Regresja wielomianowa w r (krok po kroku)
Regresja wielomianowa to technika, którą możemy zastosować, gdy związek między zmienną predykcyjną a zmienną odpowiedzi jest nieliniowy.
Ten typ regresji ma postać:
Y = β 0 + β 1 X + β 2 X 2 + … + β godz
gdzie h jest „stopniem” wielomianu.
W tym samouczku przedstawiono krok po kroku przykład wykonania regresji wielomianowej w języku R.
Krok 1: Utwórz dane
Na potrzeby tego przykładu utworzymy zbiór danych zawierający liczbę przepracowanych godzin i ocenę końcową z egzaminu dla klasy liczącej 50 uczniów:
#make this example reproducible set.seed(1) #create dataset df <- data.frame(hours = runif (50, 5, 15), score=50) df$score = df$score + df$hours^3/150 + df$hours* runif (50, 1, 2) #view first six rows of data head(data) hours score 1 7.655087 64.30191 2 8.721239 70.65430 3 10.728534 73.66114 4 14.082078 86.14630 5 7.016819 59.81595 6 13.983897 83.60510
Krok 2: Wizualizuj dane
Zanim dopasujemy model regresji do danych, utwórzmy najpierw wykres rozrzutu, aby zwizualizować związek między przestudiowanymi godzinami a wynikiem egzaminu:
library (ggplot2) ggplot(df, aes (x=hours, y=score)) + geom_point()
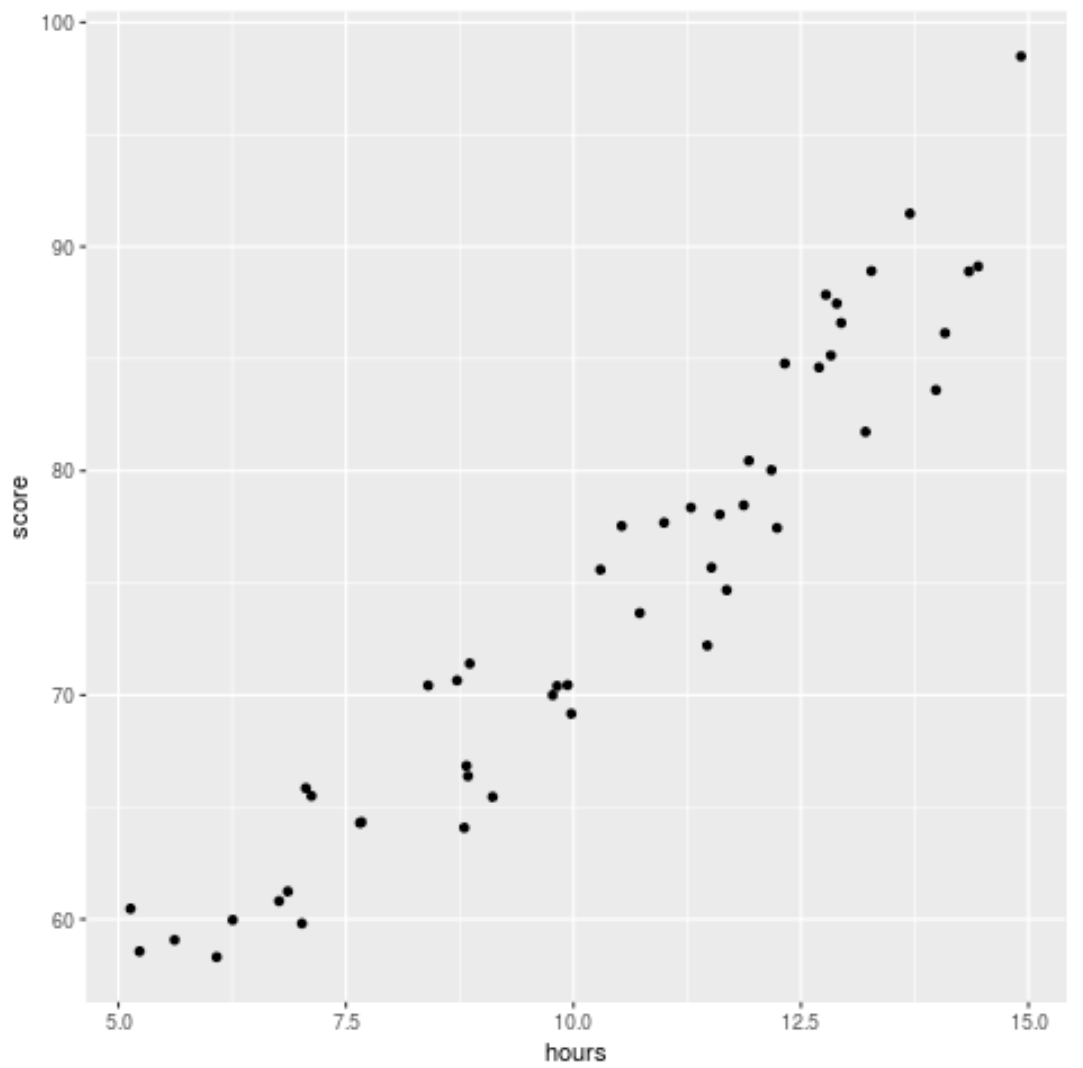
Widzimy, że dane mają lekko kwadratową zależność, co wskazuje, że regresja wielomianowa może lepiej dopasować dane niż zwykła regresja liniowa.
Krok 3: Dopasuj modele regresji wielomianowej
Następnie dopasujemy pięć różnych modeli regresji wielomianowej o stopniach h = 1…5 i zastosujemy k-krotną weryfikację krzyżową z k = 10 razy, aby obliczyć test MSE dla każdego modelu:
#randomly shuffle data
df.shuffled <- df[ sample ( nrow (df)),]
#define number of folds to use for k-fold cross-validation
K <- 10
#define degree of polynomials to fit
degree <- 5
#create k equal-sized folds
folds <- cut( seq (1, nrow (df.shuffled)), breaks=K, labels= FALSE )
#create object to hold MSE's of models
mse = matrix(data=NA,nrow=K,ncol=degree)
#Perform K-fold cross validation
for (i in 1:K){
#define training and testing data
testIndexes <- which (folds==i,arr.ind= TRUE )
testData <- df.shuffled[testIndexes, ]
trainData <- df.shuffled[-testIndexes, ]
#use k-fold cv to evaluate models
for (j in 1:degree){
fit.train = lm (score ~ poly (hours,d), data=trainData)
fit.test = predict (fit.train, newdata=testData)
mse[i,j] = mean ((fit.test-testData$score)^2)
}
}
#find MSE for each degree
colMeans(mse)
[1] 9.802397 8.748666 9.601865 10.592569 13.545547
Z wyniku możemy zobaczyć test MSE dla każdego modelu:
- Test MSE ze stopniem h = 1: 9,80
- Test MSE ze stopniem h = 2: 8,75
- Test MSE ze stopniem h = 3: 9,60
- Test MSE ze stopniem h = 4: 10,59
- Test MSE ze stopniem h = 5: 13,55
Modelem o najniższym teście MSE okazał się model regresji wielomianowej o stopniu h = 2.
Odpowiada to naszej intuicji z pierwotnego wykresu rozrzutu: model regresji kwadratowej najlepiej pasuje do danych.
Krok 4: Przeanalizuj ostateczny model
Wreszcie możemy uzyskać współczynniki modelu o najlepszych wynikach:
#fit best model best = lm (score ~ poly (hours,2, raw= T ), data=df) #view summary of best model summary(best) Call: lm(formula = score ~ poly(hours, 2, raw = T), data = df) Residuals: Min 1Q Median 3Q Max -5.6589 -2.0770 -0.4599 2.5923 4.5122 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 54.00526 5.52855 9.768 6.78e-13 *** poly(hours, 2, raw = T)1 -0.07904 1.15413 -0.068 0.94569 poly(hours, 2, raw = T)2 0.18596 0.05724 3.249 0.00214 ** --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Na podstawie wyniku widzimy, że ostatecznie dopasowany model to:
Wynik = 54,00526 – 0,07904*(godziny) + 0,18596*(godziny) 2
Możemy użyć tego równania do oszacowania wyniku, jaki otrzyma student na podstawie liczby przestudiowanych godzin.
Przykładowo student studiujący 10 godzin powinien otrzymać ocenę 71,81 :
Wynik = 54,00526 – 0,07904*(10) + 0,18596*(10) 2 = 71,81
Możemy również wykreślić dopasowany model, aby sprawdzić, jak dobrze pasuje do surowych danych:
ggplot(df, aes (x=hours, y=score)) + geom_point() + stat_smooth(method=' lm ', formula = y ~ poly (x,2), size = 1) + xlab(' Hours Studied ') + ylab(' Score ')
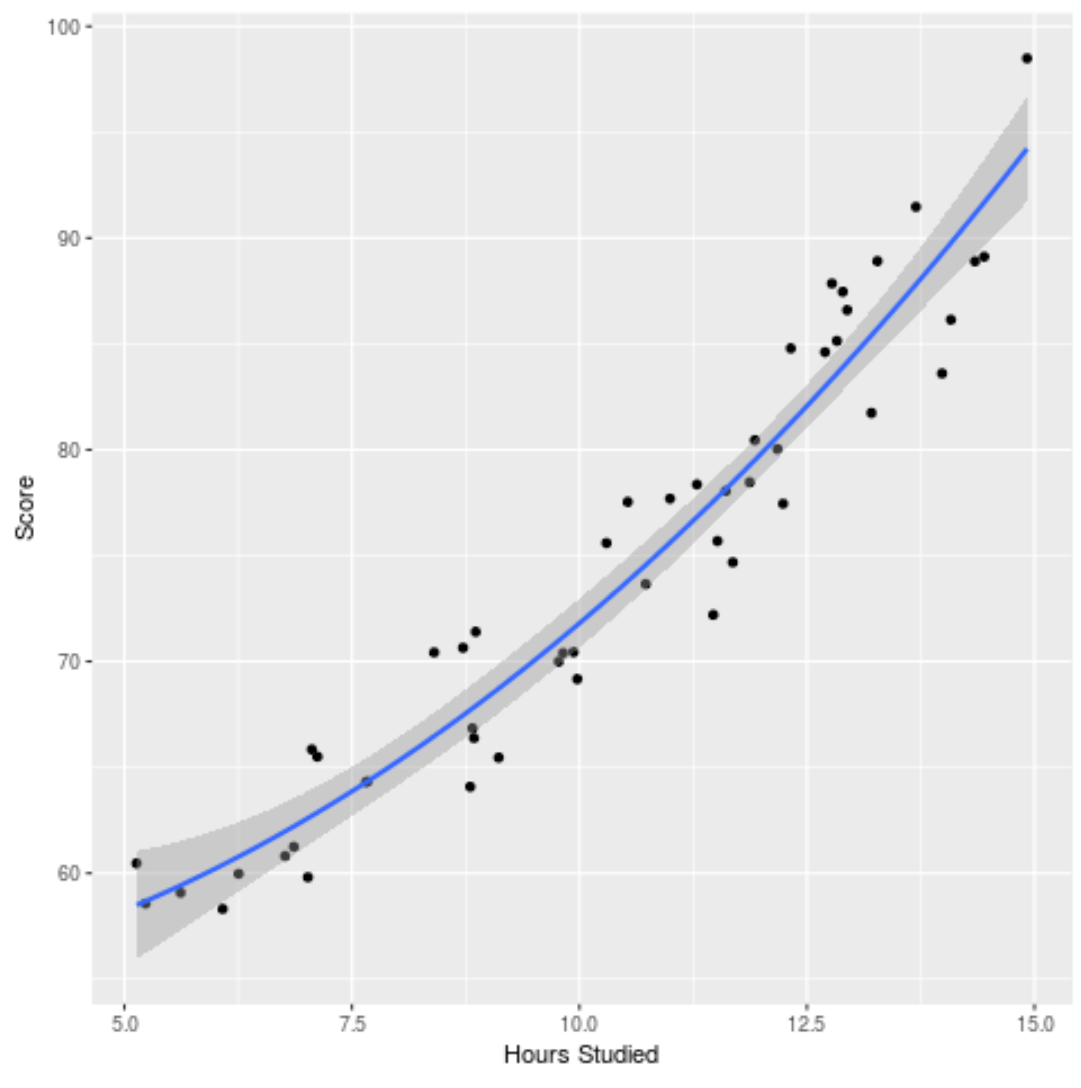
Pełny kod R użyty w tym przykładzie znajdziesz tutaj .
o autorze
Dr Benjamin Anderson
Cześć, jestem Benjamin i jestem emerytowanym profesorem statystyki, który został oddanym nauczycielem Statorials. Dzięki bogatemu doświadczeniu i wiedzy specjalistycznej w dziedzinie statystyki chętnie dzielę się swoją wiedzą, aby wzmocnić pozycję uczniów za pośrednictwem Statorials. Wiedzieć więcej