnymi wartościami λ i wybranie λ jako wartości, która daje najniższy testowy MSE.
Zalety i wady regresji grzbietu
Największą zaletą regresji Ridge’a jest jej zdolność do generowania mniejszego testu średniokwadratowego błędu (MSE) niż metoda najmniejszych kwadratów, gdy występuje współliniowość.
Jednak największą wadą regresji Ridge’a jest niemożność przeprowadzenia selekcji zmiennych, ponieważ uwzględnia ona wszystkie zmienne predykcyjne w ostatecznym modelu. Ponieważ niektóre predyktory zostaną zredukowane bardzo blisko zera, może to utrudnić interpretację wyników modelu.
W praktyce regresja Ridge’a może stworzyć model umożliwiający lepsze prognozy w porównaniu z modelem najmniejszych kwadratów, ale często trudniej jest zinterpretować wyniki modelu.
W zależności od tego, czy ważniejsza jest dla Ciebie interpretacja modelu czy dokładność prognozy, możesz w różnych scenariuszach zastosować zwykłą metodę najmniejszych kwadratów lub regresję grzbietową.
Regresja grzbietowa w R i Pythonie
Poniższe samouczki wyjaśniają, jak przeprowadzić regresję grzbietową w R i Pythonie, dwóch najczęściej używanych językach do dopasowywania modeli regresji grzbietowej:
Regresja grzbietu w R (krok po kroku)
Regresja grzbietu w Pythonie (krok po kroku)
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej