Liniowa analiza dyskryminacyjna w pythonie (krok po kroku)
Liniowa analiza dyskryminacyjna to metoda, której można użyć, gdy masz zestaw zmiennych predykcyjnych i chcesz sklasyfikować zmienną odpowiedzi na dwie lub więcej klas.
W tym samouczku przedstawiono krok po kroku przykład przeprowadzania liniowej analizy dyskryminacyjnej w języku Python.
Krok 1: Załaduj niezbędne biblioteki
Najpierw załadujemy funkcje i biblioteki potrzebne w tym przykładzie:
from sklearn. model_selection import train_test_split
from sklearn. model_selection import RepeatedStratifiedKFold
from sklearn. model_selection import cross_val_score
from sklearn. discriminant_analysis import LinearDiscriminantAnalysis
from sklearn import datasets
import matplotlib. pyplot as plt
import pandas as pd
import numpy as np
Krok 2: Załaduj dane
W tym przykładzie użyjemy zestawu danych iris z biblioteki sklearn. Poniższy kod pokazuje, jak załadować ten zestaw danych i przekonwertować go na ramkę DataFrame pandy, aby ułatwić użytkowanie:
#load iris dataset iris = datasets. load_iris () #convert dataset to pandas DataFrame df = pd.DataFrame(data = np.c_[iris[' data '], iris[' target ']], columns = iris[' feature_names '] + [' target ']) df[' species '] = pd. Categorical . from_codes (iris.target, iris.target_names) df.columns = [' s_length ', ' s_width ', ' p_length ', ' p_width ', ' target ', ' species '] #view first six rows of DataFrame df. head () s_length s_width p_length p_width target species 0 5.1 3.5 1.4 0.2 0.0 setosa 1 4.9 3.0 1.4 0.2 0.0 setosa 2 4.7 3.2 1.3 0.2 0.0 setosa 3 4.6 3.1 1.5 0.2 0.0 setosa 4 5.0 3.6 1.4 0.2 0.0 setosa #find how many total observations are in dataset len( df.index ) 150
Widzimy, że zbiór danych zawiera w sumie 150 obserwacji.
Na potrzeby tego przykładu zbudujemy liniowy model analizy dyskryminacyjnej, aby sklasyfikować, do jakiego gatunku należy dany kwiat.
W modelu wykorzystamy następujące zmienne predykcyjne:
- Długość działki
- Szerokość działki
- Długość płatka
- Szerokość płatka
Wykorzystamy je do przewidzenia zmiennej odpowiedzi Gatunek , która obsługuje następujące trzy potencjalne klasy:
- setosa
- wielokolorowy
- Wirginia
Krok 3: Dostosuj model LDA
Następnie dopasujemy model LDA do naszych danych za pomocą funkcji LinearDiscriminantAnalsys sklearna:
#define predictor and response variables X = df[[' s_length ',' s_width ',' p_length ',' p_width ']] y = df[' species '] #Fit the LDA model model = LinearDiscriminantAnalysis() model. fit (x,y)
Krok 4: Użyj modelu do przewidywania
Po dopasowaniu modelu przy użyciu naszych danych możemy ocenić jego skuteczność, stosując wielokrotną warstwową k-krotną walidację krzyżową.
W tym przykładzie użyjemy 10 fałd i 3 powtórzeń:
#Define method to evaluate model
cv = RepeatedStratifiedKFold(n_splits= 10 , n_repeats= 3 , random_state= 1 )
#evaluate model
scores = cross_val_score(model, X, y, scoring=' accuracy ', cv=cv, n_jobs=-1)
print( np.mean (scores))
0.9777777777777779
Widzimy, że model osiągnął średnią dokładność na poziomie 97,78% .
Możemy również użyć modelu, aby przewidzieć, do której klasy należy nowy kwiat, na podstawie wartości wejściowych:
#define new observation new = [5, 3, 1, .4] #predict which class the new observation belongs to model. predict ([new]) array(['setosa'], dtype='<U10')
Widzimy, że model przewiduje, że ta nowa obserwacja należy do gatunku zwanego setosa .
Krok 5: Wizualizuj wyniki
Na koniec możemy utworzyć wykres LDA, aby zwizualizować liniowe wyróżniki modelu i zwizualizować, jak dobrze oddziela on trzy różne gatunki w naszym zbiorze danych:
#define data to plot X = iris.data y = iris.target model = LinearDiscriminantAnalysis() data_plot = model. fit (x,y). transform (X) target_names = iris. target_names #create LDA plot plt. figure () colors = [' red ', ' green ', ' blue '] lw = 2 for color, i, target_name in zip(colors, [0, 1, 2], target_names): plt. scatter (data_plot[y == i, 0], data_plot[y == i, 1], alpha=.8, color=color, label=target_name) #add legend to plot plt. legend (loc=' best ', shadow= False , scatterpoints=1) #display LDA plot plt. show ()
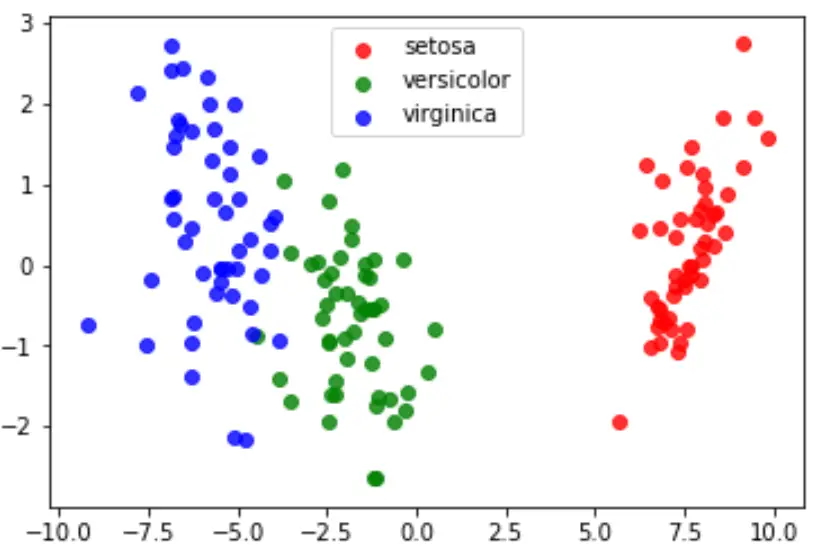
Pełny kod Pythona użyty w tym samouczku znajdziesz tutaj .
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej