วิธีการตีความค่าบันทึกความน่าจะเป็น (พร้อมตัวอย่าง)
ค่าความน่าจะเป็นของบันทึก ของแบบจำลองการถดถอยเป็นวิธีหนึ่งในการวัดความดีของแบบจำลอง ยิ่งค่าความเป็นไปได้ของบันทึกสูง โมเดลก็จะเหมาะกับชุดข้อมูลมากขึ้นเท่านั้น
ค่าของความน่าจะเป็นของบันทึกสำหรับแบบจำลองที่กำหนดอาจมีตั้งแต่ค่าอนันต์ลบไปจนถึงค่าอนันต์บวก โดยทั่วไปค่าความน่าจะเป็นของบันทึกจริงสำหรับโมเดลหนึ่งๆ จะไม่มีความหมาย แต่ มีประโยชน์สำหรับการเปรียบเทียบโมเดลตั้งแต่สองโมเดลขึ้นไป
ในทางปฏิบัติ เรามักจะใส่โมเดลการถดถอยหลายตัวเข้ากับชุดข้อมูลและเลือกโมเดลที่มีค่าโอกาสบันทึกสูงสุดเป็นโมเดลที่เหมาะกับข้อมูลมากที่สุด
ตัวอย่างต่อไปนี้แสดงวิธีการตีความค่าความน่าจะเป็นของบันทึกสำหรับแบบจำลองการถดถอยที่แตกต่างกันในทางปฏิบัติ
ตัวอย่าง: การตีความค่าความน่าจะเป็นของบันทึก
สมมติว่าเรามีชุดข้อมูลต่อไปนี้ซึ่งแสดงจำนวนห้องนอน จำนวนห้องน้ำ และราคาขายของบ้านที่แตกต่างกัน 20 หลังในละแวกใกล้เคียงหนึ่งๆ:
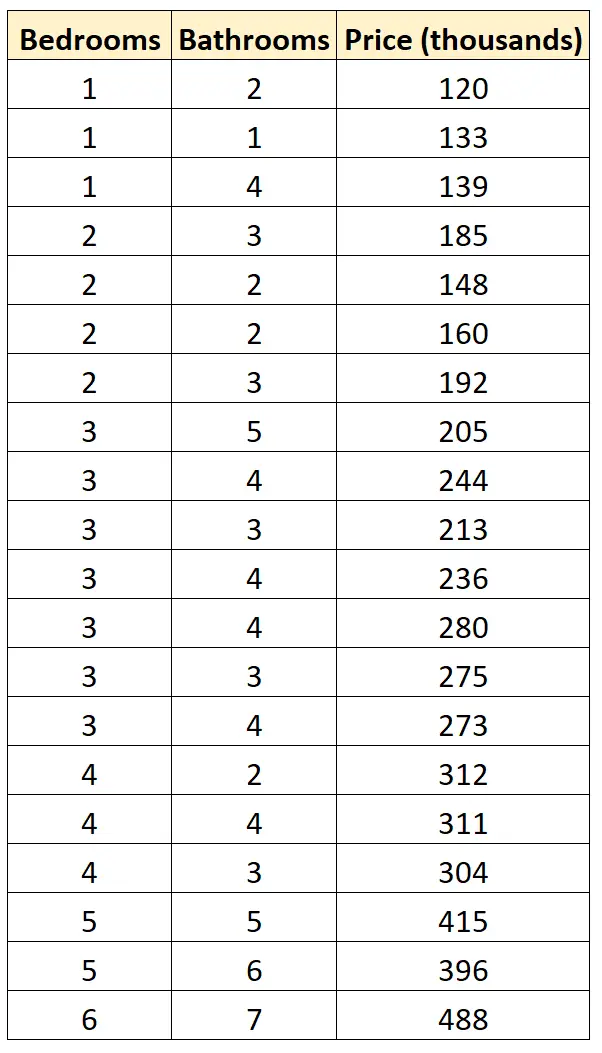
สมมติว่าเราต้องการปรับโมเดลการถดถอยสองแบบต่อไปนี้ให้เหมาะสม และพิจารณาว่าแบบใดที่เหมาะกับข้อมูลมากที่สุด:
แบบที่ 1 : ราคา = β 0 + β 1 (จำนวนห้อง)
แบบที่ 2 : ราคา = β 0 + β 1 (จำนวนห้องน้ำ)
รหัสต่อไปนี้แสดงวิธีปรับให้พอดีกับโมเดลการถดถอยแต่ละแบบ และคำนวณค่าความน่าจะเป็นของบันทึกของแต่ละโมเดลใน R:
#define data df <- data. frame (beds=c(1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 4, 4, 4, 5, 5, 6), baths=c(2, 1, 4, 3, 2, 2, 3, 5, 4, 3, 4, 4, 3, 4, 2, 4, 3, 5, 6, 7), price=c(120, 133, 139, 185, 148, 160, 192, 205, 244, 213, 236, 280, 275, 273, 312, 311, 304, 415, 396, 488)) #fitmodels model1 <- lm(price~beds, data=df) model2 <- lm(price~baths, data=df) #calculate log-likelihood value of each model logLik(model1) 'log Lik.' -91.04219 (df=3) logLik(model2) 'log Lik.' -111.7511 (df=3)
แบบจำลองแรกมีค่าความเป็นไปได้ของการบันทึกที่สูงกว่า ( -91.04 ) มากกว่าแบบจำลองที่สอง ( -111.75 ) ซึ่งหมายความว่าแบบจำลองแรกมีความเหมาะสมกับข้อมูลมากกว่า
ข้อควรระวังในการใช้ค่าความน่าจะเป็นของบันทึก
เมื่อคำนวณค่าความน่าจะเป็นของบันทึก สิ่งสำคัญคือต้องทราบว่าการเพิ่มตัวแปรตัวทำนายเพิ่มเติมให้กับแบบจำลองจะเพิ่มค่าความน่าจะเป็นของบันทึกเกือบทุกครั้ง แม้ว่าตัวแปรตัวทำนายเพิ่มเติมจะไม่มีนัยสำคัญทางสถิติก็ตาม
ซึ่งหมายความว่าคุณควรเปรียบเทียบค่าความน่าจะเป็นของบันทึกระหว่างแบบจำลองการถดถอยสองแบบเท่านั้น หากแต่ละแบบจำลองมีจำนวนตัวแปรทำนายเท่ากัน
หากต้องการเปรียบเทียบแบบจำลองที่มีตัวแปรทำนายจำนวนต่างกัน คุณสามารถทำการ ทดสอบอัตราส่วนความน่าจะเป็น เพื่อเปรียบเทียบความดีของความพอดีของแบบจำลองการถดถอยที่ซ้อนกันสองตัว
แหล่งข้อมูลเพิ่มเติม
วิธีใช้ฟังก์ชัน lm() เพื่อให้พอดีกับโมเดลเชิงเส้นใน R
วิธีการทดสอบอัตราส่วนความน่าจะเป็นใน R
เกี่ยวกับผู้แต่ง
ดร.เบนจามิน แอนเดอร์สัน
สวัสดี ฉันชื่อเบนจามิน ศาสตราจารย์สถิติเกษียณอายุแล้ว และผันตัวมาเป็นครูสอนสถิติโดยเฉพาะ ด้วยประสบการณ์และความเชี่ยวชาญที่กว้างขวางในสาขาสถิติ ฉันกระตือรือร้นที่จะแบ่งปันความรู้ของฉันเพื่อเสริมศักยภาพนักเรียนผ่าน Statorials. รู้เพิ่มเติม