
Qu’est-ce que l’hypothèse de normalité en statistique ?
De nombreux tests statistiques reposent sur ce qu’on appelle l’ hypothèse de normalité .
Cette hypothèse stipule que si nous collectons de nombreux échantillons aléatoires indépendants d’une population et calculons une valeur intéressante (comme la moyenne de l’échantillon ), puis créons un histogramme pour visualiser la distribution des moyennes de l’échantillon, nous devrions observer une courbe en cloche parfaite.
De nombreuses techniques statistiques font cette hypothèse à propos des données, notamment :
1. Un échantillon de test t : on suppose que les exemples de données sont normalement distribués.
2. Test t à deux échantillons : on suppose que les deux échantillons sont normalement distribués.
3. ANOVA : On suppose que les résidus du modèle sont normalement distribués.
4. Régression linéaire : On suppose que les résidus du modèle sont normalement distribués.
Si cette hypothèse n’est pas respectée, les résultats de ces tests deviennent peu fiables et nous ne sommes pas en mesure de généraliser avec confiance nos conclusions tirées des échantillons de données à la population globale. C’est pourquoi il est important de vérifier si cette hypothèse est remplie.
Il existe deux manières courantes de vérifier si cette hypothèse de normalité est remplie :
1. Visualisez la normalité
2. Effectuer un test statistique formel
Les sections suivantes expliquent les graphiques spécifiques que vous pouvez créer et les tests statistiques spécifiques que vous pouvez effectuer pour vérifier la normalité.
Visualisez la normalité
Un moyen rapide et informel de vérifier si un ensemble de données est normalement distribué consiste à créer un histogramme ou un tracé QQ.
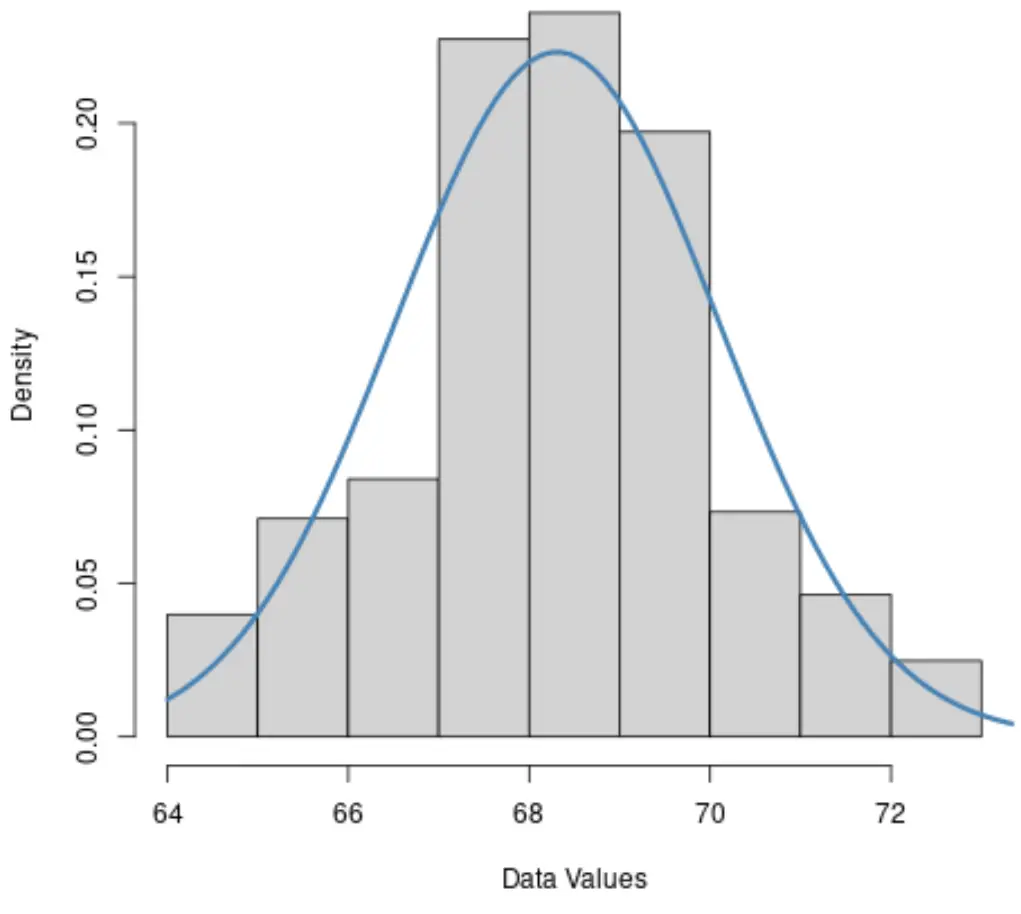
1. Histogramme
Si l’histogramme d’un ensemble de données est à peu près en forme de cloche, il est probable que les données soient distribuées normalement.
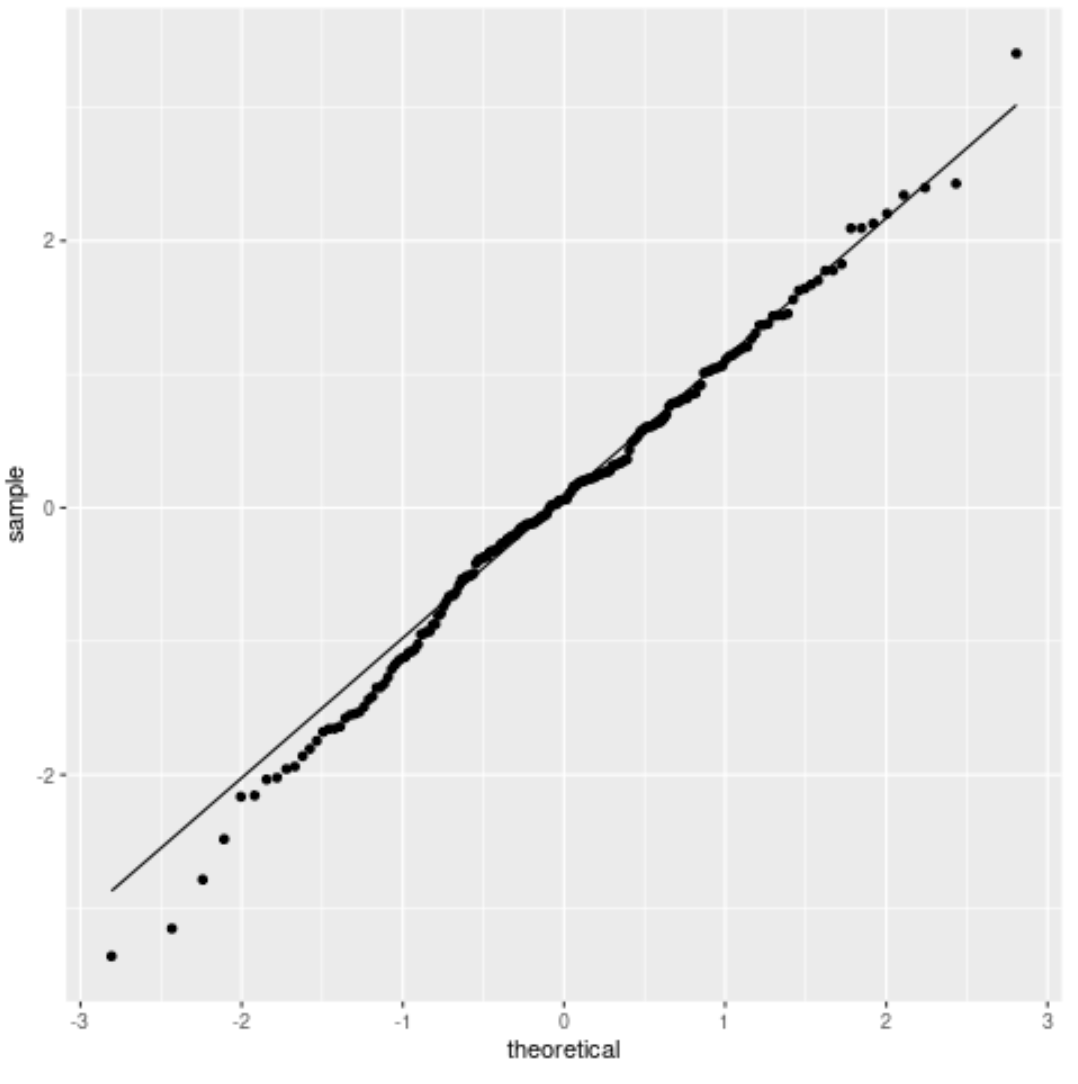
2. Terrain QQ
Un tracé QQ, abréviation de « quantile-quantile », est un type de tracé qui affiche les quantiles théoriques le long de l’axe des x (c’est-à-dire où se trouveraient vos données si elles suivaient une distribution normale) et des quantiles d’échantillons le long de l’axe des y. (c’est-à-dire où se trouvent réellement vos données).
Si les valeurs des données suivent une ligne à peu près droite formant un angle de 45 degrés, alors les données sont supposées être distribuées normalement.
Effectuer un test statistique formel
Vous pouvez également effectuer un test statistique formel pour déterminer si un ensemble de données est normalement distribué.
Si la valeur p du test est inférieure à un certain niveau de signification (comme α = 0,05), vous disposez alors de preuves suffisantes pour affirmer que les données ne sont pas normalement distribuées.
Il existe trois tests statistiques couramment utilisés pour tester la normalité :
1. Le test Jarque-Bera
- Comment effectuer un test Jarque-Bera dans Excel
- Comment effectuer un test Jarque-Bera dans R
- Comment effectuer un test Jarque-Bera en Python
2. Le test de Shapiro-Wilk
3. Le test de Kolmogorov-Smirnov
- Comment effectuer un test de Kolmogorov-Smirnov dans Excel
- Comment effectuer un test de Kolmogorov-Smirnov dans R
- Comment effectuer un test Kolmogorov-Smirnov en Python
Que faire si l’hypothèse de normalité est violée
S’il s’avère que vos données ne sont pas normalement distribuées, vous avez deux options :
1. Transformez les données.
Une option consiste simplement à transformer les données pour les rendre plus normalement distribuées. Les transformations courantes incluent :
- Log Transformation : Transformez les données de y en log(y) .
- Transformation racine carrée : transformer les données de y en √ y
- Transformation de racine cubique : Transformez les données de y en y 1/3
- Transformation Box-Cox : Transformez les données à l’aide d’une procédure Box-Cox
En effectuant ces transformations, la distribution des valeurs de données devient généralement plus normalement distribuée.
2. Effectuer un test non paramétrique
Les tests statistiques qui font l’hypothèse de normalité sont appelés tests paramétriques . Mais il existe également une famille de tests dits non paramétriques qui ne font pas cette hypothèse de normalité.
S’il s’avère que vos données ne sont pas normalement distribuées, vous pouvez simplement effectuer un test non paramétrique. Voici quelques versions non paramétriques de tests statistiques courants :
| Test paramétrique | Équivalent non paramétrique |
|---|---|
| Un échantillon de test t | Un échantillon de test de classement signé Wilcoxon |
| Test t à deux échantillons | Test U de Mann-Whitney |
| Test t pour échantillons appariés | Deux échantillons de test de classement signé Wilcoxon |
| ANOVA unidirectionnelle | Test de Kruskal-Wallis |
Chacun de ces tests non paramétriques permet de réaliser un test statistique sans satisfaire à l’hypothèse de normalité.
Ressources additionnelles
Les quatre hypothèses formulées dans un test T
Les quatre hypothèses de la régression linéaire
Les quatre hypothèses de l’ANOVA
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus