อะไรที่เรียกว่า “ดี”? คะแนน f1?
เมื่อใช้ แบบจำลองการจัดหมวดหมู่ ในการเรียนรู้ของเครื่อง ตัวชี้วัดทั่วไปที่เราใช้ในการประเมินคุณภาพของแบบจำลองคือ คะแนน F1
เมตริกนี้คำนวณดังนี้:
คะแนน F1 = 2 * (ความแม่นยำ * การเรียกคืน) / (ความแม่นยำ + การเรียกคืน)
ทอง:
- ความแม่นยำ : แก้ไขการคาดการณ์เชิงบวกโดยสัมพันธ์กับการคาดการณ์เชิงบวกทั้งหมด
- คำเตือน : การแก้ไขการคาดการณ์เชิงบวกเทียบกับผลบวกจริงทั้งหมด
ตัวอย่างเช่น สมมติว่าเราใช้แบบจำลองการถดถอยลอจิสติกส์เพื่อคาดการณ์ว่าผู้เล่นบาสเกตบอลระดับวิทยาลัยกว่า 400 คนจะถูกคัดเลือกเข้าสู่ NBA หรือไม่
เมทริกซ์ความสับสนต่อไปนี้สรุปการคาดการณ์ที่ทำโดยแบบจำลอง:

ต่อไปนี้เป็นวิธีคำนวณคะแนน F1 ของโมเดล:
ความแม่นยำ = ผลบวกจริง / (ผลบวกจริง + ผลบวกลวง) = 120/ (120+70) = 0.63157
การเรียกคืน = True Positive / (True Positive + False Negative) = 120 / (120+40) = 0.75
คะแนน F1 = 2 * (.63157 * .75) / (.63157 + .75) = . 6857
คะแนน F1 ที่ดีคืออะไร?
คำถามที่นักเรียนมักถามคือ:
คะแนนที่ดีใน F1 คืออะไร?
พูดง่ายๆ ก็คือ โดยทั่วไปแล้วคะแนน F1 ที่สูงกว่าจะดีกว่า
โปรดจำไว้ว่าคะแนน F1 สามารถอยู่ในช่วงตั้งแต่ 0 ถึง 1 โดย 1 แสดงถึงแบบจำลองที่จำแนกการสังเกตแต่ละครั้งได้อย่างสมบูรณ์แบบเป็นระดับที่ถูกต้อง และ 0 แสดงถึงแบบจำลองที่ไม่สามารถจำแนกการสังเกตเป็นระดับที่ถูกต้องได้
เพื่ออธิบายสิ่งนี้ สมมติว่าเรามีแบบจำลองการถดถอยลอจิสติกที่สร้างเมทริกซ์ความสับสนต่อไปนี้:
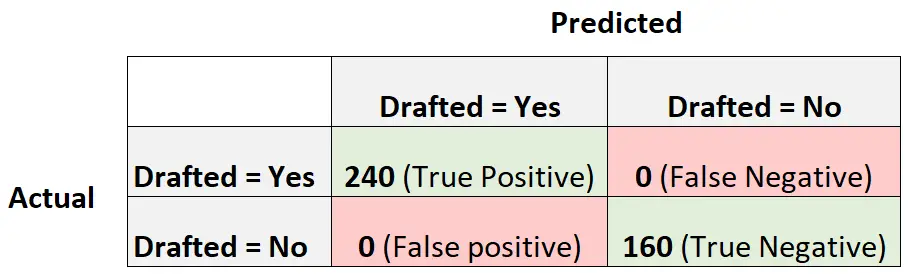
ต่อไปนี้เป็นวิธีคำนวณคะแนน F1 ของโมเดล:
ความแม่นยำ = บวกจริง / (บวกจริง + บวกเท็จ) = 240/ (240+0) = 1
การเรียกคืน = True Positive / (True Positive + False Negative) = 240 / (240+0) = 1
คะแนน F1 = 2 * (1 * 1) / (1 + 1) = 1
คะแนน F1 เท่ากับ 1 คะแนน เนื่องจากสามารถจำแนกการสังเกตการณ์ 400 รายการออกเป็นชั้นเรียนได้อย่างสมบูรณ์แบบ
ตอนนี้ ให้พิจารณาแบบจำลองการถดถอยโลจิสติกอีกแบบหนึ่งที่เพียงคาดการณ์ว่าผู้เล่นแต่ละคนจะถูกร่าง:
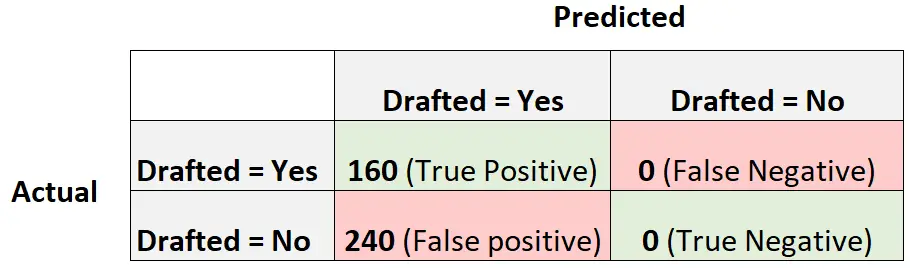
ต่อไปนี้เป็นวิธีคำนวณคะแนน F1 ของโมเดล:
ความแม่นยำ = ผลบวกจริง / (ผลบวกจริง + ผลบวกลวง) = 160/ (160+240) = 0.4
การเรียกคืน = True Positive / (True Positive + False Negative) = 160 / (160+0) = 1
คะแนน F1 = 2 * (.4 * 1) / (.4 + 1) = 0.5714
นี่จะถือเป็น แบบจำลองพื้นฐาน ที่เราสามารถเปรียบเทียบแบบจำลองการถดถอยโลจิสติกของเราได้ เนื่องจากเป็นแบบจำลองที่ทำการทำนายแบบเดียวกันสำหรับทุกการสังเกตในชุดข้อมูล
ยิ่งคะแนน F1 ของเราสูงเมื่อเปรียบเทียบกับโมเดลอ้างอิง แบบจำลองของเราก็จะยิ่งมีประโยชน์มากขึ้นเท่านั้น
จำได้ว่าก่อนหน้านี้แบบจำลองของเรามีคะแนน F1 เท่ากับ 0.6857 ซึ่งไม่สูงกว่า 0.5714 มากนัก ซึ่งบ่งชี้ว่าโมเดลของเรามีประโยชน์มากกว่าโมเดลพื้นฐาน แต่ก็ไม่มากนัก
ในการเปรียบเทียบคะแนน F1
ในทางปฏิบัติ เรามักจะใช้กระบวนการต่อไปนี้เพื่อเลือกแบบจำลองที่ “ดีที่สุด” สำหรับปัญหาการจำแนกประเภท:
ขั้นตอนที่ 1: ติดตั้งโมเดลอ้างอิงที่ทำการทำนายแบบเดียวกันสำหรับการสังเกตแต่ละครั้ง
ขั้นตอนที่ 2: จัดโมเดลการจัดหมวดหมู่ต่างๆ ให้เหมาะสม และคำนวณคะแนน F1 สำหรับแต่ละรุ่น
ขั้นตอนที่ 3: เลือกโมเดลที่มีคะแนน F1 สูงสุดเป็นโมเดลที่ “ดีที่สุด” เพื่อตรวจสอบว่าโมเดลนั้นสร้างคะแนน F1 ที่สูงกว่าโมเดลอ้างอิง
ไม่มีค่าใดเจาะจงที่ถือเป็นคะแนน F1 ที่ “ดี” ดังนั้นโดยทั่วไปเราจึงเลือกรูปแบบการจัดหมวดหมู่ที่สร้างคะแนน F1 สูงสุด
แหล่งข้อมูลเพิ่มเติม
คะแนน F1 เทียบกับความแม่นยำ: คุณควรใช้อันไหน
วิธีการคำนวณคะแนน F1 ใน R
วิธีคำนวณคะแนน F1 ใน Python
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม