
Comment utiliser PROC SURVEYSELECT dans SAS (avec exemples)
Vous pouvez utiliser PROC SURVEYSELECT pour sélectionner un échantillon aléatoire à partir d’un ensemble de données dans SAS.
Voici trois façons courantes d’utiliser cette procédure dans la pratique :
Exemple 1 : utilisez PROC SURVEYSELECT pour sélectionner un échantillon aléatoire simple
proc surveyselect data=my_data
out=my_sample
method=srs /*use simple random sampling*/
n=5 /*select a total of 5 observations*/
seed=1; /*set seed to make this example reproducible*/
run;
Cet exemple particulier sélectionne 5 observations aléatoires dans l’ensemble de données.
Exemple 2 : utilisez PROC SURVEYSELECT pour sélectionner un échantillon aléatoire stratifié
proc surveyselect data=my_data
out=my_sample
method=srs /*use simple random sampling*/
n=2 /*select 2 observations from each strata*/
seed=1; /*set seed to make this example reproducible*/
strata grouping_var; /*specify variable to use for stratification*/
run;
Cet exemple particulier sélectionne 2 observations aléatoires dans chaque strate unique de l’ensemble de données.
L’instruction strata spécifie la variable à utiliser pour la stratification.
Exemple 3 : utilisez PROC SURVEYSELECT pour sélectionner un échantillon aléatoire groupé
proc surveyselect data=my_data
out=my_sample
n=2 /*select 2 clusters*/
seed=1; /*set seed to make this example reproducible*/
cluster grouping_var; /*specify variable to use for stratification*/
run;
Cet exemple particulier sélectionne 2 clusters aléatoires dans l’ensemble de données et inclut chaque observation de chaque cluster de l’échantillon.
L’instruction cluster spécifie la variable à utiliser pour le clustering.
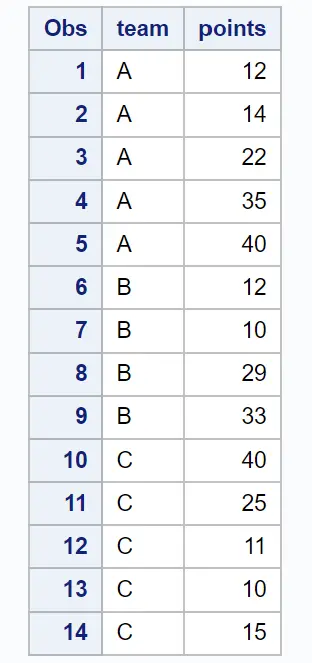
Les exemples suivants montrent comment utiliser chaque méthode en pratique avec l’ensemble de données suivant dans SAS qui contient des informations sur les joueurs de basket-ball de différentes équipes :
/*create dataset*/
data my_data;
input team $ points;
datalines;
A 12
A 14
A 22
A 35
A 40
B 12
B 10
B 29
B 33
C 40
C 25
C 11
C 10
C 15
;
run;
/*view dataset*/
proc print data = my_data;
Exemple 1 : utilisez PROC SURVEYSELECT pour sélectionner un échantillon aléatoire simple
Nous pouvons utiliser la syntaxe suivante pour sélectionner un échantillon aléatoire simple de 5 observations dans l’ensemble de données :
proc surveyselect data=my_data
out=my_sample
method=srs /*use simple random sampling*/
n=5 /*select a total of 5 observations*/
seed=1; /*set seed to make this example reproducible*/
run;
/*view sample*/
proc print data=my_sample;
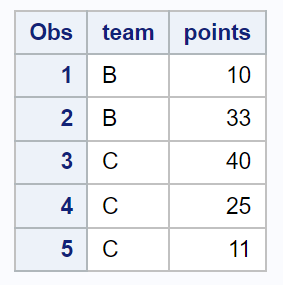
L’échantillon résultant contient 5 observations choisies au hasard dans l’ensemble des données.
Exemple 2 : utilisez PROC SURVEYSELECT pour sélectionner un échantillon aléatoire stratifié
Nous pouvons utiliser la syntaxe suivante pour effectuer un échantillonnage aléatoire stratifié dans lequel 2 observations sont choisies au hasard dans chaque équipe pour être incluses dans l’échantillon :
proc surveyselect data=my_data
out=my_sample
method=srs /*use simple random sampling within strata*/
n=2 /*select 2 observations from each strata*/
seed=1; /*set seed to make this example reproducible*/
strata grouping_var; /*specify variable to use for stratification*/
run;
/*view sample*/
proc print data=my_sample;
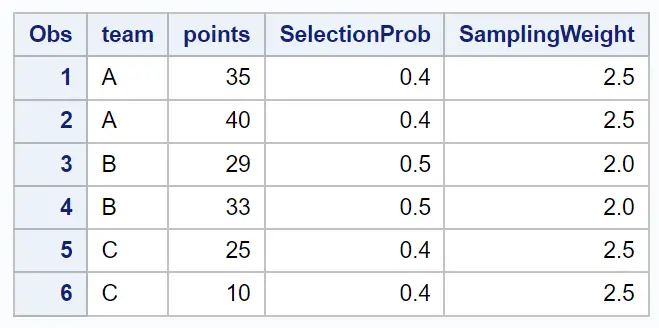
L’échantillon résultant contient 2 observations choisies au hasard dans chaque équipe.
Connexes : Échantillonnage en grappes et échantillonnage stratifié : quelle est la différence ?
Exemple 3 : utilisez PROC SURVEYSELECT pour sélectionner un échantillon aléatoire groupé
Nous pouvons utiliser la syntaxe suivante pour effectuer un échantillonnage aléatoire groupé dans lequel nous utilisons les équipes comme grappes et sélectionnons au hasard 2 grappes et incluons chaque observation de ces grappes dans l’échantillon :
proc surveyselect data=my_data
out=my_sample
n=2 /*select a total of 2 clusters*/
seed=1; /*set seed to make this example reproducible*/
cluster grouping_var; /*specify variable to use for clustering*/
run;
/*view sample*/
proc print data=my_sample;
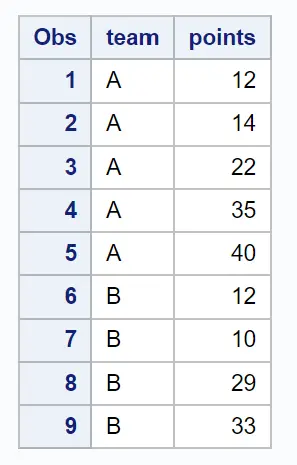
Cet échantillon particulier contient toutes les observations des équipes A et B, qui étaient les deux « clusters » choisis au hasard.
Remarque : Vous pouvez trouver la documentation complète de PROC SURVEYSELECT ici .
Ressources additionnelles
Les didacticiels suivants expliquent comment effectuer d’autres tâches courantes dans SAS :
Comment calculer des statistiques descriptives dans SAS
Comment créer des tableaux de fréquences dans SAS
Comment calculer les centiles dans SAS
Comment créer des tableaux croisés dynamiques dans SAS
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus