
Une introduction simple à la stimulation de l’apprentissage automatique
La plupart des algorithmes d’apprentissage automatique supervisé sont basés sur l’utilisation d’un modèle prédictif unique comme la régression linéaire , la régression logistique , la régression de crête , etc.
Cependant, des méthodes telles que le bagging et les forêts aléatoires construisent de nombreux modèles différents basés sur des échantillons bootstrapés répétés de l’ensemble de données d’origine. Les prédictions sur les nouvelles données sont faites en prenant la moyenne des prédictions faites par les modèles individuels.
Ces méthodes ont tendance à offrir une amélioration de la précision des prédictions par rapport aux méthodes qui n’utilisent qu’un seul modèle prédictif, car elles utilisent le processus suivant :
- Tout d’abord, construisez des modèles individuels présentant une variance élevée et un faible biais (par exemple, des arbres de décision profondément développés).
- Ensuite, faites la moyenne des prédictions faites par les modèles individuels afin de réduire la variance.
Une autre méthode qui tend à offrir une amélioration encore plus grande de la précision prédictive est connue sous le nom de boosting .
Qu’est-ce que le Boosting ?
Le boosting est une méthode qui peut être utilisée avec tout type de modèle, mais elle est le plus souvent utilisée avec des arbres de décision.
L’idée derrière le boosting est simple :
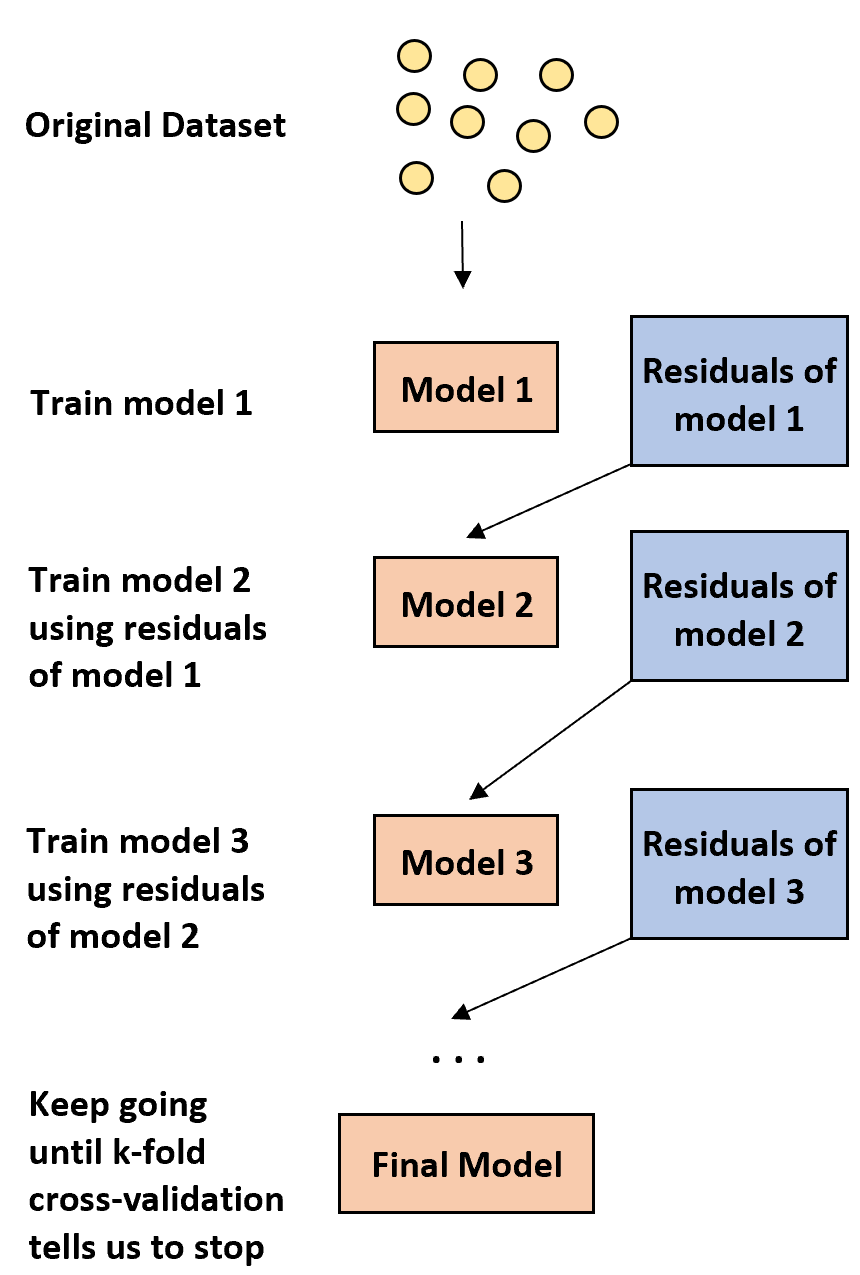
1. Tout d’abord, construisez un modèle faible.
- Un modèle « faible » est un modèle dont le taux d’erreur n’est que légèrement meilleur qu’une estimation aléatoire.
- En pratique, il s’agit généralement d’un arbre de décision comportant seulement une ou deux divisions.
2. Ensuite, construisez un autre modèle faible basé sur les résidus du modèle précédent.
- En pratique, nous utilisons les résidus du modèle précédent (c’est-à-dire les erreurs dans nos prédictions) pour ajuster un nouveau modèle qui améliore légèrement le taux d’erreur global.
3. Continuez ce processus jusqu’à ce que la validation croisée k-fold nous dise d’arrêter.
- En pratique, nous utilisons la validation croisée k fois pour identifier quand nous devrions arrêter de développer le modèle boosté.
En utilisant cette méthode, nous pouvons commencer avec un modèle faible et continuer à « améliorer » ses performances en construisant séquentiellement de nouveaux arbres qui améliorent les performances de l’arbre précédent jusqu’à ce que nous obtenions un modèle final doté d’une grande précision prédictive.
Pourquoi le boosting fonctionne-t-il ?
Il s’avère que le boosting est capable de produire certains des modèles les plus puissants de tout l’apprentissage automatique.
Dans de nombreux secteurs, les modèles boostés sont utilisés comme modèles de référence en production car ils ont tendance à surpasser tous les autres modèles.
La raison pour laquelle les modèles boostés fonctionnent si bien se résume à la compréhension d’une idée simple :
1. Premièrement, les modèles améliorés construisent un arbre de décision faible qui a une faible précision prédictive. On dit que cet arbre de décision a une faible variance et un biais élevé.
2. À mesure que les modèles améliorés suivent le processus d’amélioration séquentielle des arbres de décision précédents, le modèle global est capable de réduire lentement le biais à chaque étape sans augmenter considérablement la variance.
3. Le modèle ajusté final a tendance à avoir un biais et une variance suffisamment faibles, ce qui conduit à un modèle capable de produire de faibles taux d’erreur de test sur de nouvelles données.
Avantages et inconvénients du boosting
L’avantage évident du boosting est qu’il est capable de produire des modèles dotés d’une précision prédictive élevée par rapport à presque tous les autres types de modèles.
Un inconvénient potentiel est qu’un modèle amélioré ajusté est très difficile à interpréter. Bien qu’il puisse offrir une formidable capacité à prédire les valeurs de réponse de nouvelles données, il est difficile d’expliquer le processus exact qu’il utilise pour y parvenir.
En pratique, la plupart des data scientists et des praticiens du machine learning créent des modèles améliorés car ils souhaitent pouvoir prédire avec précision les valeurs de réponse des nouvelles données. Ainsi, le fait que les modèles améliorés soient difficiles à interpréter n’est généralement pas un problème.
Booster en pratique
Dans la pratique, il existe de nombreux types d’algorithmes utilisés pour le boosting, notamment :
En fonction de la taille de votre ensemble de données et de la puissance de traitement de votre machine, l’une de ces méthodes peut être préférable à l’autre.
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus