
Comment tester la normalité en Python (4 méthodes)
De nombreux tests statistiques supposent que les ensembles de données sont normalement distribués.
Il existe quatre manières courantes de vérifier cette hypothèse en Python :
1. (Méthode visuelle) Créez un histogramme.
- Si l’histogramme est à peu près en forme de « cloche », alors les données sont supposées être distribuées normalement.
2. (Méthode visuelle) Créez un tracé QQ.
- Si les points du tracé se situent à peu près le long d’une ligne diagonale droite, alors les données sont supposées être distribuées normalement.
3. (Test statistique formel) Effectuez un test Shapiro-Wilk.
- Si la valeur p du test est supérieure à α = 0,05, alors les données sont supposées être normalement distribuées.
4. (Test statistique formel) Effectuez un test de Kolmogorov-Smirnov.
- Si la valeur p du test est supérieure à α = 0,05, alors les données sont supposées être normalement distribuées.
Les exemples suivants montrent comment utiliser chacune de ces méthodes dans la pratique.
Méthode 1 : créer un histogramme
Le code suivant montre comment créer un histogramme pour un ensemble de données qui suit une distribution log-normale :
import math
import numpy as np
from scipy.stats import lognorm
import matplotlib.pyplot as plt
#make this example reproducible
np.random.seed(1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm.rvs(s=.5, scale=math.exp(1), size=1000)
#create histogram to visualize values in dataset
plt.hist(lognorm_dataset, edgecolor='black', bins=20)
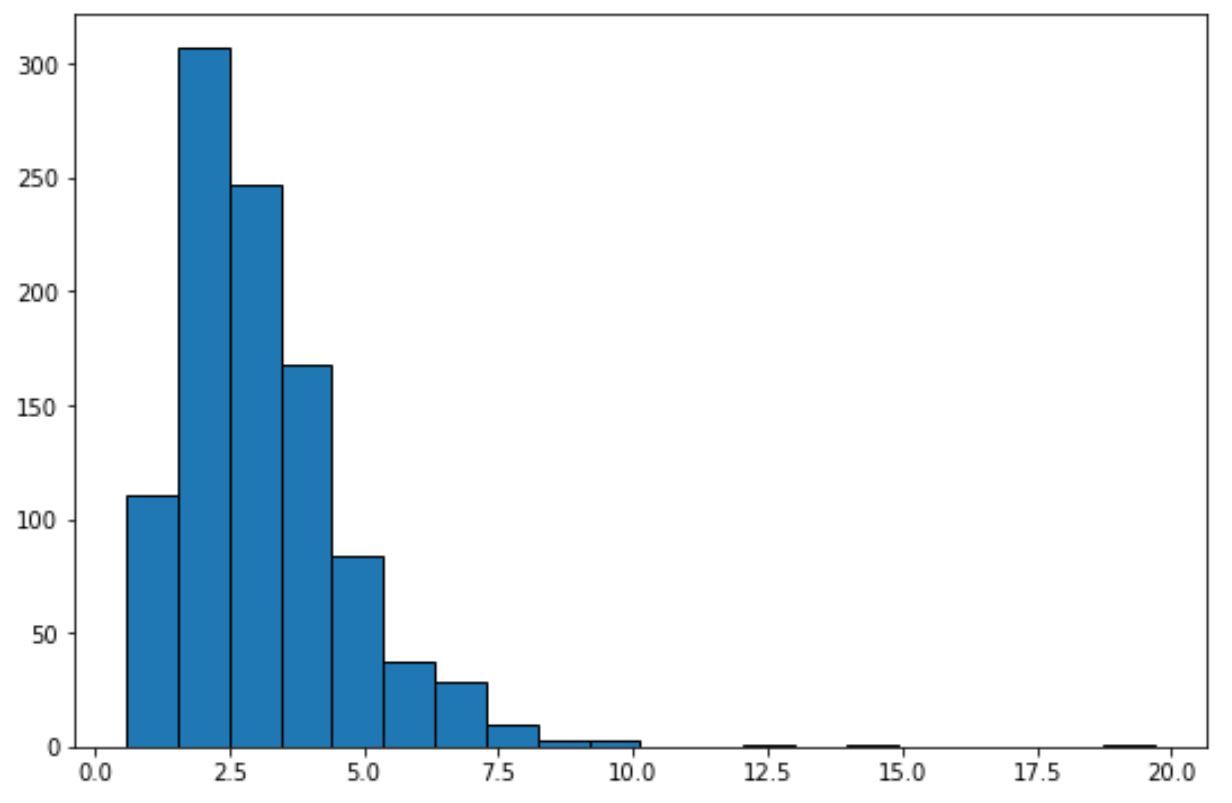
En regardant simplement cet histogramme, nous pouvons dire que l’ensemble de données ne présente pas de « forme de cloche » et n’est pas normalement distribué.
Méthode 2 : créer un tracé QQ
Le code suivant montre comment créer un tracé QQ pour un ensemble de données qui suit une distribution log-normale :
import math
import numpy as np
from scipy.stats import lognorm
import statsmodels.api as sm
import matplotlib.pyplot as plt
#make this example reproducible
np.random.seed(1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm.rvs(s=.5, scale=math.exp(1), size=1000)
#create Q-Q plot with 45-degree line added to plot
fig = sm.qqplot(lognorm_dataset, line='45')
plt.show()
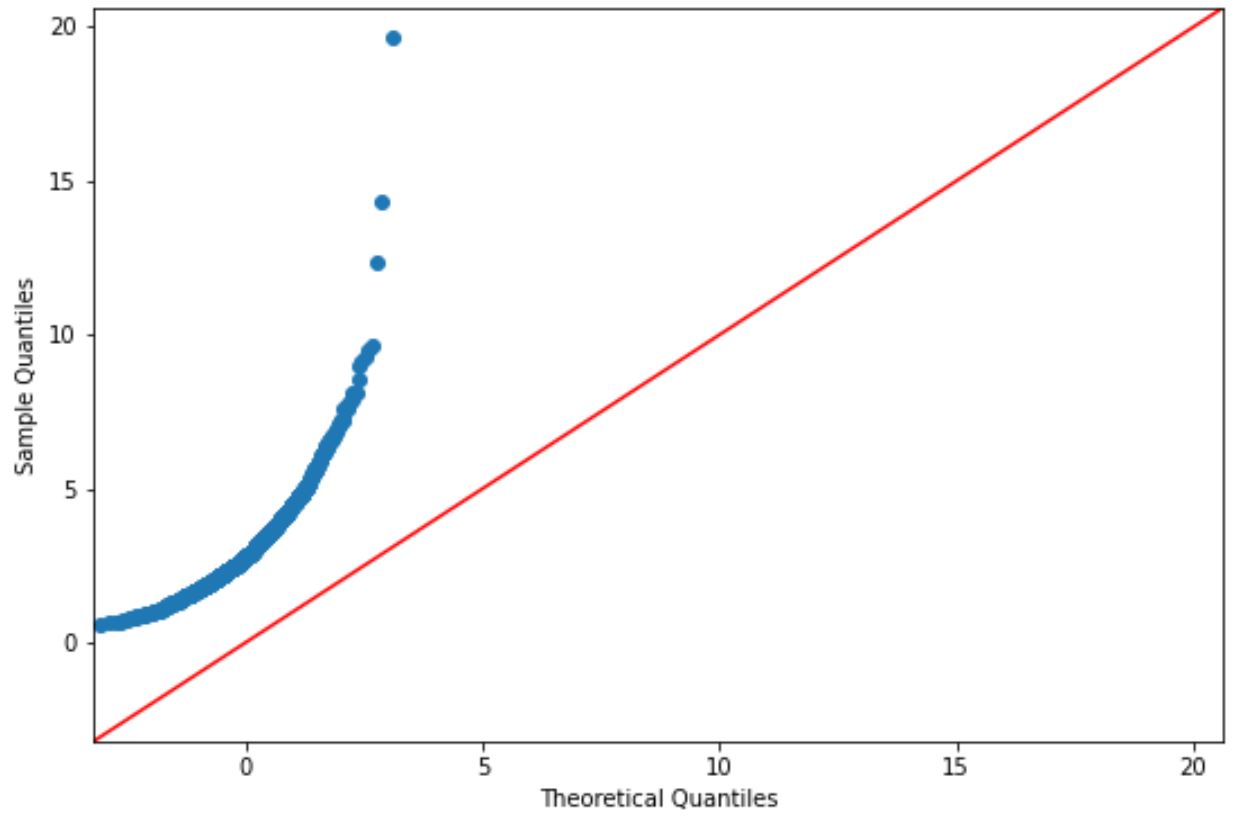
Si les points du tracé se situent à peu près le long d’une ligne diagonale droite, nous supposons généralement qu’un ensemble de données est normalement distribué.
Cependant, les points sur ce graphique ne correspondent clairement pas à la ligne rouge, nous ne pouvons donc pas supposer que cet ensemble de données est normalement distribué.
Cela devrait avoir du sens étant donné que nous avons généré les données à l’aide d’une fonction de distribution log-normale.
Méthode 3 : effectuer un test Shapiro-Wilk
Le code suivant montre comment effectuer un Shapiro-Wilk pour un ensemble de données qui suit une distribution log-normale :
import math
import numpy as np
from scipy.stats import shapiro
from scipy.stats import lognorm
#make this example reproducible
np.random.seed(1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm.rvs(s=.5, scale=math.exp(1), size=1000)
#perform Shapiro-Wilk test for normality
shapiro(lognorm_dataset)
ShapiroResult(statistic=0.8573324680328369, pvalue=3.880663073872444e-29)
À partir du résultat, nous pouvons voir que la statistique de test est de 0,857 et la valeur p correspondante est de 3,88e-29 (extrêmement proche de zéro).
Puisque la valeur p est inférieure à 0,05, nous rejetons l’hypothèse nulle du test de Shapiro-Wilk.
Cela signifie que nous disposons de suffisamment de preuves pour affirmer que les données de l’échantillon ne proviennent pas d’une distribution normale.
Méthode 4 : effectuer un test de Kolmogorov-Smirnov
Le code suivant montre comment effectuer un test de Kolmogorov-Smirnov pour un ensemble de données qui suit une distribution log-normale :
import math
import numpy as np
from scipy.stats import kstest
from scipy.stats import lognorm
#make this example reproducible
np.random.seed(1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm.rvs(s=.5, scale=math.exp(1), size=1000)
#perform Kolmogorov-Smirnov test for normality
kstest(lognorm_dataset, 'norm')
KstestResult(statistic=0.84125708308077, pvalue=0.0)
À partir du résultat, nous pouvons voir que la statistique de test est de 0,841 et que la valeur p correspondante est de 0,0 .
Puisque la valeur p est inférieure à 0,05, nous rejetons l’hypothèse nulle du test de Kolmogorov-Smirnov.
Cela signifie que nous disposons de suffisamment de preuves pour affirmer que les données de l’échantillon ne proviennent pas d’une distribution normale.
Comment gérer les données non normales
Si un ensemble de données donné n’est pas normalement distribué, nous pouvons souvent effectuer l’une des transformations suivantes pour le rendre plus normalement distribué :
1. Transformation du journal : transformez les valeurs de x en log(x) .
2. Transformation racine carrée : Transformez les valeurs de x en √ x .
3. Transformation de racine cubique : transformez les valeurs de x en x 1/3 .
En effectuant ces transformations, l’ensemble de données devient généralement distribué plus normalement.
Lisez ce tutoriel pour voir comment effectuer ces transformations en Python.
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus