Regresja lub klasyfikacja: jaka jest różnica?
Algorytmy uczenia maszynowego można podzielić na dwa różne typy: algorytmy uczenia się nadzorowanego i nienadzorowanego .

Algorytmy uczenia się nadzorowanego można podzielić na dwa typy:
1. Regresja: zmienna odpowiedzi ma charakter ciągły.
Na przykład zmienną odpowiedzi może być:
- Waga
- Wysokość
- Cena
- Czas
- Całkowita liczba jednostek
W każdym przypadku model regresji stara się przewidzieć wielkość ciągłą.
Przykład regresji:
Załóżmy, że mamy zbiór danych zawierający trzy zmienne dla 100 różnych domów: powierzchnię użytkową, liczbę łazienek i cenę sprzedaży.
Moglibyśmy dopasować model regresji, który wykorzystuje powierzchnię i liczbę łazienek jako zmienne objaśniające, a cenę sprzedaży jako zmienną odpowiedzi.
Moglibyśmy następnie użyć tego modelu do przewidzenia ceny sprzedaży domu na podstawie jego powierzchni i liczby łazienek.
Jest to przykład modelu regresji, ponieważ zmienna odpowiedzi (cena sprzedaży) ma charakter ciągły.
Najczęstszym sposobem pomiaru dokładności modelu regresji jest obliczenie pierwiastka błędu średniokwadratowego (RMSE), metryki, która mówi nam, jak średnio nasze przewidywane wartości różnią się od wartości obserwowanych w modelu. Oblicza się go w następujący sposób:
RMSE = √ Σ(P ja – O ja ) 2 / n
Złoto:
- Σ to fantazyjny symbol oznaczający „sumę”
- Pi jest przewidywaną wartością i-tej obserwacji
- O i jest obserwowaną wartością i-tej obserwacji
- n to wielkość próbki
Im mniejszy RMSE, tym lepiej model regresji jest w stanie dopasować dane.
2. Klasyfikacja: Zmienna odpowiedzi ma charakter kategoryczny.
Na przykład zmienna odpowiedzi może przyjmować następujące wartości:
- Mężczyzna czy kobieta
- Sukces lub porażka
- Niski, średni lub wysoki
W każdym przypadku model klasyfikacji stara się przewidzieć etykietę klasy.
Przykład klasyfikacji:
Załóżmy, że mamy zbiór danych zawierający trzy zmienne dla 100 różnych koszykarzy z college’u: średnia punktów na mecz, poziom ligi oraz to, czy zostali powołani do NBA.
Moglibyśmy zaadaptować model klasyfikacji, który wykorzystuje średnią punktów na mecz i poziom ligi jako zmienne objaśniające i „szkicowaną” jako zmienną odpowiedzi.
Moglibyśmy następnie użyć tego modelu do przewidzenia, czy dany zawodnik zostanie powołany do NBA, na podstawie jego średniej liczby punktów na mecz i poziomu ligi.
Jest to przykład modelu klasyfikacji, ponieważ zmienna odpowiedzi („zapisana”) ma charakter kategoryczny. Innymi słowy, może przyjmować tylko wartości z dwóch różnych kategorii: „Napisane” lub „Niedopracowane”.
Najczęstszym sposobem pomiaru dokładności modelu klasyfikacji jest po prostu obliczenie procentu poprawnych klasyfikacji dokonanych przez model:
Dokładność = klasyfikacje korekcyjne / łączna liczba prób klasyfikacji * 100%
Na przykład, jeśli model prawidłowo określa, czy zawodnik zostanie wybrany do NBA w 88 na 100 możliwych przypadkach, wówczas dokładność modelu wynosi:
Dokładność = (88/100) * 100% = 88%
Im wyższa dokładność, tym lepiej model klasyfikacyjny jest w stanie przewidzieć wyniki.
Podobieństwa między regresją a klasyfikacją
Algorytmy regresji i klasyfikacji są podobne pod następującymi względami:
- Obydwa są algorytmami uczenia się nadzorowanego, co oznacza, że oba wymagają zmiennej odpowiedzi.
- Obydwa wykorzystują jedną lub więcej zmiennych objaśniających do tworzenia modeli przewidywania reakcji.
- Obydwa można wykorzystać do zrozumienia, w jaki sposób zmiany wartości zmiennych objaśniających wpływają na wartości zmiennej odpowiedzi.
Różnice pomiędzy regresją a klasyfikacją
Algorytmy regresji i klasyfikacji różnią się w następujący sposób:
- Algorytmy regresji starają się przewidzieć wielkość ciągłą, a algorytmy klasyfikacji starają się przewidzieć etykietę klasy.
- Różni się sposób pomiaru dokładności modeli regresji i klasyfikacji.
Przekształcenie regresji w klasyfikację
Należy zauważyć, że problem regresji można przekształcić w problem klasyfikacji, po prostu dyskretyzując zmienną odpowiedzi na przedziały.
Załóżmy na przykład, że mamy zbiór danych zawierający trzy zmienne: powierzchnię użytkową, liczbę łazienek i cenę sprzedaży.
Moglibyśmy zbudować model regresji, wykorzystując powierzchnię i liczbę łazienek, aby przewidzieć ceny sprzedaży.
Moglibyśmy jednak rozróżnić cenę sprzedaży na trzy różne klasy:
- 80 000–160 000 USD: „Niska cena sprzedaży”
- 161 000–240 000 USD: „Średnia cena sprzedaży”
- 241 000–320 000 USD: „Wysoka cena sprzedaży”
Moglibyśmy następnie użyć metrażu kwadratowego i liczby łazienek jako zmiennych objaśniających, aby przewidzieć, do której klasy (niskiej, średniej lub wysokiej) będzie należeć cena sprzedaży danego domu.
Byłby to przykład modelu klasyfikacji, ponieważ staramy się umieścić każdy dom w klasie.
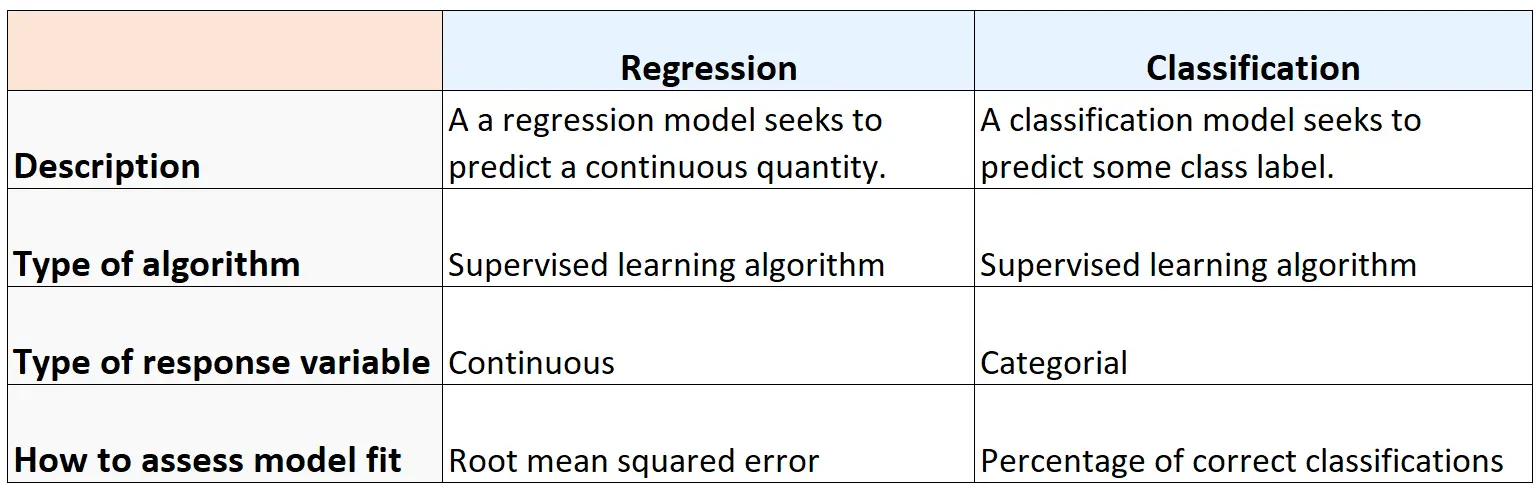
Streszczenie
Poniższa tabela podsumowuje podobieństwa i różnice między algorytmami regresji i klasyfikacji:
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej