Regresja lasso w r (krok po kroku)
Regresja Lasso to metoda, której możemy użyć do dopasowania modelu regresji, gdy w danych występuje współliniowość .
W skrócie, regresja metodą najmniejszych kwadratów próbuje znaleźć oszacowania współczynników, które minimalizują rezydualną sumę kwadratów (RSS):
RSS = Σ(y i – ŷ i )2
Złoto:
- Σ : Grecki symbol oznaczający sumę
- y i : rzeczywista wartość odpowiedzi dla i-tej obserwacji
- ŷ i : Przewidywana wartość odpowiedzi na podstawie modelu wielokrotnej regresji liniowej
I odwrotnie, regresja lasso ma na celu zminimalizowanie następujących elementów:
RSS + λΣ|β j |
gdzie j przechodzi od 1 do p zmiennych predykcyjnych i λ ≥ 0.
Ten drugi człon równania nazywany jest karą za wycofanie . W regresji lasso wybieramy wartość λ, która daje najniższy możliwy test MSE (średni błąd kwadratowy).
W tym samouczku przedstawiono krok po kroku przykład wykonania regresji lasso w języku R.
Krok 1: Załaduj dane
W tym przykładzie użyjemy wbudowanego zbioru danych R o nazwie mtcars . Użyjemy hp jako zmiennej odpowiedzi i następujących zmiennych jako predyktorów:
- mpg
- waga
- gówno
- sek
Do wykonania regresji lasso wykorzystamy funkcje z pakietu glmnet . Pakiet ten wymaga, aby zmienna odpowiedzi była wektorem, a zestaw zmiennych predykcyjnych był klasy data.matrix .
Poniższy kod pokazuje jak zdefiniować nasze dane:
#define response variable
y <- mtcars$hp
#define matrix of predictor variables
x <- data.matrix(mtcars[, c('mpg', 'wt', 'drat', 'qsec')])
Krok 2: Dopasuj model regresji Lasso
Następnie użyjemy funkcji glmnet() , aby dopasować model regresji lasso i określić alpha=1 .
Należy pamiętać, że ustawienie alfa równego 0 jest równoznaczne z użyciem regresji grzbietu , a ustawienie alfa na wartość z zakresu od 0 do 1 jest równoznaczne z użyciem elastycznej siatki.
Aby określić, której wartości użyć dla lambda, przeprowadzimy k-krotną weryfikację krzyżową i zidentyfikujemy wartość lambda, która daje najniższy testowy błąd średniokwadratowy (MSE).
Należy zauważyć, że funkcja cv.glmnet() automatycznie wykonuje k-krotną weryfikację krzyżową, stosując k = 10 razy.
library (glmnet)
#perform k-fold cross-validation to find optimal lambda value
cv_model <- cv. glmnet (x, y, alpha = 1 )
#find optimal lambda value that minimizes test MSE
best_lambda <- cv_model$ lambda . min
best_lambda
[1] 5.616345
#produce plot of test MSE by lambda value
plot(cv_model)
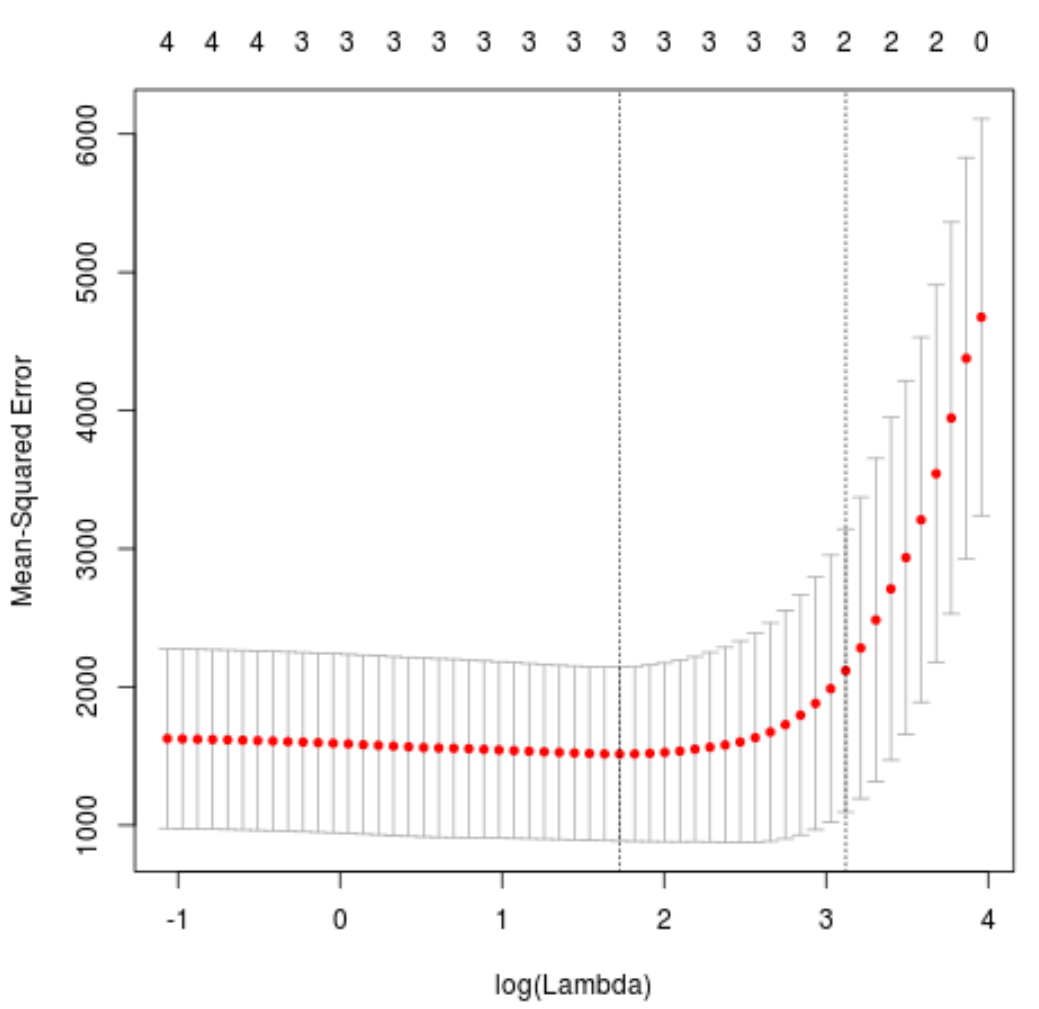
Wartość lambda minimalizująca test MSE okazuje się wynosić 5,616345 .
Krok 3: Przeanalizuj ostateczny model
Na koniec możemy przeanalizować ostateczny model uzyskany na podstawie optymalnej wartości lambda.
Aby uzyskać estymatory współczynników dla tego modelu, możemy użyć następującego kodu:
#find coefficients of best model
best_model <- glmnet(x, y, alpha = 1 , lambda = best_lambda)
coef(best_model)
5 x 1 sparse Matrix of class "dgCMatrix"
s0
(Intercept) 484.20742
mpg -2.95796
wt 21.37988
drat.
qsec -19.43425
Dla predyktora drat nie pokazano żadnego współczynnika, ponieważ regresja lasso zmniejszyła współczynnik do zera. Oznacza to, że został całkowicie usunięty z modelu, ponieważ nie miał wystarczających wpływów.
Należy zauważyć, że jest to kluczowa różnica między regresją grzbietu a regresją lassa . Regresja grzbietowa redukuje wszystkie współczynniki do zera, ale regresja lasso może usunąć predyktory z modelu poprzez całkowite zmniejszenie współczynników do zera.
Możemy również użyć ostatecznego modelu regresji lassa, aby przewidzieć nowe obserwacje. Załóżmy na przykład, że mamy nowy samochód o następujących cechach:
- mpg: 24
- waga: 2,5
- cena: 3,5
- sek.: 18,5
Poniższy kod pokazuje, jak używać dopasowanego modelu regresji lasso do przewidywania wartości hp tej nowej obserwacji:
#define new observation
new = matrix(c(24, 2.5, 3.5, 18.5), nrow= 1 , ncol= 4 )
#use lasso regression model to predict response value
predict(best_model, s = best_lambda, newx = new)
[1,] 109.0842
Na podstawie wprowadzonych wartości model przewiduje, że ten samochód będzie miał wartość KM wynoszącą 109,0842 .
Na koniec możemy obliczyć R-kwadrat modelu na danych treningowych:
#use fitted best model to make predictions
y_predicted <- predict (best_model, s = best_lambda, newx = x)
#find OHS and SSE
sst <- sum ((y - mean (y))^2)
sse <- sum ((y_predicted - y)^2)
#find R-Squared
rsq <- 1 - sse/sst
rsq
[1] 0.8047064
Okazuje się, że R kwadrat wynosi 0,8047064 . Oznacza to, że najlepszy model był w stanie wyjaśnić 80,47% zmienności wartości odpowiedzi danych treningowych.
Pełny kod R użyty w tym przykładzie znajdziesz tutaj .
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej