วิธีการปรับขนาดหลายมิติใน python
ในสถิติ มาตราส่วนหลายมิติ เป็นวิธีหนึ่งในการแสดงภาพความคล้ายคลึงของการสังเกตในชุดข้อมูลในปริภูมิคาร์ทีเซียนเชิงนามธรรม (โดยปกติจะเป็นปริภูมิ 2 มิติ)
วิธีที่ง่ายที่สุดในการปรับขนาดหลายมิติใน Python คือการใช้ฟังก์ชัน MDS() ของโมดูลย่อย sklearn.manifold
ตัวอย่างต่อไปนี้แสดงวิธีใช้ฟังก์ชันนี้ในทางปฏิบัติ
ตัวอย่าง: มาตราส่วนหลายมิติใน Python
สมมติว่าเรามี DataFrame แพนด้าต่อไปนี้ซึ่งมีข้อมูลเกี่ยวกับผู้เล่นบาสเกตบอลต่างๆ:
import pandas as pd #create DataFrane df = pd. DataFrame ({' player ': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K '], ' points ': [4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28], ' assists ': [3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11], ' blocks ': [7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1], ' rebounds ': [4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2]}) #set player column as index column df = df. set_index (' player ') #view Dataframe print (df) points assists blocks rebounds player A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
เราสามารถใช้โค้ดต่อไปนี้เพื่อดำเนินการปรับขนาดหลายมิติด้วยฟังก์ชัน MDS() ของโมดูล sklearn.manifold :
from sklearn. manifold import MDS
#perform multi-dimensional scaling
mds = MDS(random_state= 0 )
scaled_df = mds. fit_transform (df)
#view results of multi-dimensional scaling
print (scaled_df)
[[ 7.43654469 8.10247222]
[4.13193821 10.27360901]
[5.20534681 7.46919526]
[6.22323046 4.45148627]
[3.74110999 5.25591459]
[3.69073384 -2.88017811]
[3.89092087 -5.19100988]
[ -3.68593169 -3.0821144 ]
[ -9.13631889 -6.81016012]
[ -8.97898385 -8.50414387]
[-12.51859044 -9.08507097]]
แต่ละแถวของ DataFrame ดั้งเดิมถูกลดขนาดให้เป็นพิกัด (x, y)
เราสามารถใช้โค้ดต่อไปนี้เพื่อแสดงภาพพิกัดเหล่านี้ในพื้นที่ 2D:
import matplotlib.pyplot as plt #create scatterplot plt. scatter (scaled_df[:,0], scaled_df[:,1]) #add axis labels plt. xlabel (' Coordinate 1 ') plt. ylabel (' Coordinate 2 ') #add lables to each point for i, txt in enumerate( df.index ): plt. annotate (txt, (scaled_df[:,0][i]+.3, scaled_df[:,1][i])) #display scatterplot plt. show ()
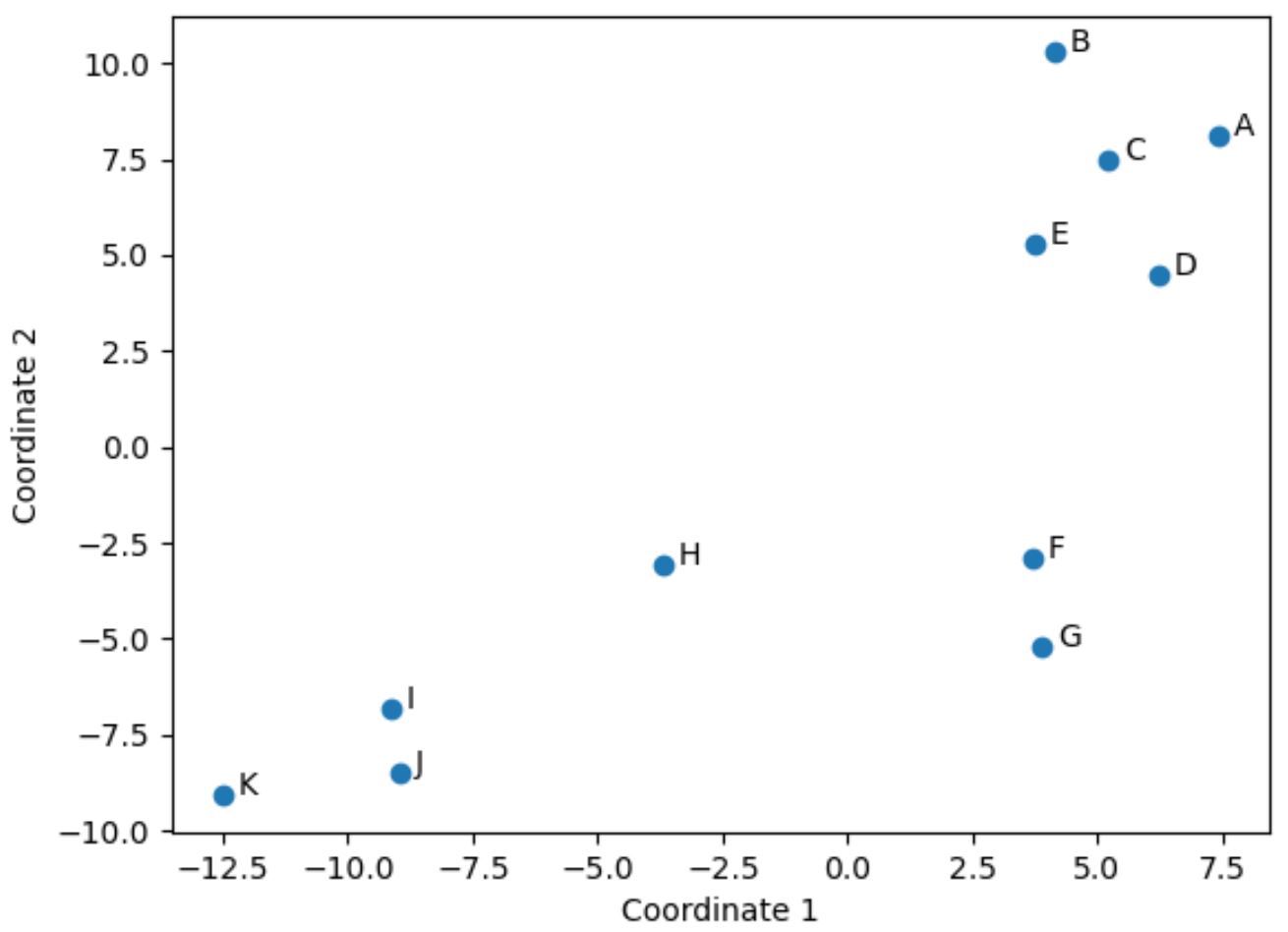
ผู้เล่นใน DataFrame ดั้งเดิมที่มีค่าใกล้เคียงกันในสี่คอลัมน์ดั้งเดิม (คะแนน, แอสซิสต์, บล็อกและรีบาวด์) จะอยู่ใกล้กันในโครงเรื่อง
ตัวอย่างเช่น ผู้เล่น F และ G อยู่ใกล้กัน นี่คือค่าของพวกเขาจาก DataFrame ดั้งเดิม:
#select rows with index labels 'F' and 'G'
df. loc [[' F ',' G ']]
points assists blocks rebounds
player
F 14 8 8 8
G 16 7 8 10
ค่าแต้ม แอสซิสต์ บล็อก และรีบาวด์ของพวกมันค่อนข้างคล้ายกัน ซึ่งอธิบายได้ว่าทำไมพวกมันถึงอยู่ใกล้กันมากในพล็อต 2 มิติ
ในทางตรงกันข้าม ลองพิจารณาผู้เล่น B และ K ที่อยู่ห่างไกลกันในโครงเรื่อง
หากเราอ้างถึงค่าของมันใน DataFrame ดั้งเดิม เราจะเห็นว่ามันแตกต่างกันมาก:
#select rows with index labels 'B' and 'K'
df. loc [[' B ',' K ']]
points assists blocks rebounds
player
B 4 2 3 5
K 28 11 1 2
ดังนั้น พล็อตแบบ 2 มิติจึงเป็นวิธีที่ดีในการแสดงให้เห็นว่าผู้เล่นแต่ละคนมีความคล้ายคลึงกันอย่างไรในตัวแปรทั้งหมดใน DataFframe
ผู้เล่นที่มีสถิติใกล้เคียงกันจะถูกจัดกลุ่มไว้ใกล้กัน ในขณะที่ผู้เล่นที่มีสถิติต่างกันมากจะอยู่ห่างจากกันในเนื้อเรื่อง
แหล่งข้อมูลเพิ่มเติม
บทช่วยสอนต่อไปนี้จะอธิบายวิธีทำงานทั่วไปอื่นๆ ใน Python:
วิธีทำให้ข้อมูลเป็นมาตรฐานใน Python
วิธีลบค่าผิดปกติใน Python
วิธีทดสอบความเป็นปกติใน Python
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม