Co jest uważane za „dobre”? wynik w f1?
Podczas korzystania z modeli klasyfikacyjnych w uczeniu maszynowym powszechnym miernikiem, którego używamy do oceny jakości modelu, jest wynik F1 .
Wskaźnik ten jest obliczany w następujący sposób:
Wynik F1 = 2 * (Precyzja * Przywołanie) / (Precyzja + Przypomnienie)
Złoto:
- Dokładność : Popraw pozytywne przewidywania w stosunku do wszystkich pozytywnych przewidywań
- Przypomnienie : Korygowanie pozytywnych przewidywań w stosunku do łącznej liczby rzeczywistych pozytywnych wyników
Załóżmy na przykład, że używamy modelu regresji logistycznej do przewidzenia, czy 400 różnych koszykarzy z college’u zostanie powołanych do NBA.
Poniższa macierz zamieszania podsumowuje przewidywania dokonane przez model:

Oto jak obliczyć wynik modelu w F1:
Dokładność = prawdziwie dodatnia / (prawdziwie dodatnia + fałszywie dodatnia) = 120/ (120+70) = 0,63157
Przywołanie = prawdziwie dodatnie / (prawdziwie dodatnie + fałszywie ujemne) = 120 / (120+40) = 0,75
Wynik F1 = 2 * (0,63157 * 0,75) / (0,63157 + 0,75) = . 6857
Jaki jest dobry wynik w F1?
Pytanie, które często zadają uczniowie, brzmi:
Jaki jest dobry wynik w F1?
Krótko mówiąc, wyższe wyniki w F1 są na ogół lepsze.
Przypomnijmy, że wyniki F1 mogą przyjmować wartości od 0 do 1, gdzie 1 oznacza model, który doskonale klasyfikuje każdą obserwację do właściwej klasy, a 0 oznacza model, który nie jest w stanie zaklasyfikować obserwacji do właściwej klasy.
Aby to zilustrować, załóżmy, że mamy model regresji logistycznej, który tworzy następującą macierz zamieszania:
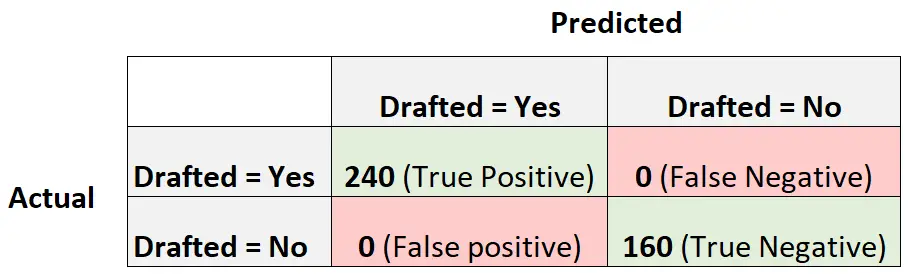
Oto jak obliczyć wynik modelu w F1:
Dokładność = prawdziwie dodatnia / (prawdziwie dodatnia + fałszywie dodatnia) = 240/ (240+0) = 1
Przywołanie = prawdziwie dodatnie / (prawdziwie dodatnie + fałszywie ujemne) = 240 / (240+0) = 1
Wynik F1 = 2 * (1 * 1) / (1 + 1) = 1
Wynik F1 jest równy jeden, ponieważ jest w stanie doskonale sklasyfikować każdą z 400 obserwacji w klasę.
Rozważmy teraz inny model regresji logistycznej, który po prostu przewiduje, że każdy gracz zostanie wybrany:
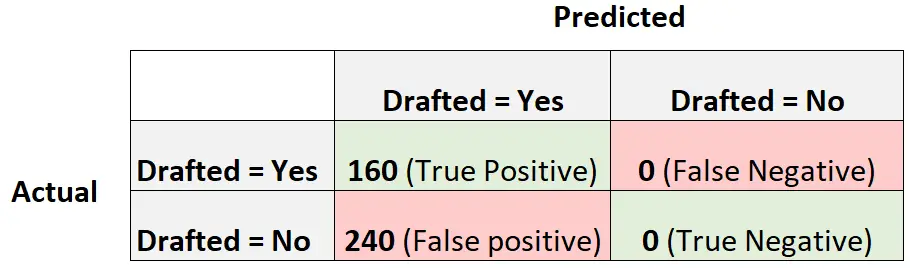
Oto jak obliczyć wynik modelu w F1:
Dokładność = prawdziwie dodatnia / (prawdziwie dodatnia + fałszywie dodatnia) = 160/ (160+240) = 0,4
Przywołanie = prawdziwie dodatnie / (prawdziwie dodatnie + fałszywie ujemne) = 160 / (160+0) = 1
Wynik F1 = 2 * (0,4 * 1) / (0,4 + 1) = 0,5714
Można by to uznać za model bazowy , z którym moglibyśmy porównać nasz model regresji logistycznej, ponieważ reprezentuje on model, który przewiduje takie same przewidywania dla każdej obserwacji w zbiorze danych.
Im wyższy wynik w F1 w porównaniu z modelem referencyjnym, tym bardziej użyteczny jest nasz model.
Przypomnijmy, że nasz model miał notę F1 na poziomie 0,6857 . Wartość ta nie jest dużo wyższa niż 0,5714 , co wskazuje, że nasz model jest bardziej użyteczny niż model bazowy, ale niewiele.
Porównując wyniki F1
W praktyce zazwyczaj stosujemy następujący proces, aby wybrać „najlepszy” model problemu klasyfikacyjnego:
Krok 1: Dopasuj model referencyjny, który daje takie same przewidywania dla każdej obserwacji.
Krok 2: Dopasuj kilka różnych modeli klasyfikacji i oblicz wynik F1 dla każdego modelu.
Krok 3: Wybierz model z najwyższym wynikiem F1 jako „najlepszy” model, sprawdzając, czy daje on wyższy wynik F1 niż model referencyjny.
Żadna konkretna wartość nie jest uważana za „dobry” wynik w F1, dlatego zazwyczaj wybieramy model klasyfikacji, który daje najwyższy wynik w F1.
Dodatkowe zasoby
Wynik F1 a dokładność: którego powinieneś użyć?
Jak obliczyć wynik F1 w R
Jak obliczyć wynik F1 w Pythonie
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej