
Comment tracer une distribution dans Seaborn : avec des exemples
Vous pouvez utiliser les méthodes suivantes pour tracer une distribution de valeurs en Python à l’aide de la bibliothèque de visualisation de données seaborn :
Méthode 1 : tracer la distribution à l’aide de l’histogramme
sns.displot(data)
Méthode 2 : tracer la distribution à l’aide de la courbe de densité
sns.displot(data, kind='kde')
Méthode 3 : tracer la distribution à l’aide de l’histogramme et de la courbe de densité
sns.displot(data, kde=True)
Les exemples suivants montrent comment utiliser chaque méthode dans la pratique.
Exemple 1 : tracer la distribution à l’aide d’un histogramme
Le code suivant montre comment tracer la distribution des valeurs dans un tableau NumPy à l’aide de la fonction displot() dans seaborn :
import seaborn as sns
import numpy as np
#make this example reproducible
np.random.seed(1)
#create array of 1000 values that follow a normal distribution with mean of 10
data = np.random.normal(size=1000, loc=10)
#create histogram to visualize distribution of values
sns.displot(data)
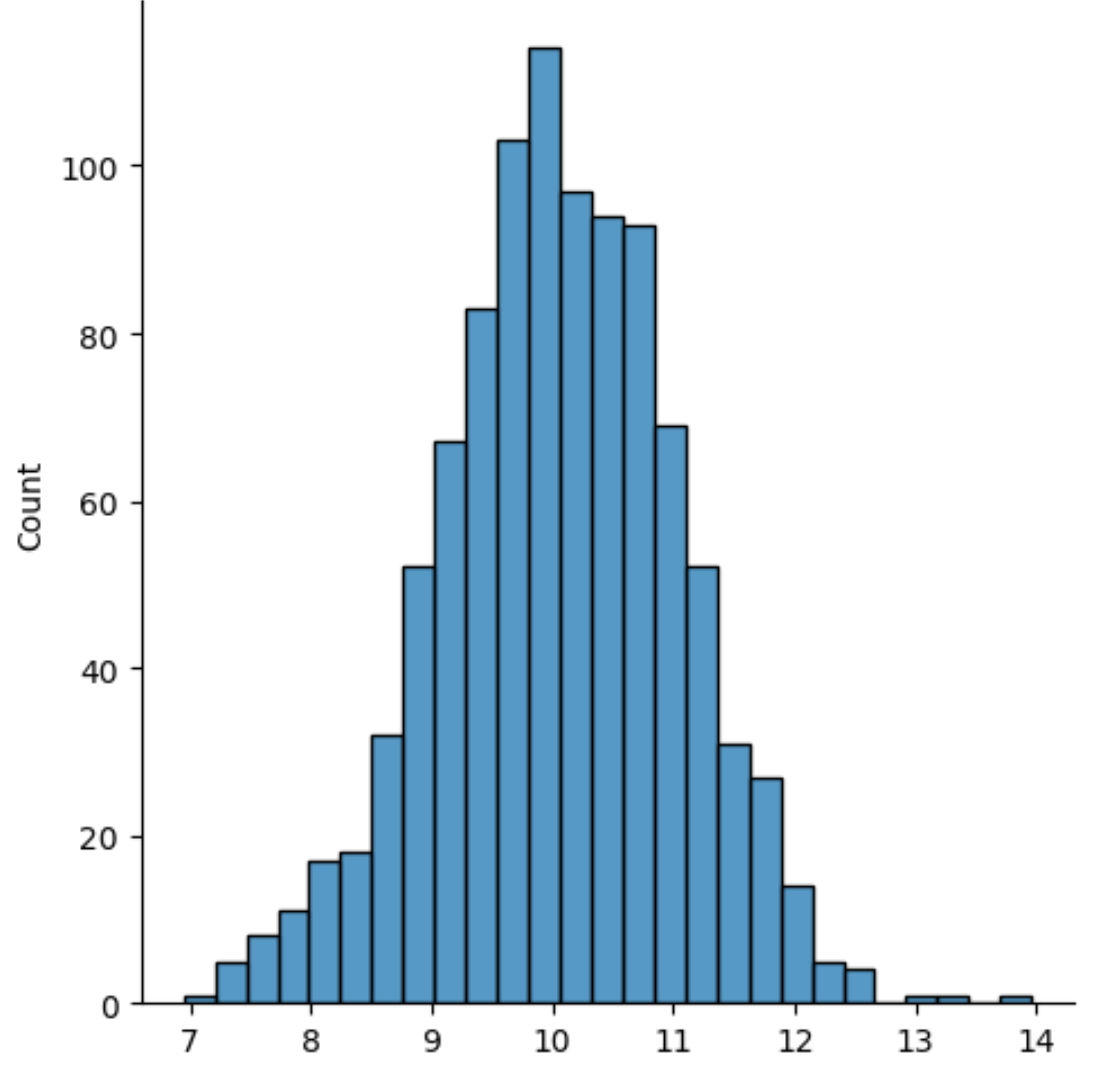
L’axe des X affiche les valeurs de la distribution et l’axe des Y affiche le nombre de chaque valeur.
Pour modifier le nombre de compartiments utilisés dans l’histogramme, vous pouvez spécifier un nombre à l’aide de l’argument bins :
import seaborn as sns
import numpy as np
#make this example reproducible
np.random.seed(1)
#create array of 1000 values that follow a normal distribution with mean of 10
data = np.random.normal(size=1000, loc=10)
#create histogram using 10 bins
sns.displot(data, bins=10)
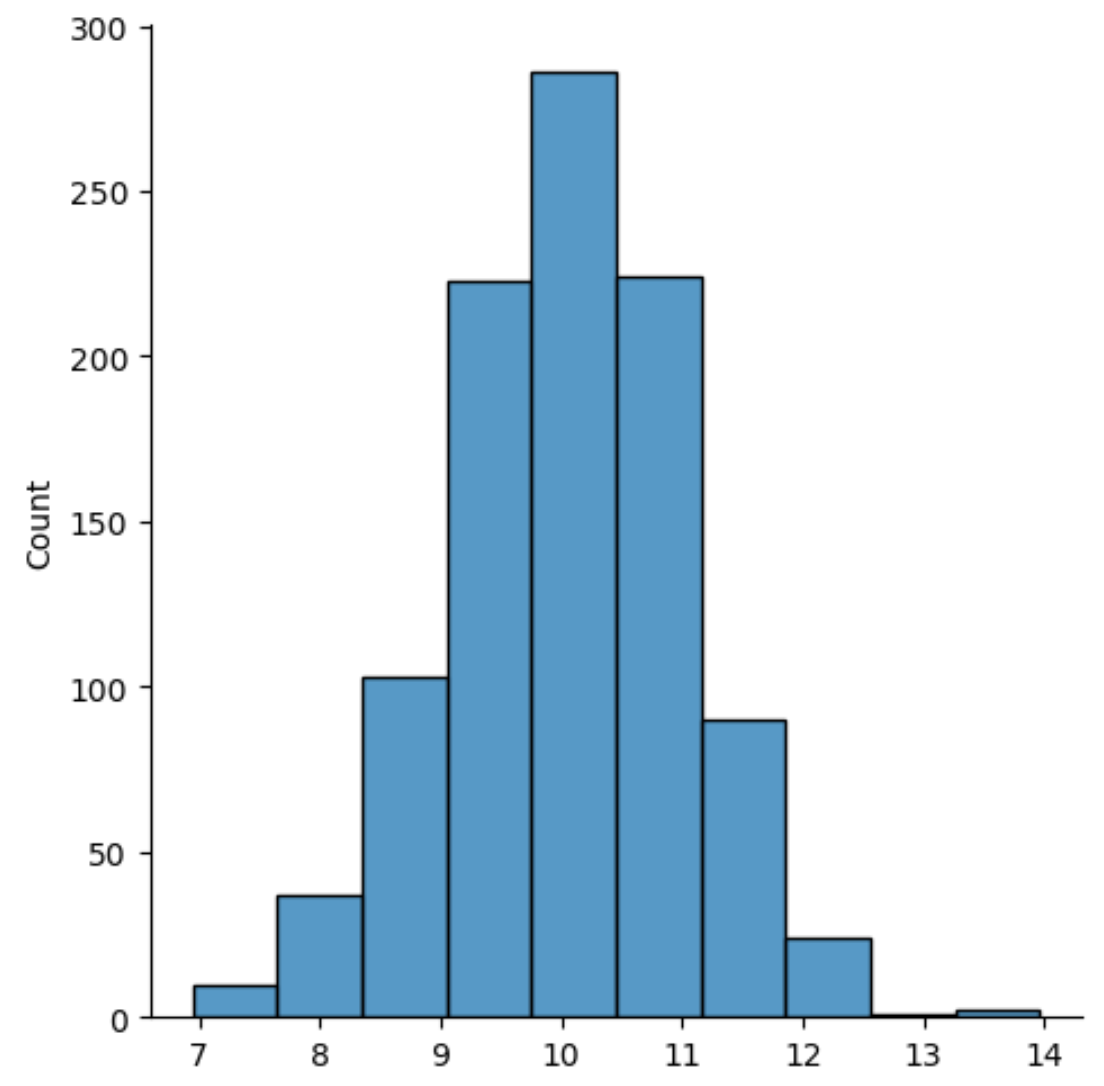
Exemple 2 : tracer la distribution à l’aide de la courbe de densité
Le code suivant montre comment tracer la distribution des valeurs dans un tableau NumPy à l’aide d’une courbe de densité :
import seaborn as sns
import numpy as np
#make this example reproducible
np.random.seed(1)
#create array of 1000 values that follow a normal distribution with mean of 10
data = np.random.normal(size=1000, loc=10)
#create density curve to visualize distribution of values
sns.displot(data, kind='kde')
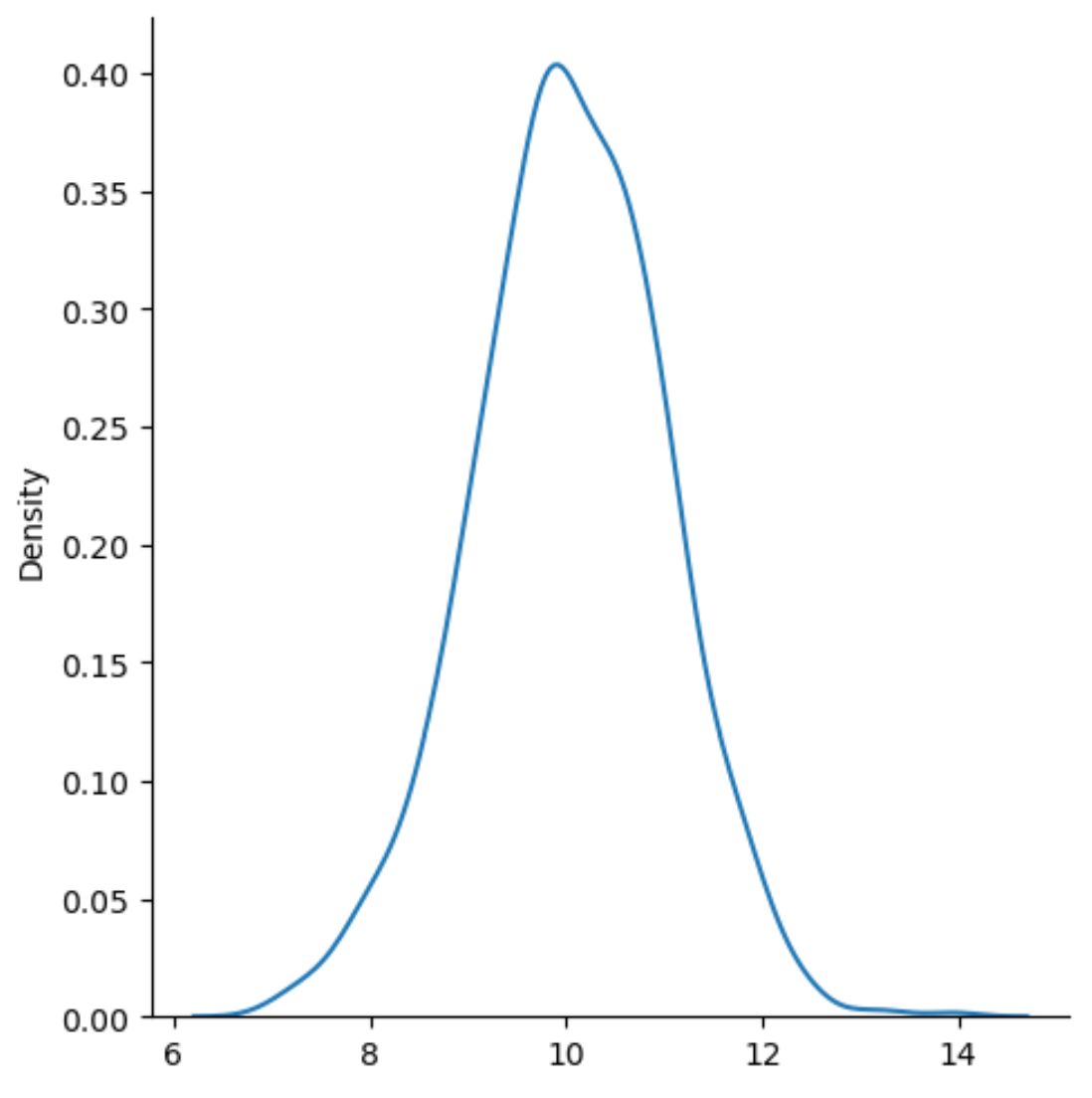
L’axe des x affiche les valeurs de la distribution et l’axe des y affiche la fréquence relative de chaque valeur.
Notez que kind=’kde’ indique à seaborn d’utiliser l’estimation de la densité du noyau , qui produit une courbe lisse qui résume la distribution des valeurs d’une variable.
Exemple 3 : tracer la distribution à l’aide de l’histogramme et de la courbe de densité
Le code suivant montre comment tracer la distribution des valeurs dans un tableau NumPy à l’aide d’un histogramme avec une courbe de densité superposée :
import seaborn as sns
import numpy as np
#make this example reproducible
np.random.seed(1)
#create array of 1000 values that follow a normal distribution with mean of 10
data = np.random.normal(size=1000, loc=10)
#create histogram with density curve overlaid to visualize distribution of values
sns.displot(data, kde=True)
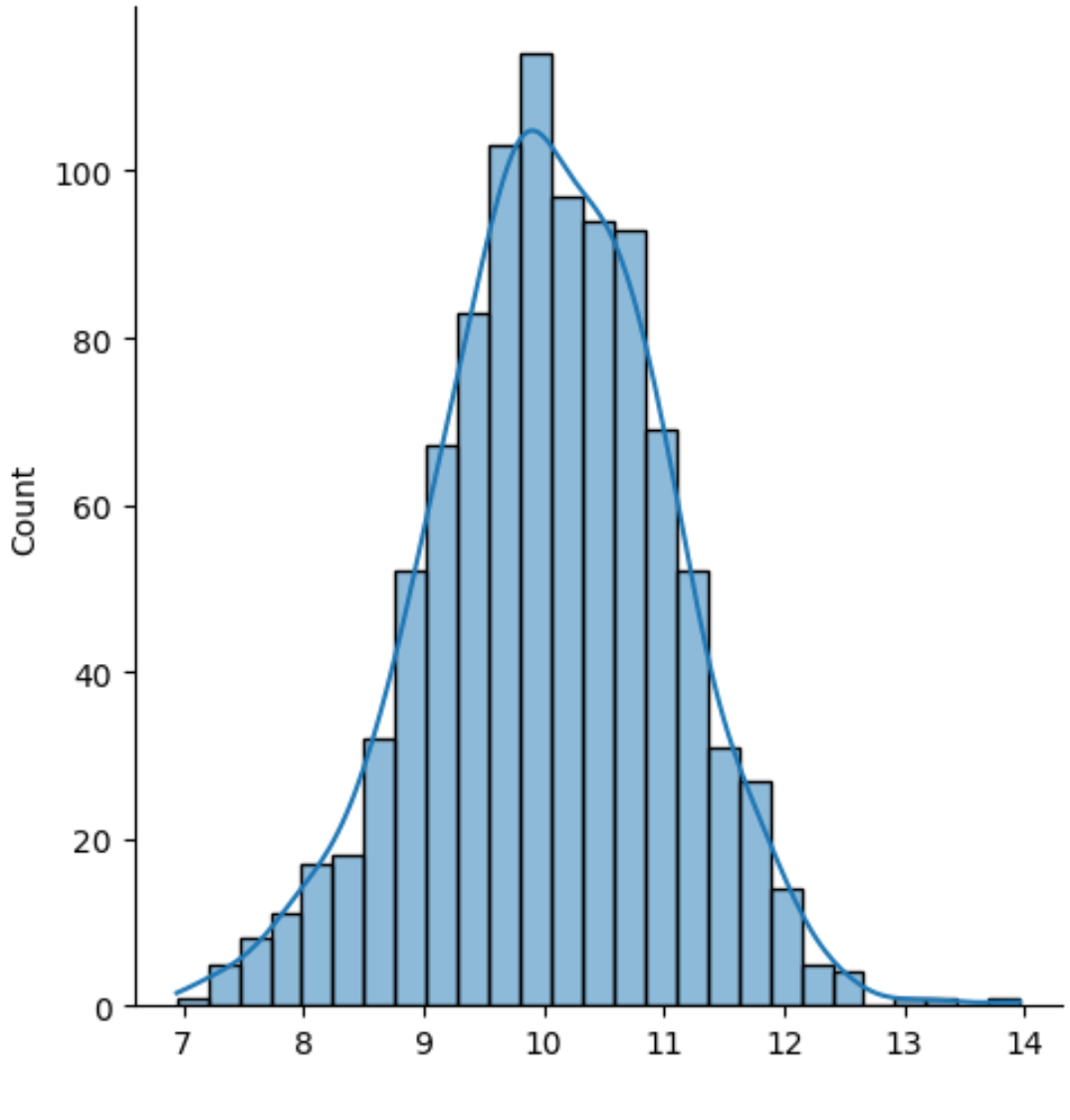
Le résultat est un histogramme avec une courbe de densité superposée.
Remarque : Vous pouvez trouver la documentation complète de la fonction seaborn displot() ici .
Ressources additionnelles
Les didacticiels suivants expliquent comment effectuer d’autres tâches courantes à l’aide de seaborn :
Comment ajouter un titre aux parcelles Seaborn
Comment changer la taille de la police dans les tracés Seaborn
Comment ajuster le nombre de ticks dans les tracés Seaborn
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus