
Qu’est-ce qui est considéré comme un « bien » ? Score F1 ?
Lors de l’utilisation de modèles de classification dans l’apprentissage automatique, une métrique courante que nous utilisons pour évaluer la qualité du modèle est le score F1 .
Cette métrique est calculée comme suit :
Score F1 = 2 * (Précision * Rappel) / (Précision + Rappel)
où:
- Précision : Corriger les prédictions positives par rapport au total des prédictions positives
- Rappel : Corriger les prédictions positives par rapport au total des positifs réels
Par exemple, supposons que nous utilisions un modèle de régression logistique pour prédire si 400 joueurs de basket-ball universitaires différents seront recrutés ou non dans la NBA.
La matrice de confusion suivante résume les prédictions faites par le modèle :

Voici comment calculer le score F1 du modèle :
Précision = Vrai Positif / (Vrai Positif + Faux Positif) = 120/ (120+70) = 0,63157
Rappel = Vrai Positif / (Vrai Positif + Faux Négatif) = 120 / (120+40) = 0,75
Score F1 = 2 * (.63157 * .75) / (.63157 + .75) = . 6857
Qu’est-ce qu’un bon score F1 ?
Une question que les étudiants se posent souvent est la suivante :
Qu’est-ce qu’un bon score en F1 ?
En termes simples, des scores F1 plus élevés sont généralement meilleurs.
Rappelons que les scores F1 peuvent aller de 0 à 1, 1 représentant un modèle qui classe parfaitement chaque observation dans la bonne classe et 0 représentant un modèle incapable de classer une observation dans la bonne classe.
Pour illustrer cela, supposons que nous disposions d’un modèle de régression logistique qui produit la matrice de confusion suivante :
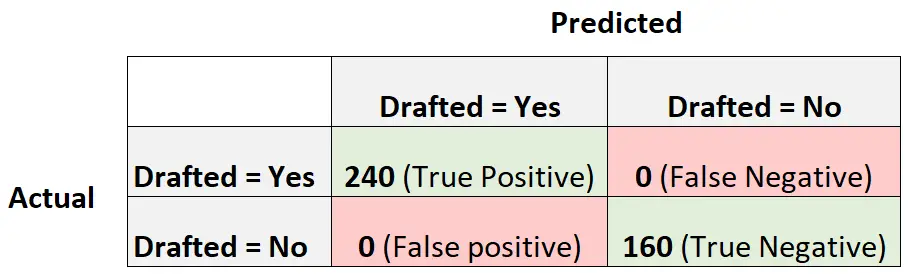
Voici comment calculer le score F1 du modèle :
Précision = Vrai Positif / (Vrai Positif + Faux Positif) = 240/ (240+0) = 1
Rappel = Vrai Positif / (Vrai Positif + Faux Négatif) = 240 / (240+0) = 1
Score F1 = 2 * (1 * 1) / (1 + 1) = 1
Le score F1 est égal à un car il est capable de classer parfaitement chacune des 400 observations dans une classe.
Considérons maintenant un autre modèle de régression logistique qui prédit simplement que chaque joueur sera repêché :
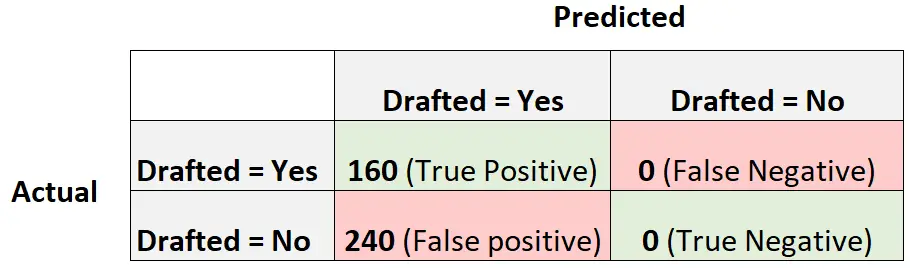
Voici comment calculer le score F1 du modèle :
Précision = Vrai Positif / (Vrai Positif + Faux Positif) = 160/ (160+240) = 0,4
Rappel = Vrai Positif / (Vrai Positif + Faux Négatif) = 160 / (160+0) = 1
Score F1 = 2 * (.4 * 1) / (.4 + 1) = 0,5714
Ceci serait considéré comme un modèle de référence auquel nous pourrions comparer notre modèle de régression logistique car il représente un modèle qui fait la même prédiction pour chaque observation de l’ensemble de données.
Plus notre score F1 est élevé par rapport à un modèle de référence, plus notre modèle est utile.
Rappelons plus tôt que notre modèle avait un score F1 de 0,6857 . Ce n’est pas beaucoup plus élevé que 0,5714 , ce qui indique que notre modèle est plus utile qu’un modèle de référence, mais pas de beaucoup.
Sur la comparaison des scores F1
En pratique, nous utilisons généralement le processus suivant pour sélectionner le « meilleur » modèle pour un problème de classification :
Étape 1 : Ajustez un modèle de référence qui fait la même prédiction pour chaque observation.
Étape 2 : Ajustez plusieurs modèles de classification différents et calculez le score F1 pour chaque modèle.
Étape 3 : Choisissez le modèle avec le score F1 le plus élevé comme « meilleur » modèle, en vérifiant qu’il produit un score F1 plus élevé que le modèle de référence.
Aucune valeur spécifique n’est considérée comme un « bon » score F1, c’est pourquoi nous choisissons généralement le modèle de classification qui produit le score F1 le plus élevé.
Ressources additionnelles
Score F1 vs précision : lequel devriez-vous utiliser ?
Comment calculer le score F1 dans R
Comment calculer le score F1 en Python
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus