
Comment utiliser la fonction INDEXC dans SAS
Vous pouvez utiliser la fonction INDEXC dans SAS pour renvoyer la position de la première occurrence d’un caractère individuel dans une chaîne.
Cette fonction utilise la syntaxe de base suivante :
INDEXC(source, extrait)
où:
- source : La chaîne à analyser
- extrait : La chaîne de caractères à rechercher dans la source
L’exemple suivant montre comment utiliser cette fonction dans la pratique.
Exemple : utilisation de la fonction INDEXC dans SAS
Supposons que nous ayons l’ensemble de données suivant dans SAS qui contient une colonne de noms :
/*create dataset*/
data original_data;
input name $25.;
datalines;
Andy Lincoln Bernard
Barren Michael Smith
Chad Simpson Arnolds
Derrick Smith Henrys
Eric Millerton Smith
Frank Giovanni Goode
;
run;
/*view dataset*/
proc print data=original_data;
On peut utiliser la fonction INDEXC pour rechercher la position de la première occurrence des caractères x , y ou z :
/*find position of first occurrence of either x, y or z in name*/
data new_data;
set original_data;
first_xyz = indexc(name, 'xyz');
run;
/*view results*/
proc print data=new_data;
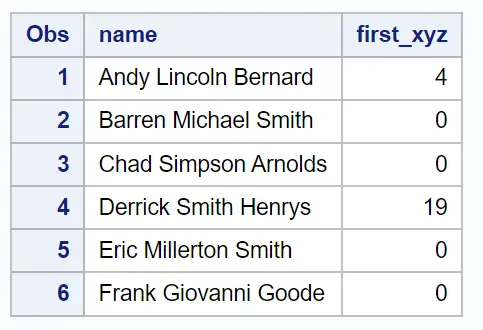
La nouvelle colonne appelée first_xyz affiche la position de la première occurrence des caractères x , y ou z dans la colonne nom .
Si aucun de ces trois caractères n’est présent dans la colonne nom , alors la fonction INDEXC renvoie simplement une valeur de 0 .
Par exemple, à partir du résultat, nous pouvons voir :
La position de la première occurrence de x, y ou z dans la première ligne est en position 4 . On peut voir que le caractère en position 4 dans la première ligne est un y .
La position de la première occurrence de x, y ou z dans la deuxième ligne est 0 car aucune de ces trois lettres n’existe dans le nom de la deuxième ligne.
Et ainsi de suite.
La différence entre les fonctions INDEX et INDEXC
La fonction INDEX dans SAS renvoie la position de la première occurrence d’une sous-chaîne particulière dans une autre chaîne.
L’exemple suivant illustre la différence entre les fonctions INDEX et INDEXC :
/*create new dataset*/
data new_data;
set original_data;
index_smith = index(name, 'Smith');
indexc_smith = indexc(name, 'Smith');
run;
/*view new dataset*/
proc print data=new_data;
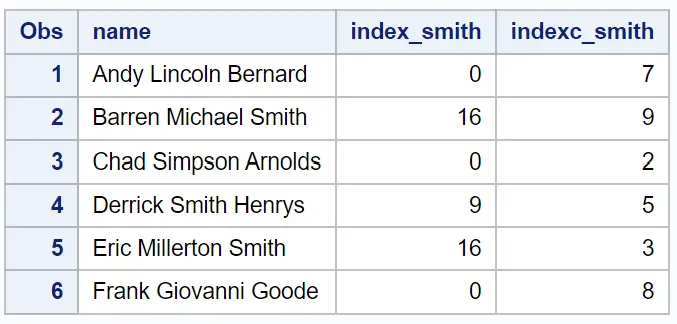
La colonne index_smith affiche la position de la première occurrence de la sous-chaîne ‘Smith’ dans la colonne nom .
La colonne indexc_smith affiche la position de la première occurrence des lettres s , m , i , t ou h dans la colonne nom .
Par exemple, à partir du résultat, nous pouvons voir :
La sous-chaîne ‘Smith’ n’apparaît jamais dans le prénom donc index_smith renvoie une valeur de 0 .
La lettre i apparaît à la 7ème position du prénom donc indexc_smith renvoie une valeur de 7 .
Et ainsi de suite.
Ressources additionnelles
Les didacticiels suivants expliquent comment utiliser d’autres fonctions courantes dans SAS :
Comment utiliser la fonction SUBSTR dans SAS
Comment utiliser la fonction COMPRESS dans SAS
Comment utiliser la fonction FIND dans SAS
Comment utiliser la fonction COALESCE dans SAS
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus