ทำความเข้าใจกับข้อผิดพลาดมาตรฐานของความชันการถดถอย
ข้อผิดพลาดมาตรฐานของความชันของการถดถอย เป็นวิธีหนึ่งในการวัด “ความไม่แน่นอน” ในการประมาณค่าความชันของการถดถอย
มีการคำนวณดังนี้:
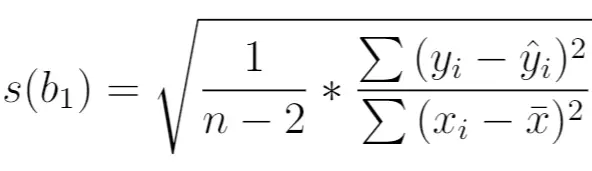
ทอง:
- n : ขนาดตัวอย่างทั้งหมด
- y i : ค่าที่แท้จริงของตัวแปรตอบสนอง
- ŷ i : ค่าที่ทำนายของตัวแปรตอบสนอง
- x i : ค่าที่แท้จริงของตัวแปรทำนาย
- x̄ : ค่าเฉลี่ยของตัวแปรทำนาย
ยิ่งข้อผิดพลาดมาตรฐานมีค่าน้อยลง ความแปรปรวนรอบค่าสัมประสิทธิ์การประมาณค่าความชันของการถดถอยก็จะยิ่งน้อยลง
ข้อผิดพลาดมาตรฐานของความชันการถดถอยจะแสดงในคอลัมน์ “ข้อผิดพลาดมาตรฐาน” ในเอาต์พุตการถดถอยของซอฟต์แวร์ทางสถิติส่วนใหญ่:
ตัวอย่างต่อไปนี้แสดงวิธีตีความข้อผิดพลาดมาตรฐานของความชันการถดถอยในสองสถานการณ์ที่แตกต่างกัน
ตัวอย่างที่ 1: การตีความข้อผิดพลาดมาตรฐานเล็กน้อยของความชันการถดถอย
สมมติว่าอาจารย์ต้องการเข้าใจความสัมพันธ์ระหว่างจำนวนชั่วโมงเรียนกับคะแนนสอบปลายภาคของนักเรียนในชั้นเรียน
รวบรวมข้อมูลสำหรับนักเรียน 25 คนและสร้างแผนภาพกระจายต่อไปนี้:
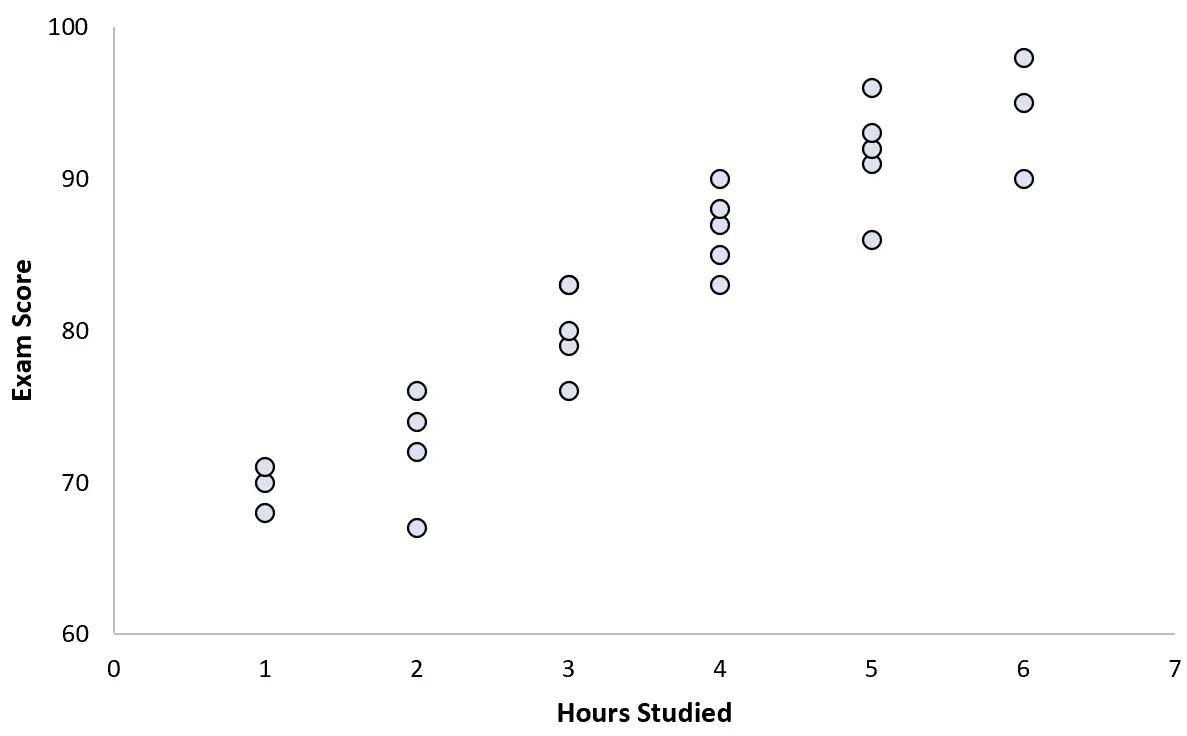
มีความสัมพันธ์เชิงบวกอย่างชัดเจนระหว่างตัวแปรทั้งสอง เมื่อจำนวนชั่วโมงที่เรียนเพิ่มขึ้น คะแนนการสอบก็จะเพิ่มขึ้นในอัตราที่สามารถคาดเดาได้พอสมควร
จากนั้นเขาก็ใส่แบบจำลองการถดถอยเชิงเส้นอย่างง่ายโดยใช้ชั่วโมงที่ศึกษาเป็นตัวแปรทำนายและเกรดการสอบปลายภาคเป็นตัวแปรตอบสนอง
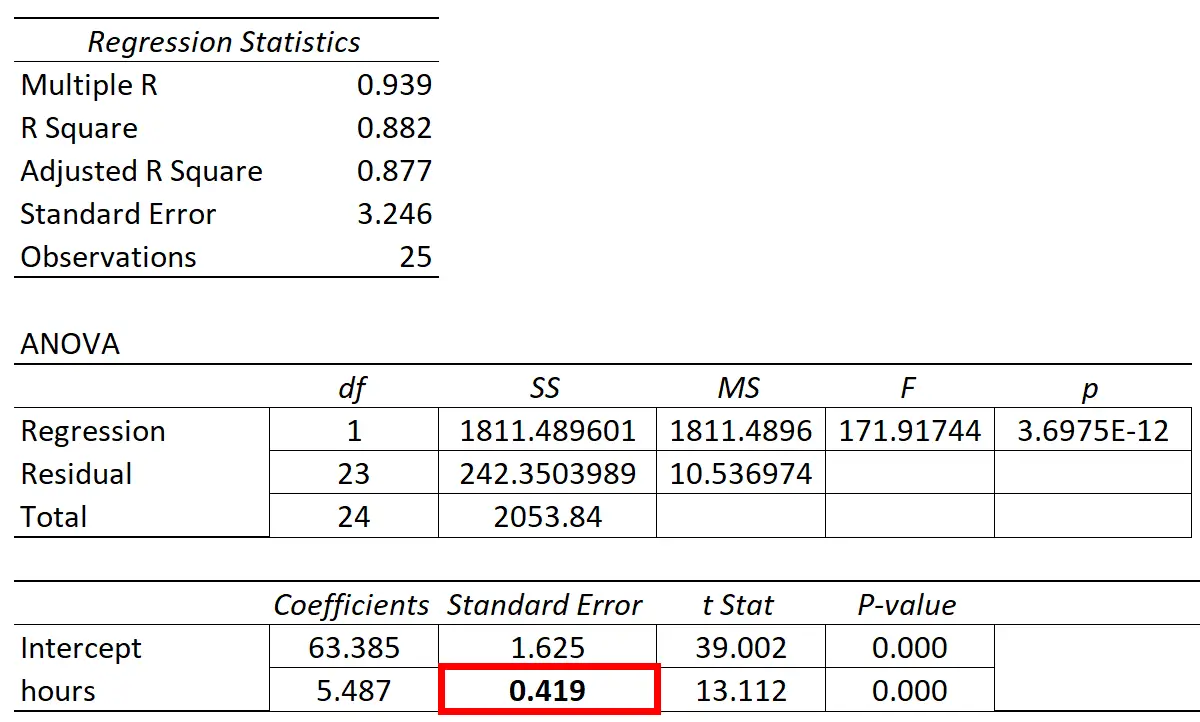
ตารางต่อไปนี้แสดงผลการถดถอย:
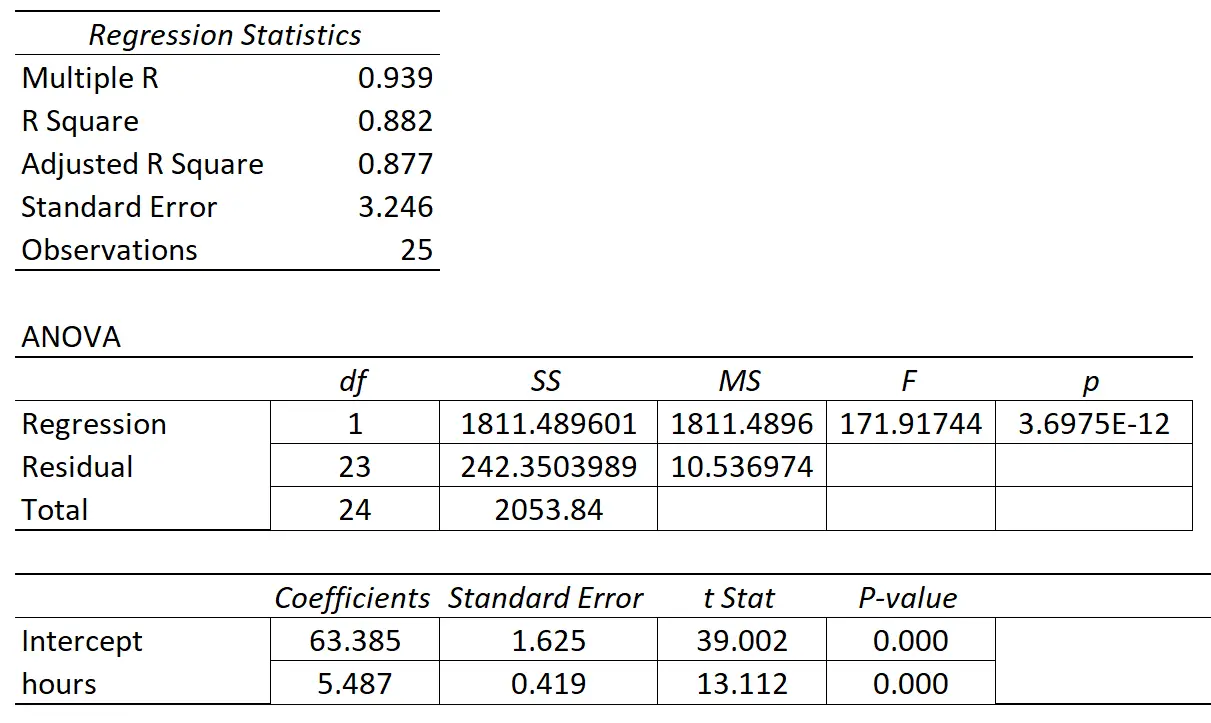
ค่าสัมประสิทธิ์ของตัวแปรทำนาย “ชั่วโมงการศึกษา” คือ 5.487 สิ่งนี้บอกเราว่าแต่ละชั่วโมงที่เรียนเพิ่มเติมนั้นสัมพันธ์กับคะแนนสอบที่เพิ่มขึ้นโดยเฉลี่ย 5,487
ข้อผิดพลาดมาตรฐานคือ 0.419 ซึ่งแสดงถึงการวัดความแปรปรวนรอบค่าประมาณนี้สำหรับความชันของการถดถอย
เราสามารถใช้ค่านี้เพื่อคำนวณสถิติ t สำหรับตัวแปรทำนาย “ชั่วโมงที่ศึกษา”:
- t สถิติ = การประมาณค่าสัมประสิทธิ์ / ความคลาดเคลื่อนมาตรฐาน
- สถิติ t = 5.487 / 0.419
- สถิติ t = 13.112
ค่า p ที่สอดคล้องกับสถิติการทดสอบนี้คือ 0.000 ซึ่งบ่งชี้ว่า “ชั่วโมงที่เรียน” มีความสัมพันธ์ที่มีนัยสำคัญทางสถิติกับคะแนนสอบปลายภาค
เนื่องจากข้อผิดพลาดมาตรฐานของความชันการถดถอยมีขนาดเล็กเมื่อเทียบกับการประมาณค่าสัมประสิทธิ์ของความชันการถดถอย ตัวแปรตัวทำนายจึงมีนัยสำคัญทางสถิติ
ตัวอย่างที่ 2: การตีความข้อผิดพลาดมาตรฐานขนาดใหญ่ของความชันการถดถอย
สมมติว่าศาสตราจารย์อีกคนต้องการเข้าใจความสัมพันธ์ระหว่างจำนวนชั่วโมงเรียนกับคะแนนสอบปลายภาคของนักเรียนในชั้นเรียนของเขา
เธอรวบรวมข้อมูลสำหรับนักเรียน 25 คน และสร้างแผนภาพกระจายต่อไปนี้:
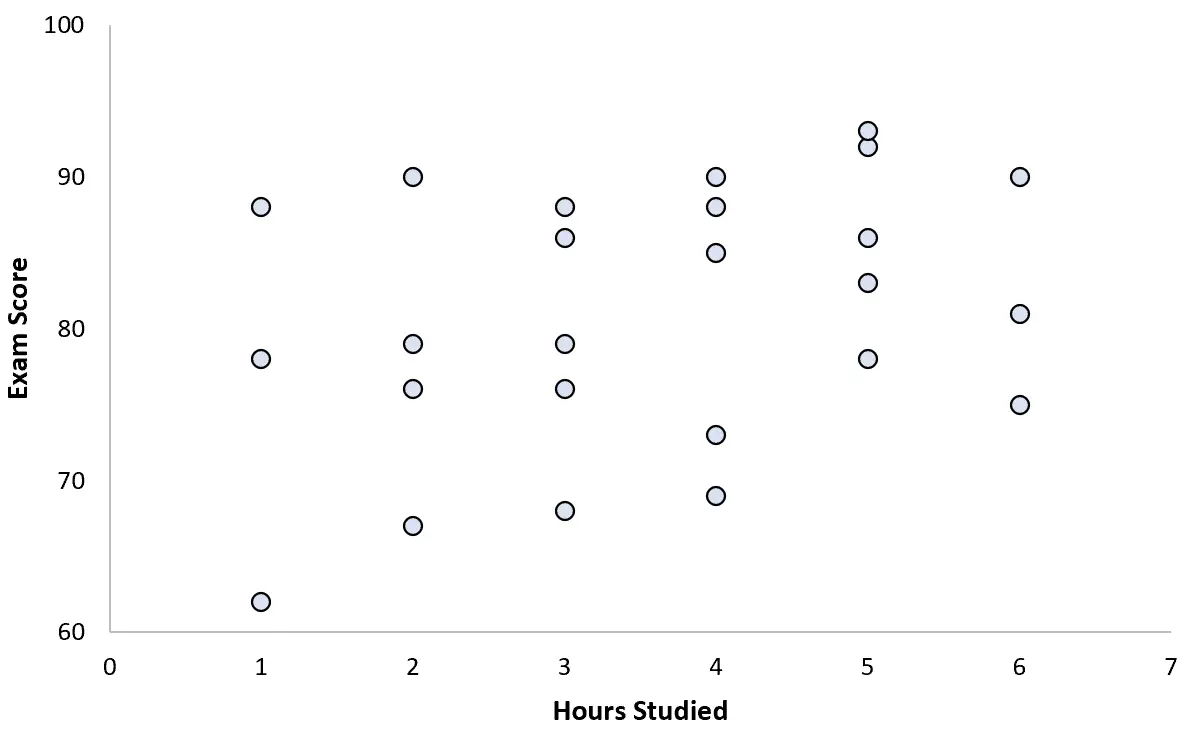
ดูเหมือนจะมีความสัมพันธ์เชิงบวกเล็กน้อยระหว่างตัวแปรทั้งสอง เมื่อจำนวนชั่วโมงเรียนเพิ่มขึ้น โดยทั่วไปคะแนนสอบจะเพิ่มขึ้น แต่ไม่ใช่ในอัตราที่คาดเดาได้
สมมติว่าศาสตราจารย์เหมาะกับแบบจำลองการถดถอยเชิงเส้นอย่างง่ายโดยใช้ชั่วโมงที่ศึกษาเป็นตัวแปรทำนายและเกรดการสอบปลายภาคเป็นตัวแปรตอบสนอง
ตารางต่อไปนี้แสดงผลการถดถอย:
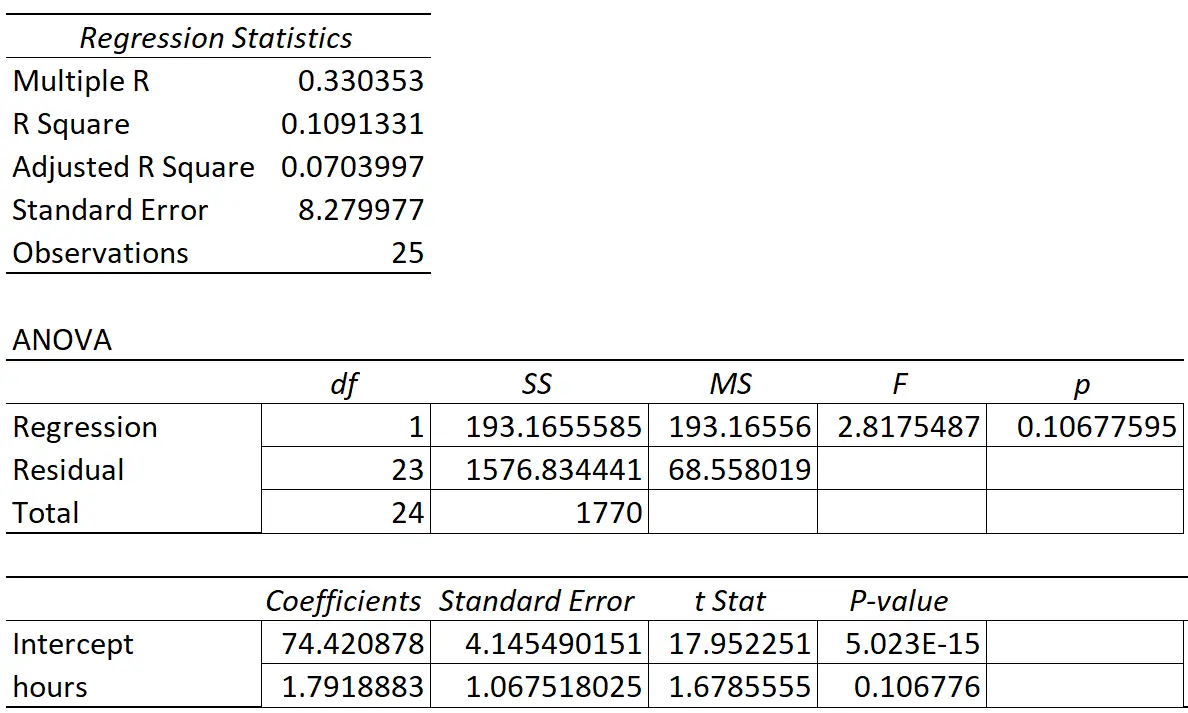
ค่าสัมประสิทธิ์ของตัวแปรทำนาย “ชั่วโมงการศึกษา” คือ 1.7919 สิ่งนี้บอกเราว่าแต่ละชั่วโมงที่เรียนเพิ่มเติมนั้นสัมพันธ์กับคะแนนสอบที่เพิ่มขึ้นโดยเฉลี่ย 1.7919
ข้อผิดพลาดมาตรฐานคือ 1.0675 ซึ่งเป็นการวัดความแปรปรวนรอบค่าประมาณนี้สำหรับความชันของการถดถอย
เราสามารถใช้ค่านี้เพื่อคำนวณสถิติ t สำหรับตัวแปรทำนาย “ชั่วโมงที่ศึกษา”:
- t สถิติ = การประมาณค่าสัมประสิทธิ์ / ความคลาดเคลื่อนมาตรฐาน
- สถิติ t = 1.7919 / 1.0675
- สถิติ t = 1.678
ค่า p ที่สอดคล้องกับสถิติการทดสอบนี้คือ 0.107 เนื่องจากค่า p นี้ไม่น้อยกว่า 0.05 แสดงว่า “ชั่วโมงที่เรียน” ไม่มีความสัมพันธ์ที่มีนัยสำคัญทางสถิติกับคะแนนสอบปลายภาค
เนื่องจากข้อผิดพลาดมาตรฐานของความชันการถดถอยมีมากเมื่อเทียบกับการประมาณค่าสัมประสิทธิ์ของความชันการถดถอย ตัวแปรทำนาย จึงไม่มี นัยสำคัญทางสถิติ
แหล่งข้อมูลเพิ่มเติม
รู้เบื้องต้นเกี่ยวกับการถดถอยเชิงเส้นอย่างง่าย
รู้เบื้องต้นเกี่ยวกับการถดถอยเชิงเส้นพหุคูณ
วิธีอ่านและตีความตารางการถดถอย
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม