
Comment obtenir des valeurs prédites et des résidus dans Stata
La régression linéaire est une méthode que nous pouvons utiliser pour comprendre la relation entre une ou plusieurs variables explicatives et une variable de réponse.
Lorsque nous effectuons une régression linéaire sur un ensemble de données, nous nous retrouvons avec une équation de régression qui peut être utilisée pour prédire les valeurs d’une variable de réponse, compte tenu des valeurs des variables explicatives.
Nous pouvons ensuite mesurer la différence entre les valeurs prédites et les valeurs réelles pour obtenir les résidus pour chaque prédiction. Cela nous aide à avoir une idée de la capacité de notre modèle de régression à prédire les valeurs de réponse.
Ce didacticiel explique comment obtenir à la fois les valeurs prédites et les résidus pour un modèle de régression dans Stata.
Exemple : Comment obtenir des valeurs prédites et des résidus
Pour cet exemple, nous utiliserons l’ensemble de données Stata intégré appelé auto . Nous utiliserons le mpg et le déplacement comme variables explicatives et le prix comme variable de réponse.
Utilisez les étapes suivantes pour effectuer une régression linéaire et obtenir ensuite les valeurs prédites et les résidus pour le modèle de régression.
Étape 1 : Chargez et affichez les données.
Tout d’abord, nous allons charger les données à l’aide de la commande suivante :
utilisation automatique du système
Ensuite, nous obtiendrons un résumé rapide des données à l’aide de la commande suivante :
résumer
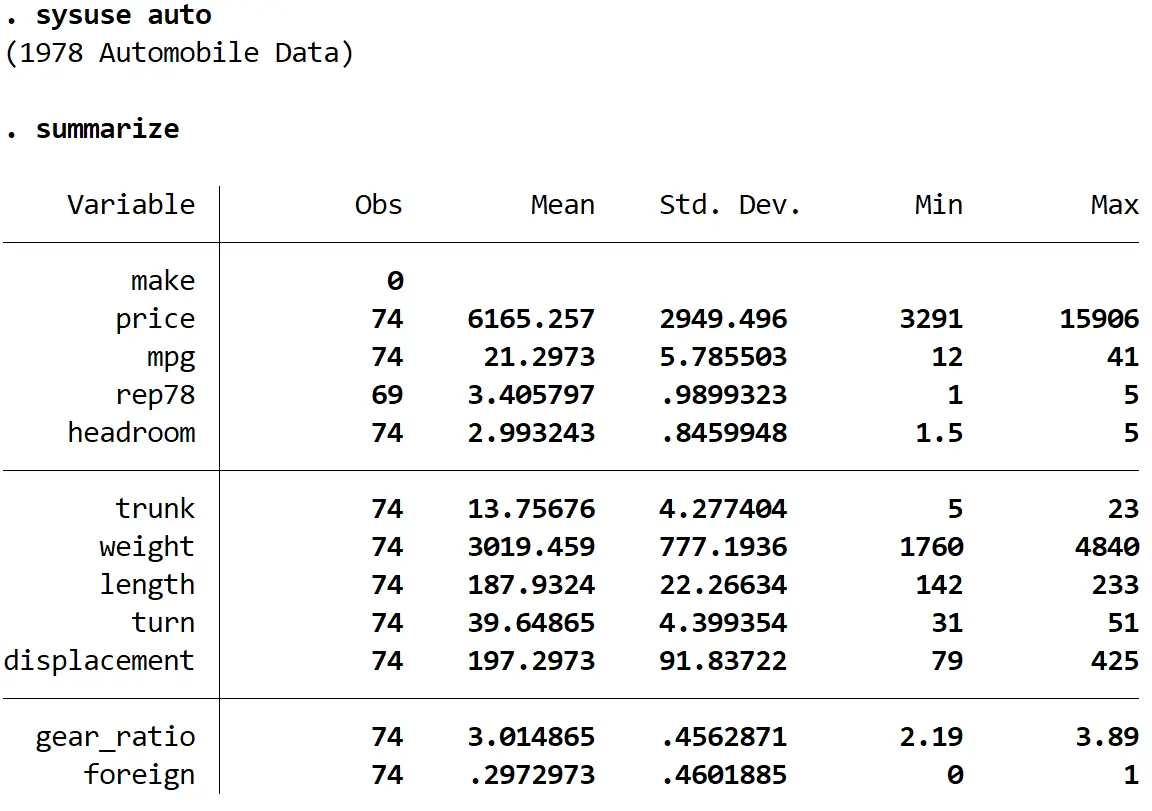
Étape 2 : Ajustez le modèle de régression.
Ensuite, nous utiliserons la commande suivante pour ajuster le modèle de régression :
régression prix mpg déplacement
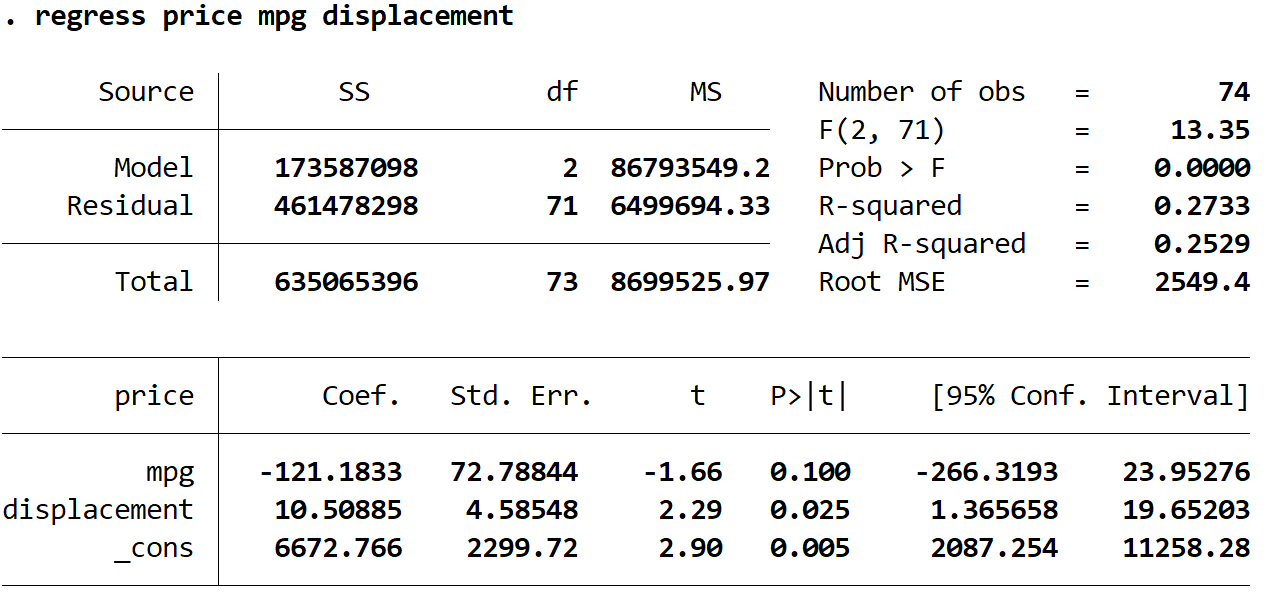
L’équation de régression estimée est la suivante :
prix estimé = 6672,766 -121,1833*(mpg) + 10,50885*(déplacement)
Étape 3 : Obtenez les valeurs prédites.
Nous pouvons obtenir les valeurs prédites en utilisant la commande prédire et en stockant ces valeurs dans une variable nommée comme nous le souhaitons. Dans ce cas, nous utiliserons le nom pred_price :
prédire pred_price
Nous pouvons afficher côte à côte les prix réels et les prix prévus à l’aide de la commande list . Il y a 74 valeurs prédites au total, mais nous n’afficherons que les 10 premières en utilisant la commande in 1/10 :
prix catalogue pred_price en 1/10
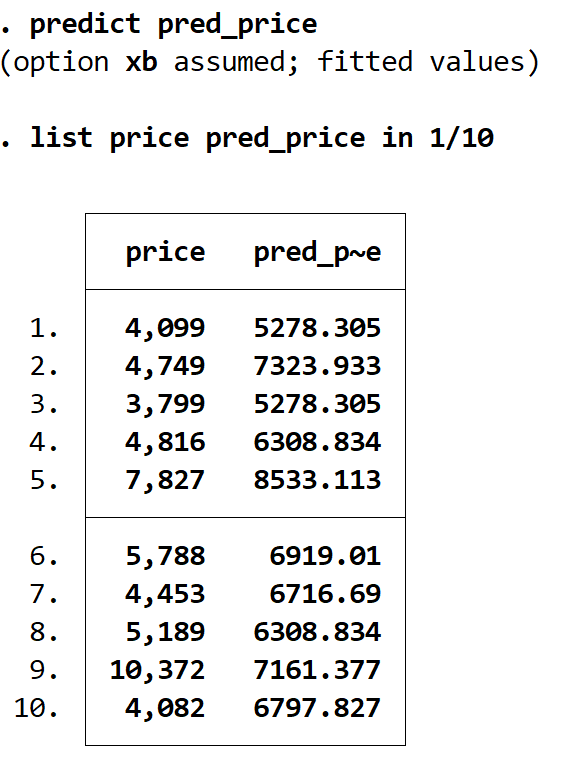
Étape 4 : Obtenez les résidus.
Nous pouvons obtenir les résidus de chaque prédiction en utilisant la commande résidus et en stockant ces valeurs dans une variable nommée comme nous le souhaitons. Dans ce cas, nous utiliserons le nom resid_price :
prédire resid_price, résidus
Nous pouvons afficher le prix réel, le prix prévu et les résidus côte à côte en utilisant à nouveau la commande list :
prix catalogue pred_price resid_price en 1/10
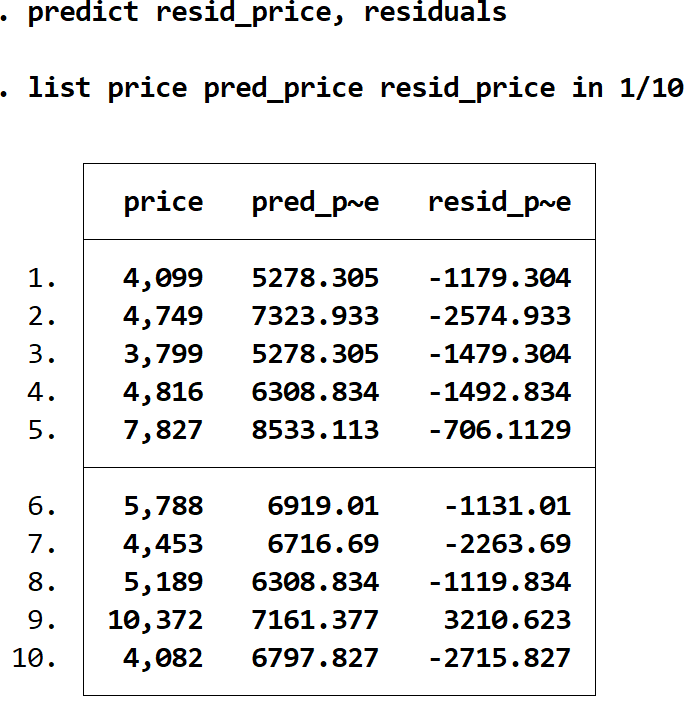
Étape 5 : Créez un tracé des valeurs prédites par rapport aux résidus.
Enfin, nous pouvons créer un nuage de points pour visualiser la relation entre les valeurs prédites et les résidus :
dispersion resid_price pred_price
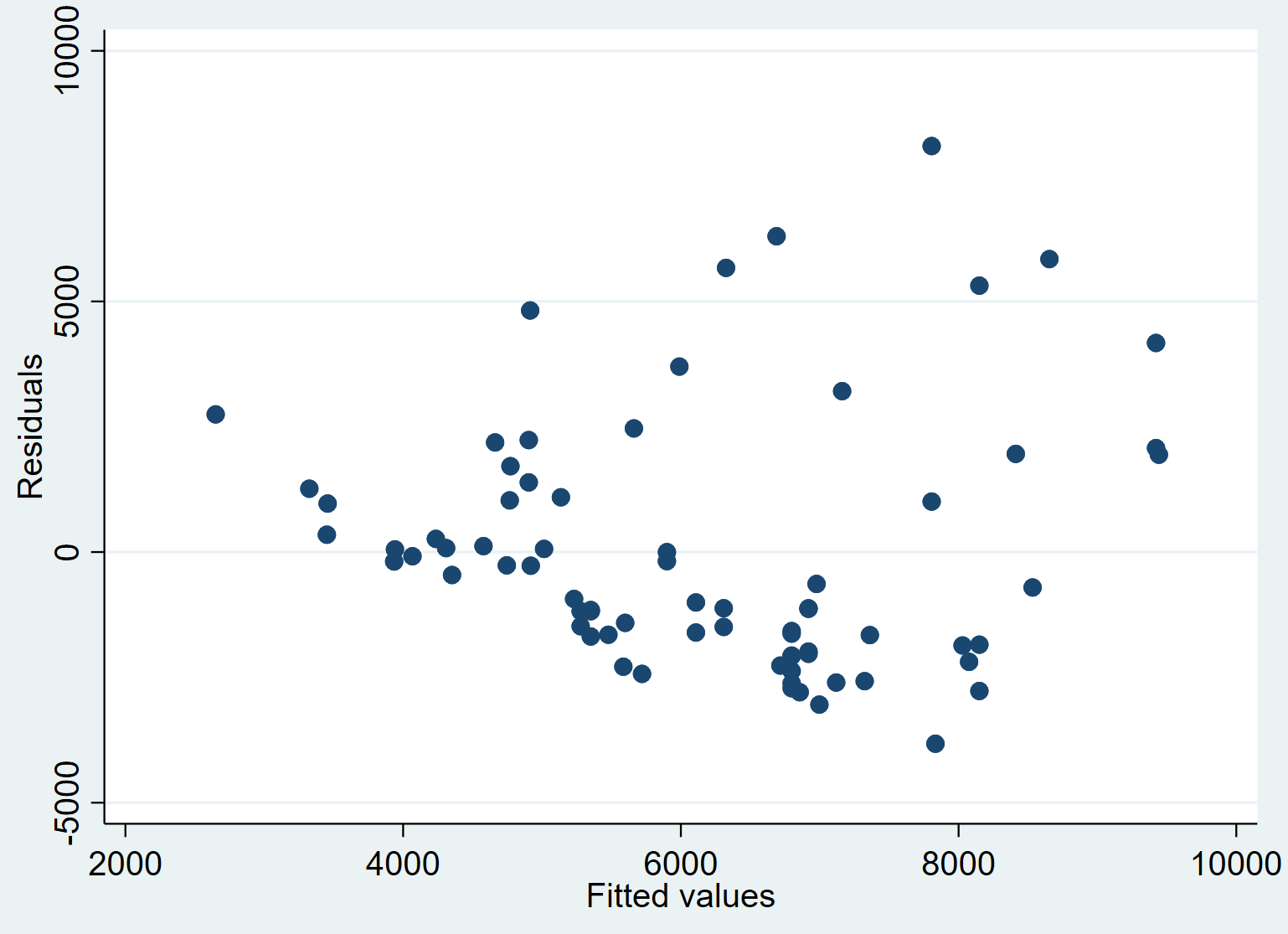
Nous pouvons voir qu’en moyenne, les résidus ont tendance à augmenter à mesure que les valeurs ajustées augmentent. Cela pourrait être un signe d’ hétéroscédasticité – lorsque la répartition des résidus n’est pas constante à chaque niveau de réponse.
Nous pourrions tester formellement l’hétéroscédasticité à l’aide du test de Breusch-Pagan et résoudre ce problème à l’aide d’erreurs types robustes .
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus