
Comment utiliser PROC CLUSTER dans SAS (avec exemple)
Le clustering est une technique d’apprentissage automatique qui tente de trouver des groupes d’ observations au sein d’un ensemble de données.
L’objectif est de trouver des clusters tels que les observations au sein de chaque cluster soient assez similaires les unes aux autres, tandis que les observations dans différents clusters sont assez différentes les unes des autres.
Le moyen le plus simple d’effectuer un clustering dans SAS consiste à utiliser PROC CLUSTER .
L’exemple suivant montre comment utiliser PROC CLUSTER dans la pratique.
Exemple : Comment utiliser PROC CLUSTER dans SAS
Supposons que nous disposions de l’ensemble de données suivant contenant des informations sur les points, les passes décisives et les rebonds de 20 joueurs de basket-ball différents :
/*create dataset*/
data my_data;
input points assists rebounds;
datalines;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run;
/*view dataset*/
proc print data=my_data;
Supposons que nous souhaitions effectuer un regroupement pour tenter d’identifier des « groupes » de joueurs ayant des statistiques similaires les uns aux autres.
Le code suivant montre comment utiliser PROC CLUSTER dans SAS pour effectuer un clustering :
/*perform clustering using points, assists and rebounds variables*/
proc cluster data=my_data method=average;
var points assists rebounds;
run;
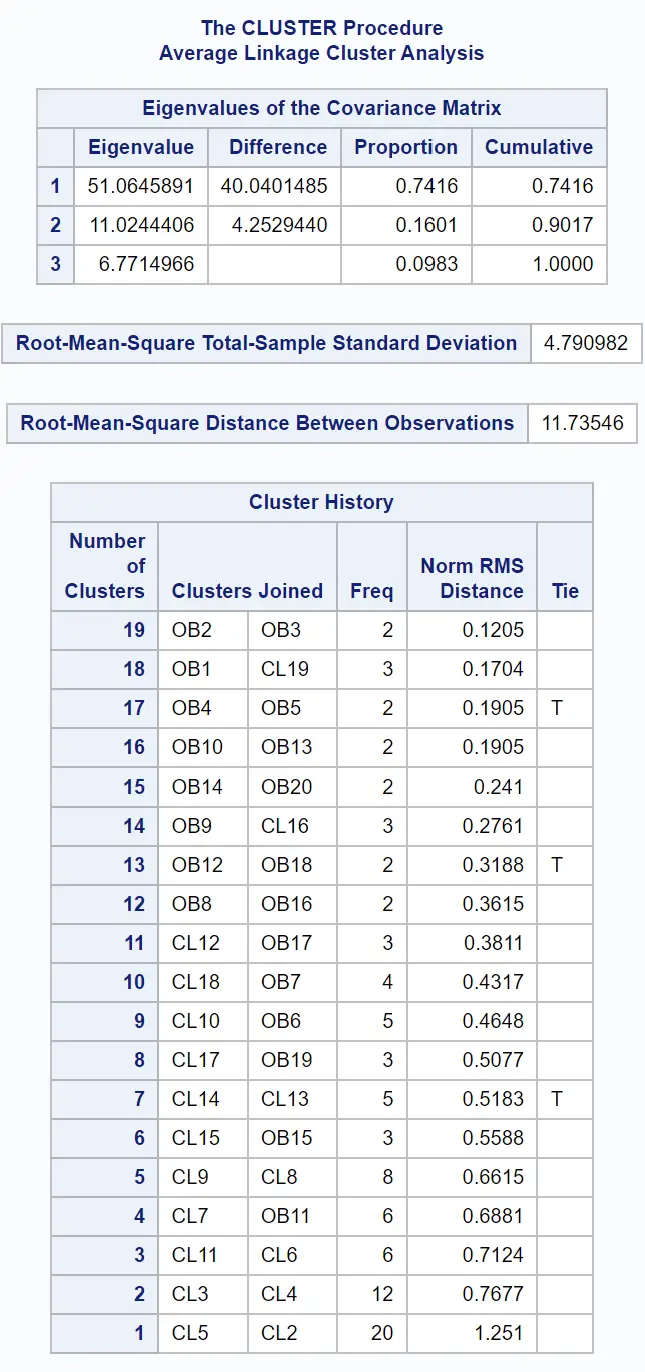
Les premiers tableaux du résultat fournissent des informations sur la façon dont le clustering a été effectué :
Un dendrogramme est également produit afin que nous puissions inspecter visuellement la similarité entre les observations de l’ensemble de données :
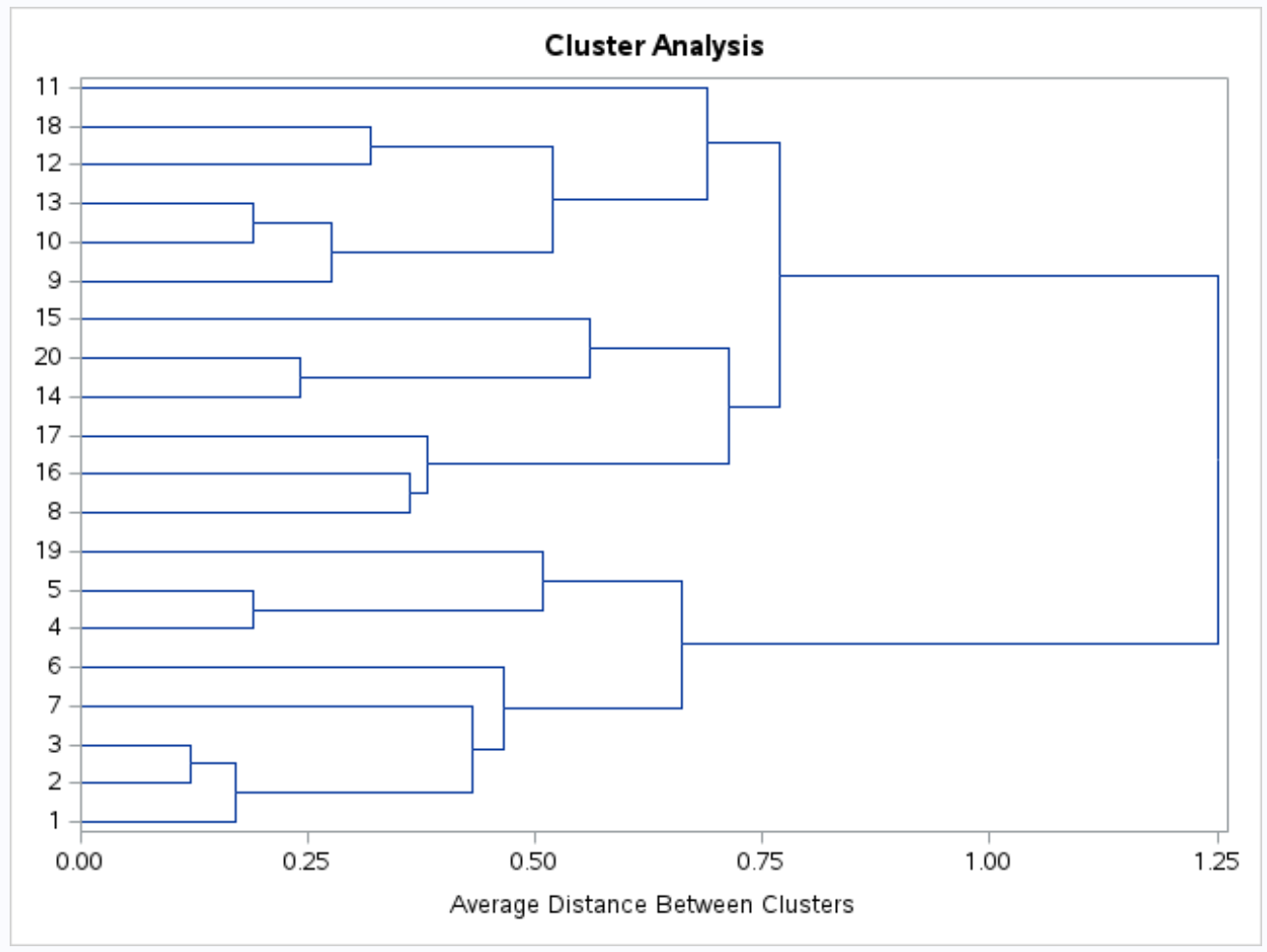
L’axe des y montre les observations individuelles et l’axe des x montre la distance moyenne entre les grappes.
En regardant ce dendrogramme, il apparaît que les observations se regroupent naturellement en trois groupes :
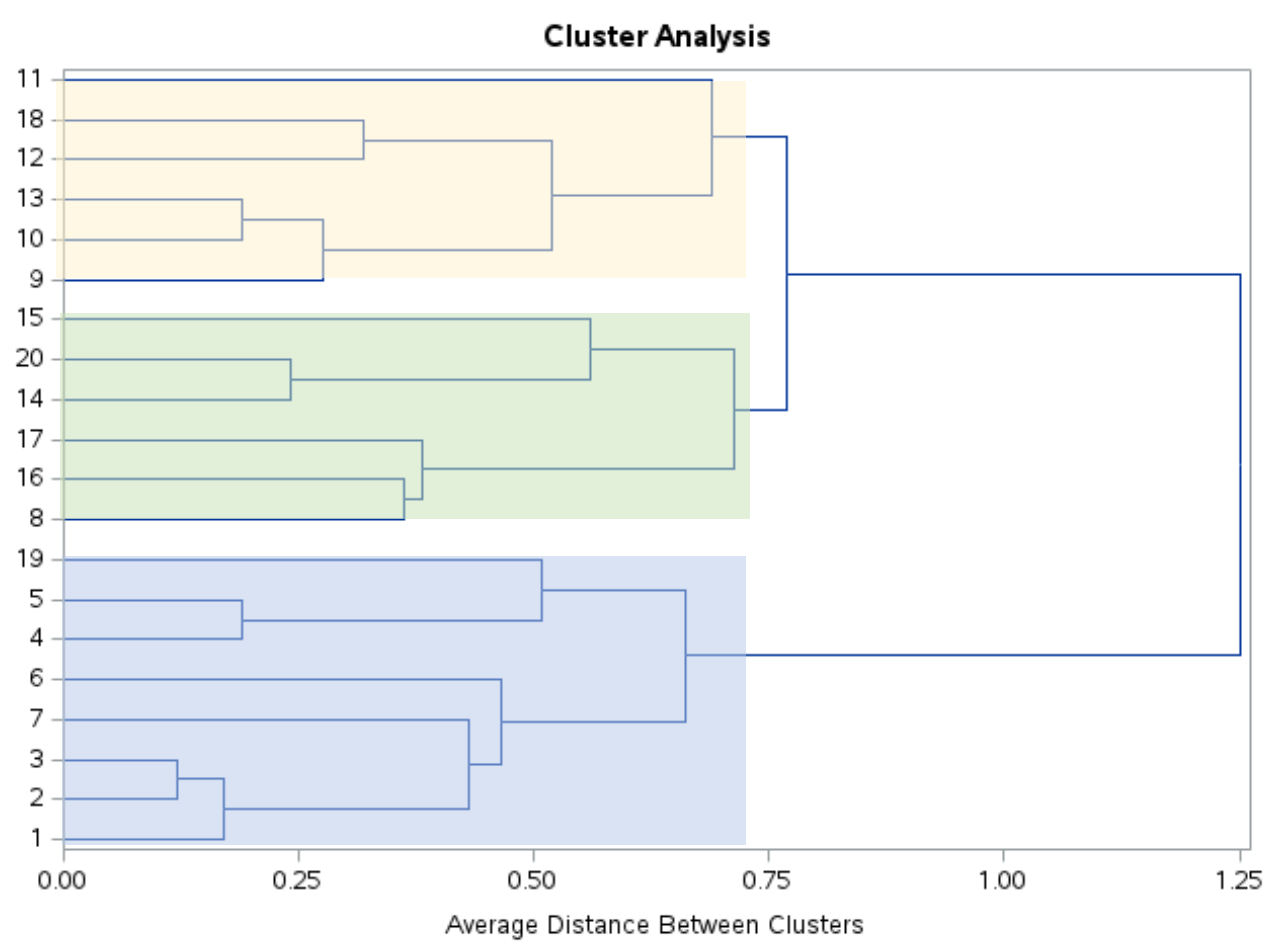
Nous pouvons ensuite utiliser l’instruction PROC TREE avec ncl=3 pour indiquer à SAS d’attribuer chaque observation de l’ensemble de données d’origine à l’un des trois clusters :
/*assign each observation to one of three clusters*/
proc tree data=clustd noprint ncl=3 out=clusts;
copy points assists rebounds;
id player_ID;
run;
proc sort;
by cluster;
run;
/*view cluster assignments*/
proc print data=clusts;
id player_ID;
run;
L’ensemble de données résultant montre chacune des observations originales ainsi que le cluster auquel elles appartiennent :
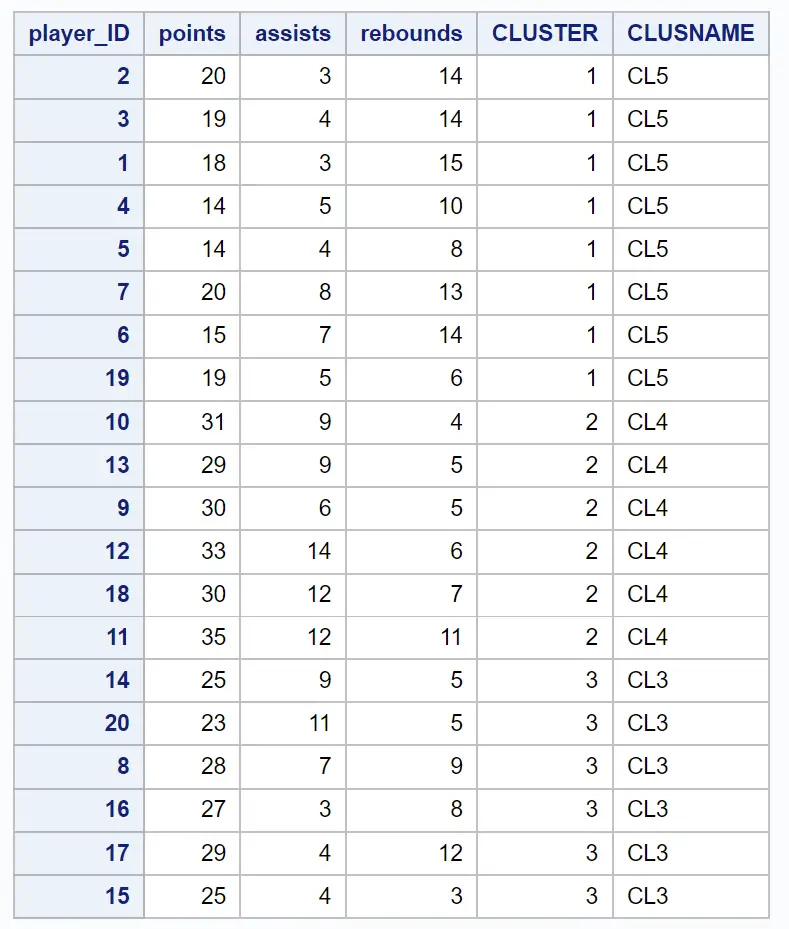
Par exemple, nous pouvons voir : que les joueurs avec les ID 2, 3, 1, 4, 5, 7, 6 et 19 appartiennent tous au cluster 1 .
Cela nous indique que ces huit joueurs sont « similaires » en termes de variables de points, de passes décisives et de rebonds.
Remarque : Pour cet exemple, nous avons choisi d’utiliser la moyenne comme méthode de liaison pour le clustering. Reportez-vous à la documentation SAS pour obtenir une liste complète des autres méthodes de liaison que vous pouvez utiliser.
Ressources additionnelles
Les didacticiels suivants expliquent comment effectuer d’autres tâches courantes dans SAS :
Comment effectuer une analyse des composantes principales dans SAS
Comment effectuer une régression linéaire multiple dans SAS
Comment effectuer une régression logistique dans SAS
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus