
Comment supprimer les doublons dans SAS (avec exemples)
Vous pouvez utiliser le tri proc dans SAS pour supprimer rapidement les lignes en double d’un ensemble de données.
Cette procédure utilise la syntaxe de base suivante :
proc sort data=original_data out=no_dups_data nodupkey;
by _all_;
run;
Notez que l’argument by spécifie les colonnes à analyser lors de la suppression des doublons.
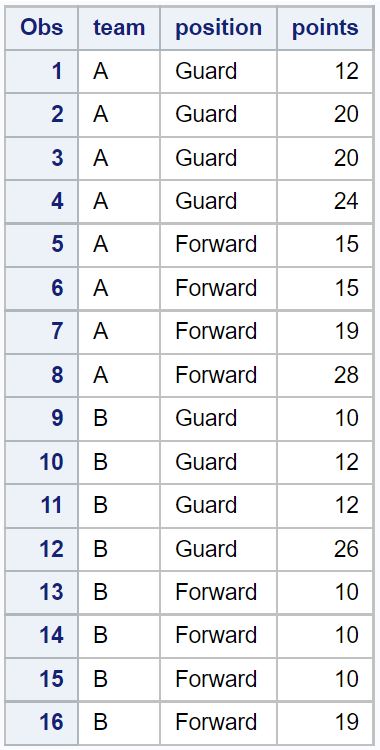
Les exemples suivants montrent comment supprimer les doublons de l’ensemble de données suivant dans SAS :
/*create dataset*/
data original_data;
input team $ position $ points;
datalines;
A Guard 12
A Guard 20
A Guard 20
A Guard 24
A Forward 15
A Forward 15
A Forward 19
A Forward 28
B Guard 10
B Guard 12
B Guard 12
B Guard 26
B Forward 10
B Forward 10
B Forward 10
B Forward 19
;
run;
/*view dataset*/
proc print data=original_data;
Exemple 1 : supprimer les doublons de toutes les colonnes
Nous pouvons utiliser le code suivant pour supprimer les lignes qui ont des valeurs en double dans toutes les colonnes de l’ensemble de données :
/*create dataset with no duplicate rows*/
proc sort data=original_data out=no_dups_data nodupkey;
by _all_;
run;
/*view dataset with no duplicate rows*/
proc print data=no_dups_data;
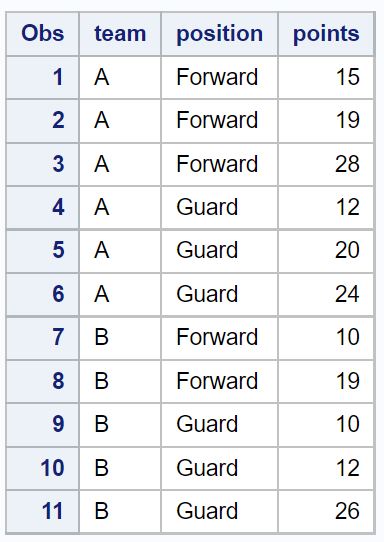
Notez qu’un total de cinq lignes en double ont été supprimées de l’ensemble de données d’origine.
Exemple 2 : supprimer les doublons de colonnes spécifiques
Nous pouvons utiliser l’argument by pour spécifier les colonnes à examiner lors de la suppression des doublons.
Par exemple, le code suivant supprime les lignes comportant des valeurs en double dans les colonnes d’équipe et de poste :
/*create dataset with no duplicate rows in team and position columns*/
proc sort data=original_data out=no_dups_data nodupkey;
by team position;
run;
/*view dataset with no duplicate rows in team and position columns*/
proc print data=no_dups_data;
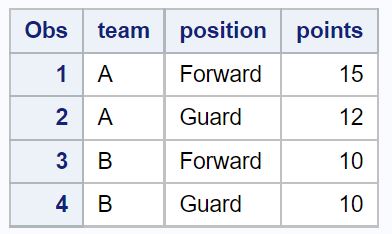
Seules quatre lignes restent dans l’ensemble de données après suppression des lignes comportant des valeurs en double dans les colonnes d’équipe et de position .
Ressources additionnelles
Les didacticiels suivants expliquent comment effectuer d’autres opérations courantes dans SAS :
Comment normaliser les données dans SAS
Comment identifier les valeurs aberrantes dans SAS
Comment utiliser le résumé de procédure dans SAS
Comment créer des tableaux de fréquences dans SAS
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus