Wprowadzenie do drzew klasyfikacji i regresji
Gdy związek między zestawem zmiennych predykcyjnych a zmienną odpowiedzi jest liniowy, metody takie jak wielokrotna regresja liniowa mogą stworzyć dokładne modele predykcyjne.
Jeśli jednak związek między zestawem predyktorów a odpowiedzią jest wysoce nieliniowy i złożony, wówczas metody nieliniowe mogą działać lepiej.
Przykładem metody nieliniowej są drzewa klasyfikacji i regresji , często nazywane w skrócie CART .
Jak sama nazwa wskazuje, modele CART wykorzystują zestaw zmiennych predykcyjnych do tworzenia drzew decyzyjnych , które przewidują wartość zmiennej odpowiedzi.
Załóżmy na przykład, że mamy zestaw danych zawierający zmienne predykcyjne „ Lata gry ” i „Średnia liczba zdobytych bramek” oraz zmienną odpowiedzi „ Roczne wynagrodzenie” dla setek zawodowych graczy w baseball.
Oto jak może wyglądać drzewo regresji dla tego zbioru danych:
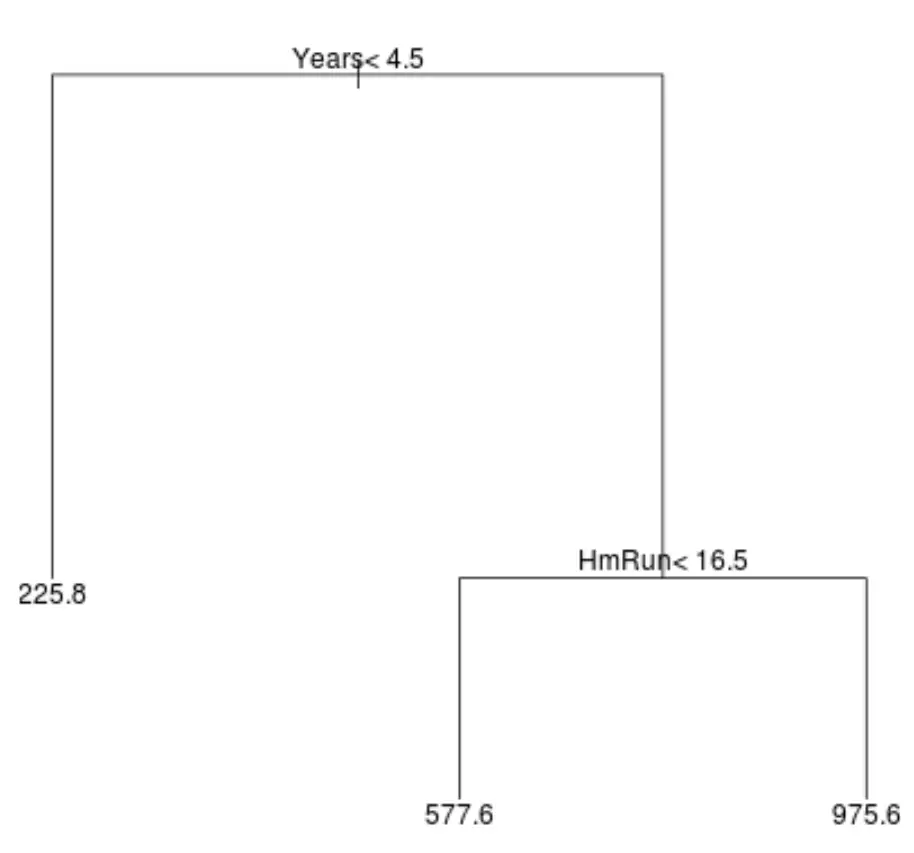
Sposób interpretacji drzewa jest następujący:
- Gracze, którzy grają krócej niż 4,5 roku, mają prognozowaną pensję na poziomie 225,8 tys. dolarów.
- Gracze, którzy grali dłużej niż 4,5 roku lub dłużej i średnio mniej niż 16,5 home runów, mają przewidywaną pensję w wysokości 577,6 tys. dolarów.
- Gracze z co najmniej 4,5-letnim doświadczeniem w grze i średnio 16,5 home runami lub więcej mają oczekiwaną pensję w wysokości 975,6 tys. dolarów.
Wyniki tego modelu powinny intuicyjnie mieć sens: gracze z dłuższym doświadczeniem i większą liczbą średnich home runów zazwyczaj zarabiają wyższe pensje.
Możemy następnie użyć tego modelu do przewidzenia wynagrodzenia nowego gracza.
Załóżmy na przykład, że dany zawodnik gra przez 8 lat i średnio 10 home runów rocznie. Według naszego modelu przewidywalibyśmy, że ten zawodnik będzie zarabiał rocznie 577,6 tys. dolarów.
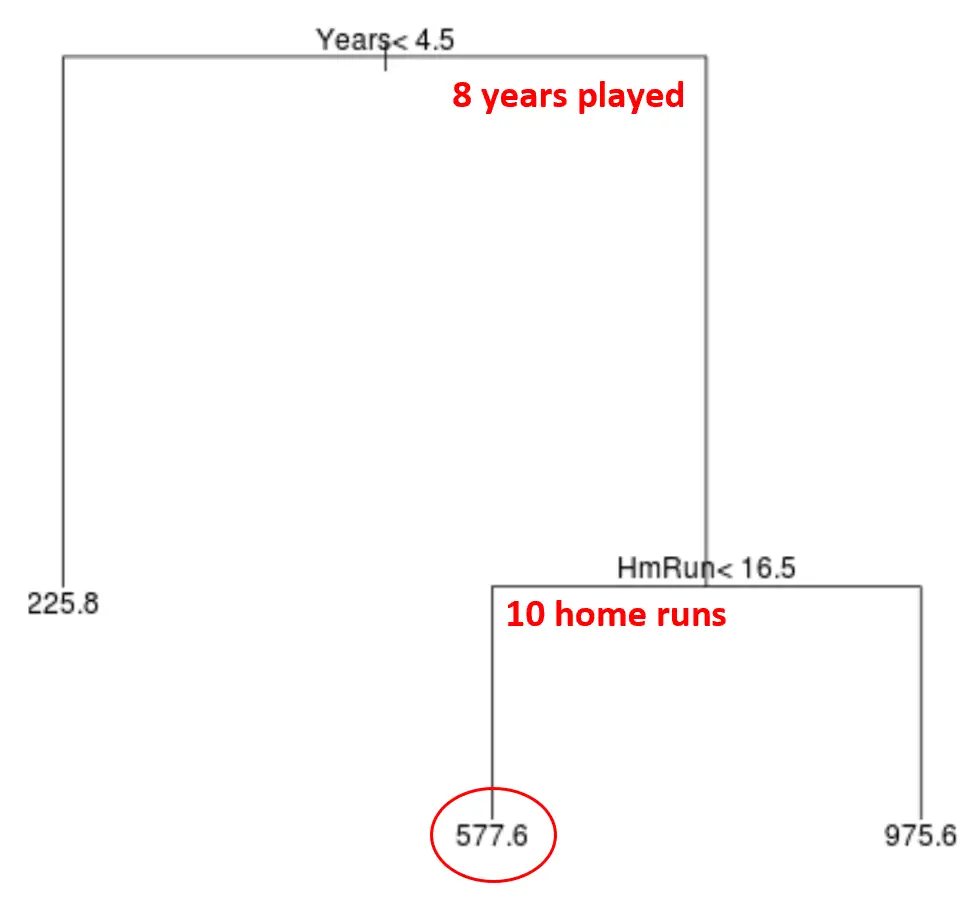
Kilka uwag na temat drzewa:
- Najważniejsza jest pierwsza zmienna predykcyjna znajdująca się na szczycie drzewa, czyli ta, która ma największy wpływ na przewidywanie wartości zmiennej odpowiedzi. W tym przypadku lata przepracowane pozwalają przewidzieć pensję lepiej niż średnia z obwodów .
- Regiony na dole drzewa nazywane są węzłami liści . To konkretne drzewo ma trzy węzły końcowe.
Kroki tworzenia modeli CART
Aby utworzyć model CART dla danego zbioru danych, możemy wykonać następujące kroki:
Krok 1: Użyj rekurencyjnego podziału binarnego, aby wyhodować duże drzewo na danych szkoleniowych.
Najpierw używamy zachłannego algorytmu zwanego rekurencyjnym dzieleniem binarnym, aby wyhodować drzewo regresji przy użyciu następującej metody:
- Rozważ wszystkie zmienne predykcyjne X 1 , X 2 , … , resztkowy błąd standardowy) jako najniższe. .
- W przypadku drzew klasyfikacyjnych wybieramy predyktor i punkt odcięcia w taki sposób, aby powstałe drzewo miało najniższy poziom błędu klasyfikacji.
- Powtórz ten proces, zatrzymując się tylko wtedy, gdy każdy węzeł końcowy ma mniej niż określoną minimalną liczbę obserwacji.
Algorytm ten jest zachłanny , ponieważ na każdym etapie procesu budowania drzewa określa najlepszy podział, którego można dokonać tylko na podstawie tego kroku, zamiast patrzeć w przyszłość i wybierać podział, który doprowadzi do lepszego globalnego drzewa w przyszłym etapie.
Krok 2: Zastosuj przycinanie złożoności kosztowej do dużego drzewa, aby uzyskać sekwencję najlepszych drzew w oparciu o α.
Kiedy już wyhodujemy duże drzewo, musimy je przyciąć za pomocą metody zwanej przycinaniem złożonym, która działa w następujący sposób:
- Dla każdego możliwego drzewa z T węzłami końcowymi znajdź drzewo, które minimalizuje RSS + α|T|.
- Należy pamiętać, że gdy zwiększamy wartość α, drzewa z większą liczbą węzłów końcowych są karane. Dzięki temu drzewo nie stanie się zbyt skomplikowane.
W wyniku tego procesu powstaje sekwencja najlepszych drzew dla każdej wartości α.
Krok 3: Użyj k-krotnej walidacji krzyżowej, aby wybrać α.
Gdy znajdziemy najlepsze drzewo dla każdej wartości α, możemy zastosować k-krotną walidację krzyżową , aby wybrać wartość α, która minimalizuje błąd testowania.
Krok 4: Wybierz ostateczny szablon.
Ostatecznie wybieramy ostateczny model jako taki, który odpowiada wybranej wartości α.
Zalety i wady modeli CART
Modele CART oferują następujące zalety :
- Są łatwe do interpretacji.
- Łatwo je wytłumaczyć.
- Łatwo je sobie wyobrazić.
- Można je zastosować zarówno do problemów regresji, jak i klasyfikacji .
Modele CART mają jednak następujące wady:
- Zwykle nie mają tak dużej dokładności predykcyjnej, jak inne nieliniowe algorytmy uczenia maszynowego. Jednakże, łącząc wiele drzew decyzyjnych za pomocą metod takich jak pakowanie, wzmacnianie i lasy losowe, można poprawić ich dokładność predykcyjną.
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej