
Régression ou classification : quelle est la différence ?
Les algorithmes d’apprentissage automatique peuvent être divisés en deux types distincts : les algorithmes d’apprentissage supervisé et non supervisé .

Les algorithmes d’apprentissage supervisé peuvent être classés en deux types :
1. Régression : La variable de réponse est continue.
Par exemple, la variable de réponse pourrait être :
- Poids
- Hauteur
- Prix
- Temps
- Unités totales
Dans chaque cas, un modèle de régression cherche à prédire une quantité continue.
Exemple de régression :
Supposons que nous disposions d’un ensemble de données contenant trois variables pour 100 maisons différentes : la superficie en pieds carrés, le nombre de salles de bains et le prix de vente.
Nous pourrions adapter un modèle de régression qui utilise la superficie en pieds carrés et le nombre de salles de bains comme variables explicatives et le prix de vente comme variable de réponse.
Nous pourrions ensuite utiliser ce modèle pour prédire le prix de vente d’une maison, en fonction de sa superficie en pieds carrés et du nombre de salles de bains.
Il s’agit d’un exemple de modèle de régression car la variable de réponse (prix de vente) est continue.
La manière la plus courante de mesurer la précision d’un modèle de régression consiste à calculer l’erreur quadratique moyenne (RMSE), une métrique qui nous indique à quel point nos valeurs prédites sont éloignées de nos valeurs observées dans un modèle, en moyenne. Il est calculé comme suit :
RMSE = √ Σ(P je – O je ) 2 / n
où:
- Σ est un symbole fantaisiste qui signifie « somme »
- P i est la valeur prédite pour la ième observation
- O i est la valeur observée pour la ième observation
- n est la taille de l’échantillon
Plus le RMSE est petit, mieux un modèle de régression est capable de s’adapter aux données.
2. Classification : La variable de réponse est catégorique.
Par exemple, la variable de réponse pourrait prendre les valeurs suivantes :
- Mâle ou femelle
- Réussir ou échouer
- Faible, moyen ou élevé
Dans chaque cas, un modèle de classification cherche à prédire une étiquette de classe.
Exemple de classement :
Supposons que nous disposions d’un ensemble de données contenant trois variables pour 100 joueurs de basket-ball universitaire différents : moyenne de points par match, niveau de division et s’ils ont été repêchés ou non dans la NBA.
Nous pourrions adapter un modèle de classification qui utilise la moyenne des points par match et par niveau de division comme variables explicatives et « rédigé » comme variable de réponse.
Nous pourrions ensuite utiliser ce modèle pour prédire si un joueur donné sera ou non recruté dans la NBA en fonction de sa moyenne de points par match et de son niveau de division.
Il s’agit d’un exemple de modèle de classification car la variable de réponse (« rédigée ») est catégorielle. Autrement dit, il ne peut prendre des valeurs que dans deux catégories différentes : « Rédigé » ou « Non rédigé ».
La manière la plus courante de mesurer l’exactitude d’un modèle de classification consiste simplement à calculer le pourcentage de classifications correctes effectuées par le modèle :
Précision = classifications de correction / nombre total de tentatives de classification * 100 %
Par exemple, si un modèle identifie correctement si un joueur sera recruté ou non dans la NBA 88 fois sur 100 fois possibles, alors la précision du modèle est :
Précision = (88/100) * 100 % = 88 %
Plus la précision est élevée, plus un modèle de classification est capable de prédire les résultats.
Similitudes entre la régression et la classification
Les algorithmes de régression et de classification sont similaires des manières suivantes :
- Tous deux sont des algorithmes d’apprentissage supervisé, c’est-à-dire qu’ils impliquent tous deux une variable de réponse.
- Les deux utilisent une ou plusieurs variables explicatives pour créer des modèles permettant de prédire une réponse.
- Les deux peuvent être utilisés pour comprendre comment les changements dans les valeurs des variables explicatives affectent les valeurs d’une variable de réponse.
Différences entre régression et classification
Les algorithmes de régression et de classification diffèrent des manières suivantes :
- Les algorithmes de régression cherchent à prédire une quantité continue et les algorithmes de classification cherchent à prédire une étiquette de classe.
- La manière dont nous mesurons l’exactitude des modèles de régression et de classification diffère.
Conversion de la régression en classification
Il convient de noter qu’un problème de régression peut être converti en problème de classification en discrétisant simplement la variable de réponse en compartiments.
Par exemple, supposons que nous ayons un ensemble de données contenant trois variables : la superficie en pieds carrés, le nombre de salles de bains et le prix de vente.
Nous pourrions construire un modèle de régression utilisant la superficie en pieds carrés et le nombre de salles de bains pour prédire le prix de vente.
Cependant, nous pourrions discrétiser le prix de vente en trois classes différentes :
- 80 000 $ – 160 000 $ : « Prix de vente bas »
- 161 000 $ – 240 000 $ : « Prix de vente moyen »
- 241 000 $ – 320 000 $ : « Prix de vente élevé »
Nous pourrions alors utiliser la superficie en pieds carrés et le nombre de salles de bains comme variables explicatives pour prédire dans quelle classe (faible, moyenne ou élevée) appartiendra le prix de vente d’une maison donnée.
Ce serait un exemple de modèle de classification puisque nous essayons de placer chaque maison dans une classe.
Résumé
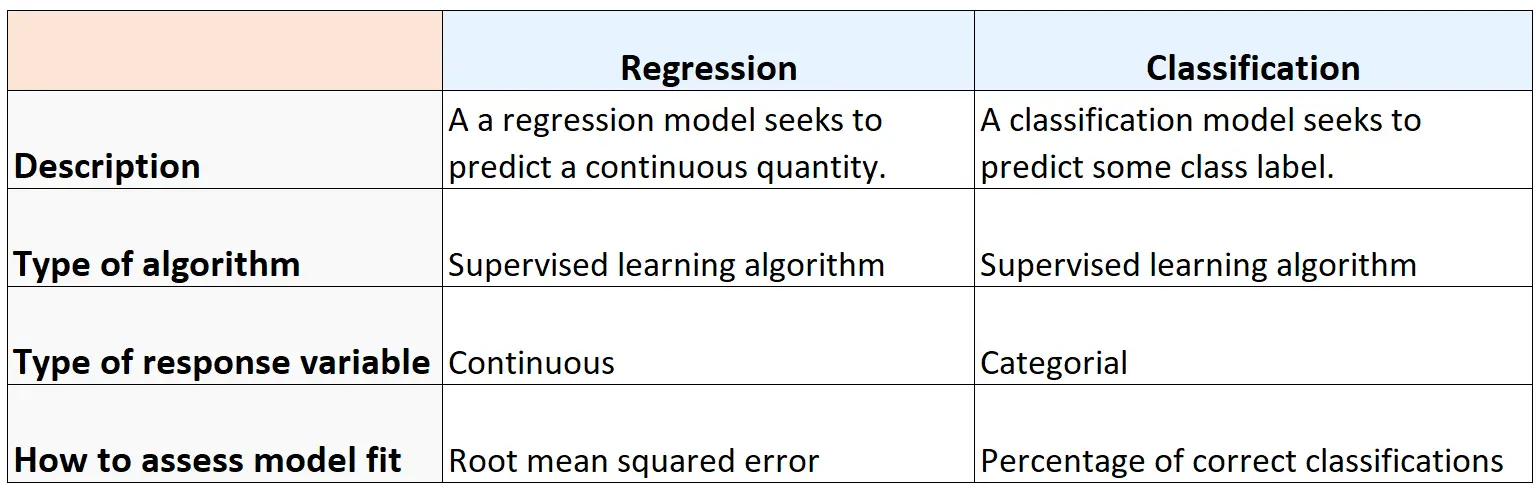
Le tableau suivant résume les similitudes et les différences entre les algorithmes de régression et de classification :
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus