Jak korzystać z funkcji logest w arkuszach google (z przykładem)
Możesz użyć funkcji LOGEST w Arkuszach Google, aby obliczyć wzór na krzywą wykładniczą pasującą do Twoich danych.
Równanie krzywej będzie miało następującą postać:
y = b* mx
Ta funkcja wykorzystuje następującą podstawową składnię:
= LOGEST ( known_data_y, [known_data_x], [b], [verbose] )
Złoto:
- znane_dane_y : Tablica znanych wartości y
- znane_dane_x : Tablica znanych wartości x
- b : Argument opcjonalny. Jeśli TRUE, stała b jest przetwarzana normalnie. Jeśli FALSE, stała b jest ustawiona na 1.
- gadatliwy : argument opcjonalny. Jeśli TRUE, zwracane są dodatkowe statystyki regresji. Jeśli FALSE, dodatkowe statystyki regresji nie są zwracane.
Poniższy przykład krok po kroku pokazuje, jak w praktyce wykorzystać tę funkcję.
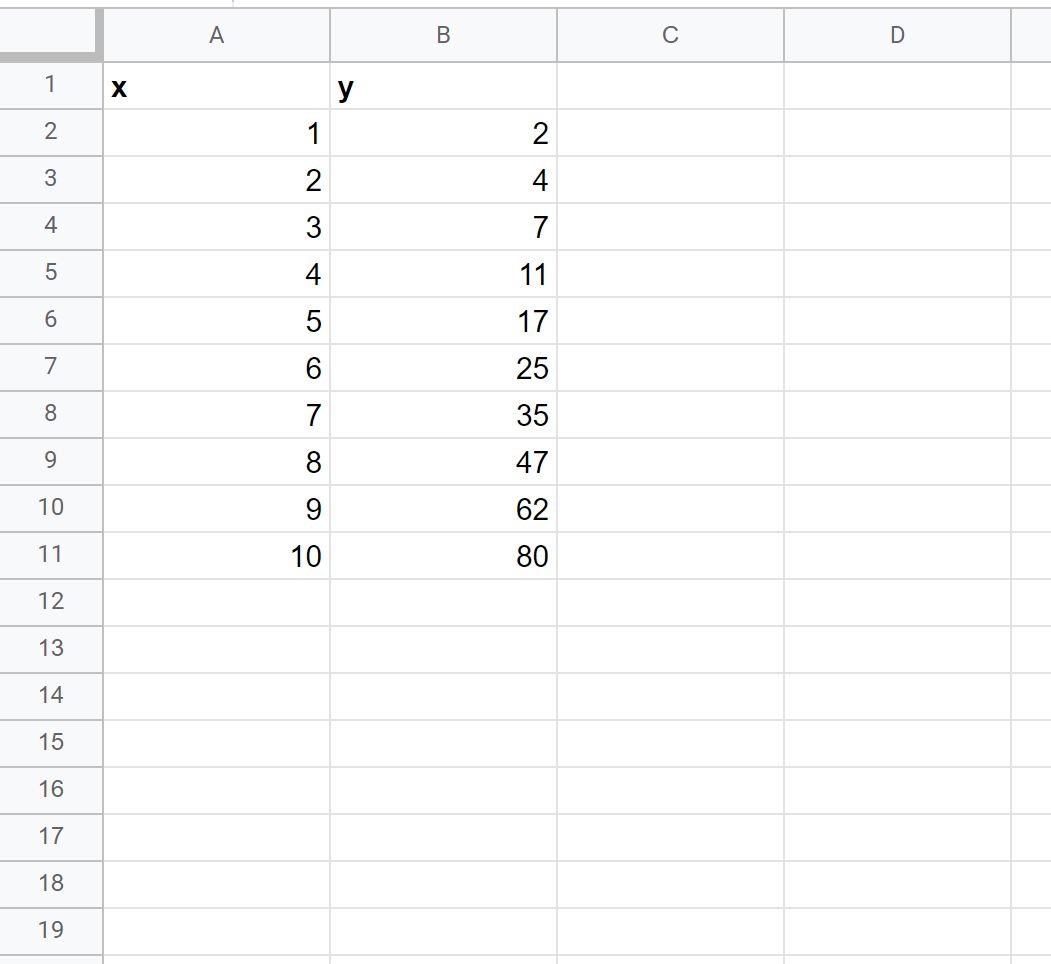
Krok 1: Wprowadź dane
Najpierw wprowadźmy następujący zestaw danych do Arkuszy Google:
Krok 2: Wizualizuj dane
Następnie utwórzmy szybki wykres rozrzutu x względem y, aby sprawdzić, czy dane faktycznie układają się po krzywej wykładniczej:
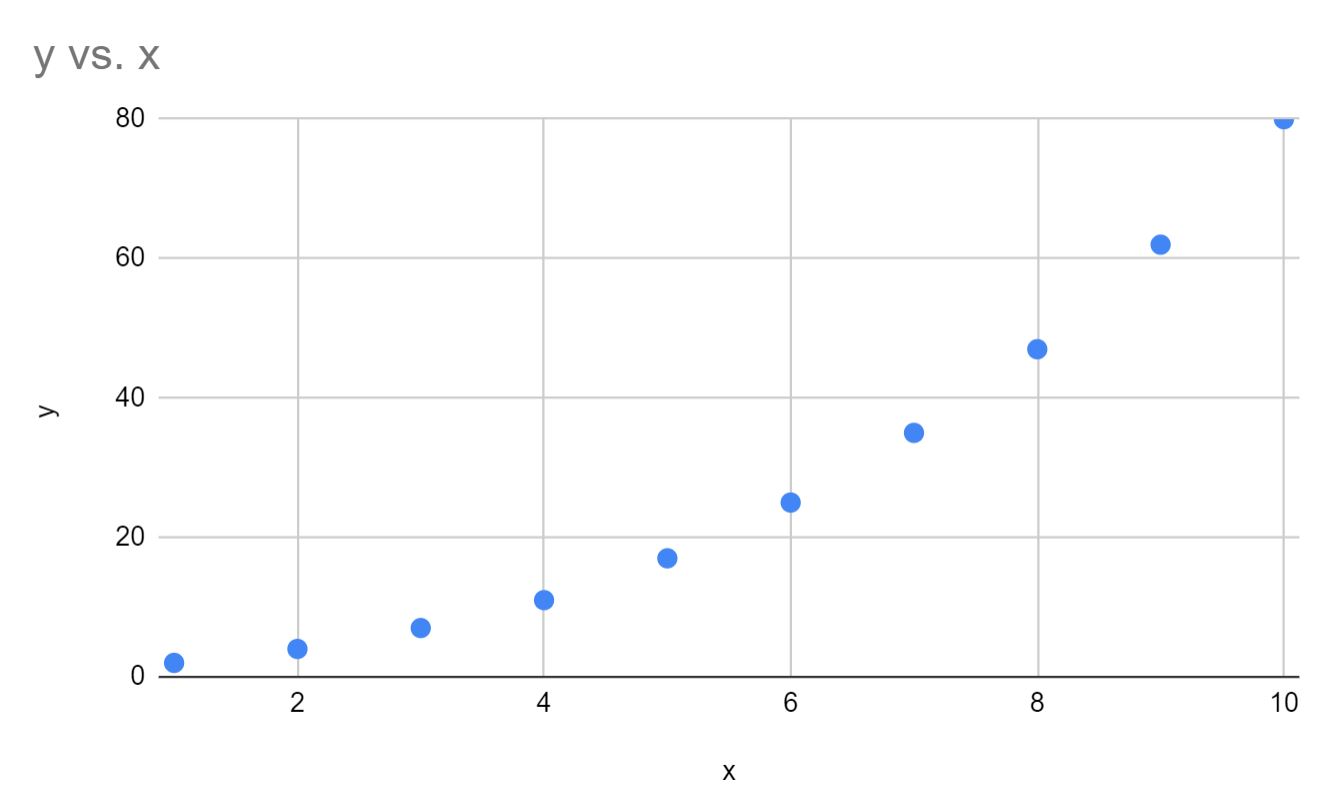
Widzimy, że dane rzeczywiście podążają po krzywej wykładniczej.
Krok 3: Użyj LOGEST, aby znaleźć wzór na krzywą wykładniczą
Następnie możemy wpisać następującą formułę w dowolnej komórce, aby obliczyć formułę krzywej wykładniczej:
=LOGEST( B2:B11 , A2:A11 )
Poniższy zrzut ekranu pokazuje, jak zastosować tę formułę w praktyce:
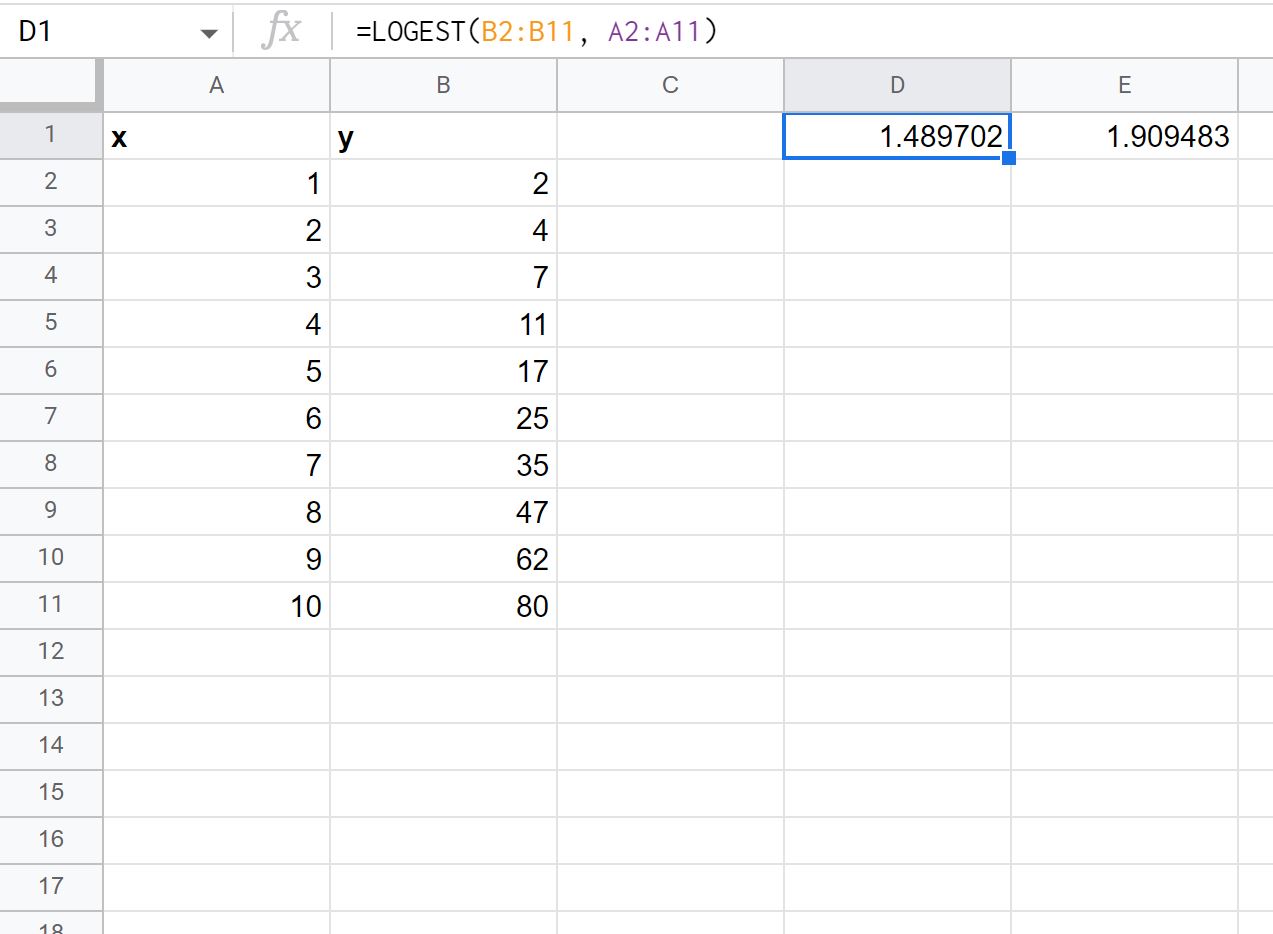
Pierwsza wartość wyniku reprezentuje wartość m , a druga wartość wyniku reprezentuje wartość b w równaniu:
y = b* mx
Zapisalibyśmy więc ten wzór na krzywą wykładniczą w następujący sposób:
y = 1,909483 * 1,489702x
Moglibyśmy następnie użyć tego wzoru do przewidzenia wartości y na podstawie wartości x.
Na przykład, jeśli xa ma wartość 8, to przewidujemy, że y ma wartość 46,31 :
y = 1,909483 * 1,489702 8 = 46,31
Krok 4 (opcjonalnie): Wyświetl dodatkowe statystyki regresji
Możemy ustawić szczegółową wartość argumentu w funkcji LOGEST na PRAWDA , aby wyświetlić dodatkowe statystyki regresji dla dopasowanego równania regresji:
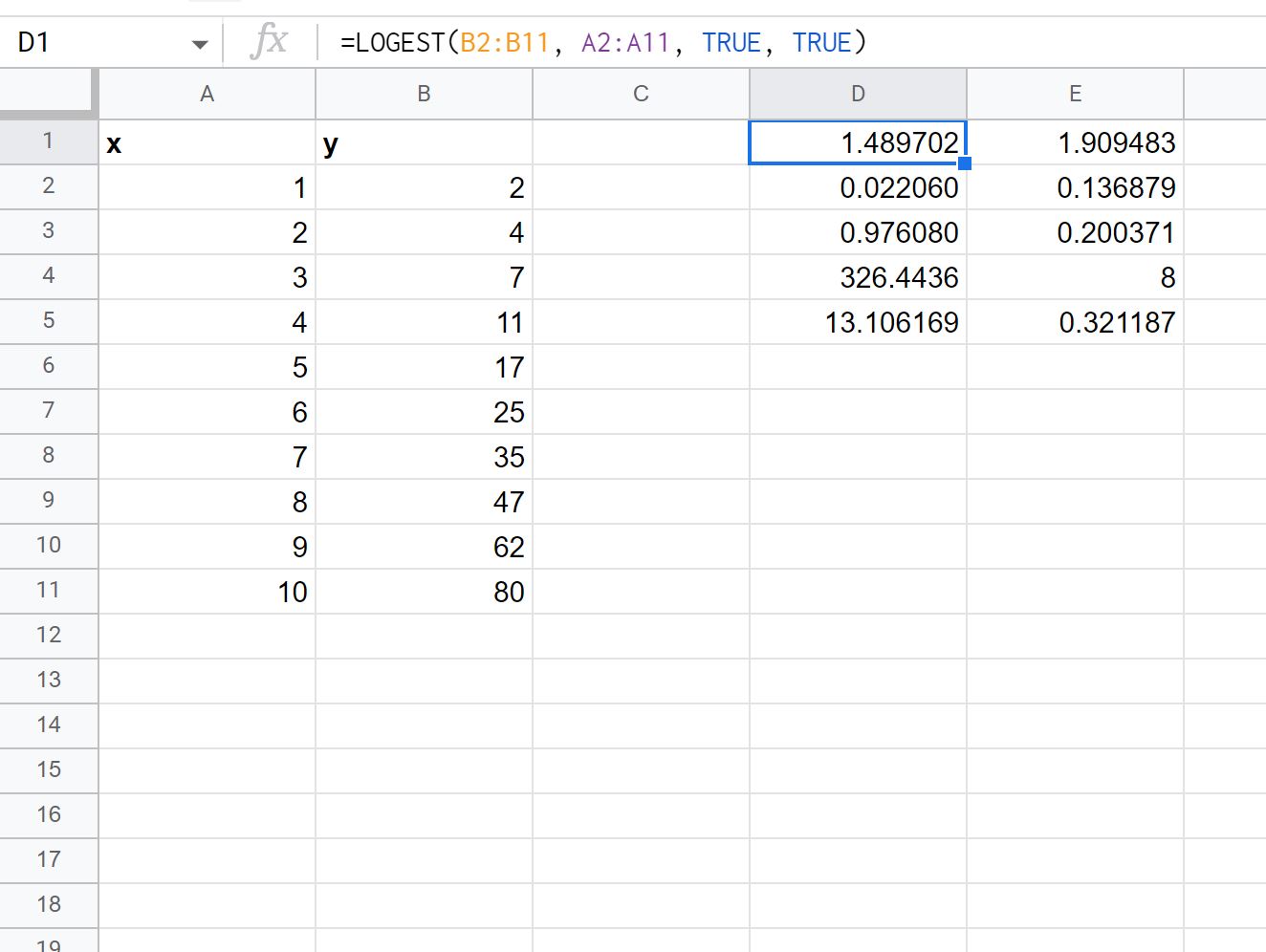
Oto jak interpretować każdą wartość w wyniku:
- Standardowy błąd dla m wynosi 0,02206 .
- Błąd standardowy dla b wynosi 0,136879 .
- R 2 modelu to .97608 .
- Standardowy błąd dla y to .200371 .
- Statystyka F to 326,4436 .
- Stopnie swobody wynoszą 8 .
- Suma kwadratów regresji wynosi 13,106169 .
- Pozostała suma kwadratów wynosi 0,321187 .
Ogólnie rzecz biorąc, miarą cieszącą się największym zainteresowaniem w tych dodatkowych statystykach jest wartość R2 , która reprezentuje proporcję wariancji zmiennej odpowiedzi, którą można wyjaśnić zmienną predykcyjną.
Wartość R2 może zmieniać się od 0 do 1.
Ponieważ R 2 tego konkretnego modelu jest bliskie 1, mówi nam to, że zmienna predykcyjna x dobrze przewiduje wartość zmiennej odpowiedzi y.
Powiązane: Jaka jest dobra wartość R-kwadrat?
Dodatkowe zasoby
Poniższe samouczki wyjaśniają, jak wykonywać inne typowe czynności w Arkuszach Google:
Jak wykonać regresję liniową w Arkuszach Google
Jak wykonać regresję wielomianową w Arkuszach Google
Jak obliczyć R-kwadrat w Arkuszach Google
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej