
Comment effectuer une régression linéaire simple en Python (étape par étape)
La régression linéaire simple est une technique que nous pouvons utiliser pour comprendre la relation entre une seule variable explicative et une seule variable de réponse .
Cette technique trouve une ligne qui « correspond » le mieux aux données et prend la forme suivante :
ŷ = b 0 + b 1 x
où:
- ŷ : La valeur de réponse estimée
- b 0 : L’origine de la droite de régression
- b 1 : La pente de la droite de régression
Cette équation peut nous aider à comprendre la relation entre la variable explicative et la variable de réponse et (en supposant qu’elle soit statistiquement significative) elle peut être utilisée pour prédire la valeur d’une variable de réponse étant donné la valeur de la variable explicative.
Ce didacticiel fournit une explication étape par étape sur la façon d’effectuer une régression linéaire simple en Python.
Étape 1 : Charger les données
Pour cet exemple, nous allons créer un faux ensemble de données contenant les deux variables suivantes pour 15 étudiants :
- Nombre total d’heures étudiées pour certains examens
- Résultat de l’examen
Nous tenterons d’adapter un modèle de régression linéaire simple en utilisant les heures comme variable explicative et les résultats de l’examen comme variable de réponse.
Le code suivant montre comment créer ce faux ensemble de données en Python :
import pandas as pd #create dataset df = pd.DataFrame({'hours': [1, 2, 4, 5, 5, 6, 6, 7, 8, 10, 11, 11, 12, 12, 14], 'score': [64, 66, 76, 73, 74, 81, 83, 82, 80, 88, 84, 82, 91, 93, 89]}) #view first six rows of dataset df[0:6] hours score 0 1 64 1 2 66 2 4 76 3 5 73 4 5 74 5 6 81
Étape 2 : Visualisez les données
Avant d’ajuster un modèle de régression linéaire simple, nous devons d’abord visualiser les données pour les comprendre.
Premièrement, nous voulons nous assurer que la relation entre les heures et le score est à peu près linéaire, puisqu’il s’agit d’une hypothèse sous-jacente de régression linéaire simple.
Nous pouvons créer un nuage de points simple pour visualiser la relation entre les deux variables :
import matplotlib.pyplot as plt plt.scatter(df.hours, df.score) plt.title('Hours studied vs. Exam Score') plt.xlabel('Hours') plt.ylabel('Score') plt.show()
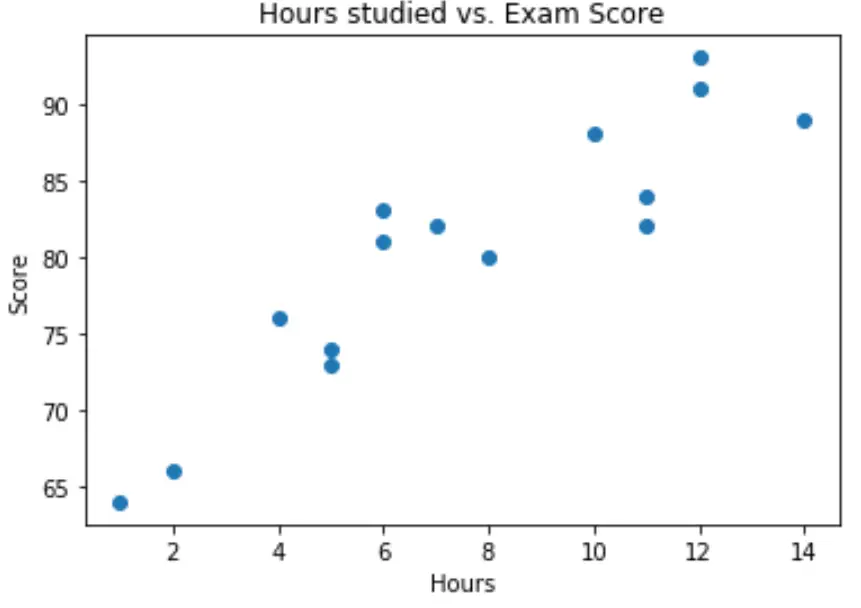
D’après le graphique, nous pouvons voir que la relation semble être linéaire. À mesure que le nombre d’heures augmente, le score a également tendance à augmenter de manière linéaire.
Ensuite, nous pouvons créer un boxplot pour visualiser la distribution des résultats des examens et vérifier les valeurs aberrantes . Par défaut, Python définit une observation comme étant aberrante si elle est 1,5 fois l’intervalle interquartile supérieur au troisième quartile (Q3) ou 1,5 fois l’intervalle interquartile inférieur au premier quartile (Q1).
Si une observation est aberrante, un petit cercle apparaîtra dans le boxplot :
df.boxplot(column=['score'])
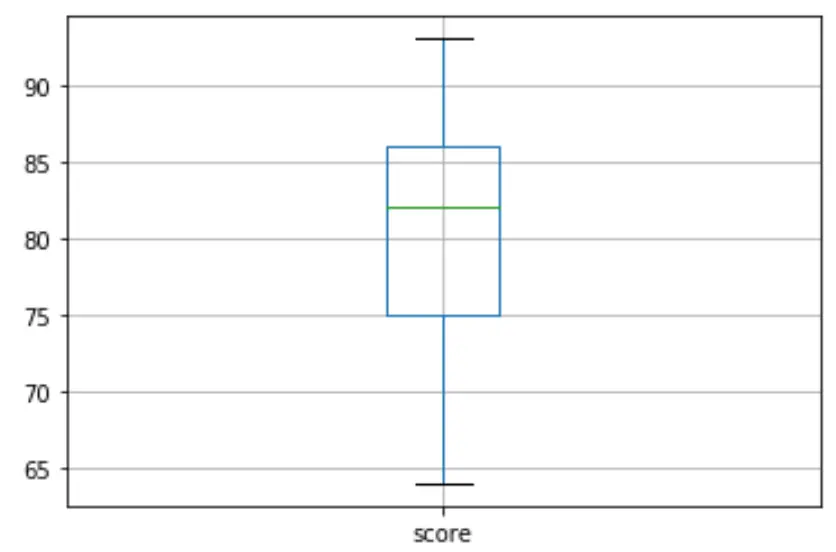
Il n’y a pas de petits cercles dans le boxplot, ce qui signifie qu’il n’y a pas de valeurs aberrantes dans notre ensemble de données.
Étape 3 : Effectuer une régression linéaire simple
Une fois que nous avons confirmé que la relation entre nos variables est linéaire et qu’il n’y a pas de valeurs aberrantes, nous pouvons procéder à l’ajustement d’un modèle de régression linéaire simple en utilisant les heures comme variable explicative et le score comme variable de réponse :
Remarque : nous utiliserons la fonction OLS() de la bibliothèque statsmodels pour ajuster le modèle de régression.
import statsmodels.api as sm #define response variable y = df['score'] #define explanatory variable x = df[['hours']] #add constant to predictor variables x = sm.add_constant(x) #fit linear regression model model = sm.OLS(y, x).fit() #view model summary print(model.summary()) OLS Regression Results ============================================================================== Dep. Variable: score R-squared: 0.831 Model: OLS Adj. R-squared: 0.818 Method: Least Squares F-statistic: 63.91 Date: Mon, 26 Oct 2020 Prob (F-statistic): 2.25e-06 Time: 15:51:45 Log-Likelihood: -39.594 No. Observations: 15 AIC: 83.19 Df Residuals: 13 BIC: 84.60 Df Model: 1 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ const 65.3340 2.106 31.023 0.000 60.784 69.884 hours 1.9824 0.248 7.995 0.000 1.447 2.518 ============================================================================== Omnibus: 4.351 Durbin-Watson: 1.677 Prob(Omnibus): 0.114 Jarque-Bera (JB): 1.329 Skew: 0.092 Prob(JB): 0.515 Kurtosis: 1.554 Cond. No. 19.2 ==============================================================================
À partir du résumé du modèle, nous pouvons voir que l’équation de régression ajustée est :
Score = 65,334 + 1,9824*(heures)
Cela signifie que chaque heure supplémentaire étudiée est associée à une augmentation moyenne de la note à l’examen de 1,9824 points. Et la valeur d’origine de 65,334 nous indique la note moyenne attendue à l’examen pour un étudiant qui étudie zéro heure.
Nous pouvons également utiliser cette équation pour trouver la note attendue à l’examen en fonction du nombre d’heures qu’un étudiant étudie. Par exemple, un étudiant qui étudie pendant 10 heures devrait obtenir une note à l’examen de 85,158 :
Note = 65,334 + 1,9824*(10) = 85,158
Voici comment interpréter le reste du résumé du modèle :
- P>|t| : Il s’agit de la valeur p associée aux coefficients du modèle. Étant donné que la valeur p pour les heures (0,000) est nettement inférieure à 0,05, nous pouvons dire qu’il existe une association statistiquement significative entre les heures et le score .
- R au carré : ce nombre nous indique que le pourcentage de variation des résultats des examens peut s’expliquer par le nombre d’heures étudiées. En général, plus la valeur R au carré d’un modèle de régression est grande, plus les variables explicatives sont capables de prédire la valeur de la variable de réponse. Dans ce cas, 83,1 % de la variation des scores s’explique par les heures étudiées.
- Statistique F et valeur p : La statistique F ( 63,91 ) et la valeur p correspondante ( 2,25e-06 ) nous indiquent la signification globale du modèle de régression, c’est-à-dire si les variables explicatives du modèle sont utiles pour expliquer la variation. dans la variable de réponse. Étant donné que la valeur p dans cet exemple est inférieure à 0,05, notre modèle est statistiquement significatif et les heures sont considérées comme utiles pour expliquer la variation du score .
Étape 4 : Créer des tracés résiduels
Après avoir adapté le modèle de régression linéaire simple aux données, la dernière étape consiste à créer des tracés résiduels.
L’une des hypothèses clés de la régression linéaire est que les résidus d’un modèle de régression sont à peu près normalement distribués et sont homoscédastiques à chaque niveau de la variable explicative. Si ces hypothèses ne sont pas respectées, les résultats de notre modèle de régression pourraient être trompeurs ou peu fiables.
Pour vérifier que ces hypothèses sont remplies, nous pouvons créer les tracés résiduels suivants :
Graphique des valeurs résiduelles par rapport aux valeurs ajustées : ce graphique est utile pour confirmer l’homoscédasticité. L’axe des x affiche les valeurs ajustées et l’axe des y affiche les résidus. Tant que les résidus semblent être répartis de manière aléatoire et uniforme dans tout le graphique autour de la valeur zéro, nous pouvons supposer que l’homoscédasticité n’est pas violée :
#define figure size fig = plt.figure(figsize=(12,8)) #produce residual plots fig = sm.graphics.plot_regress_exog(model, 'hours', fig=fig)
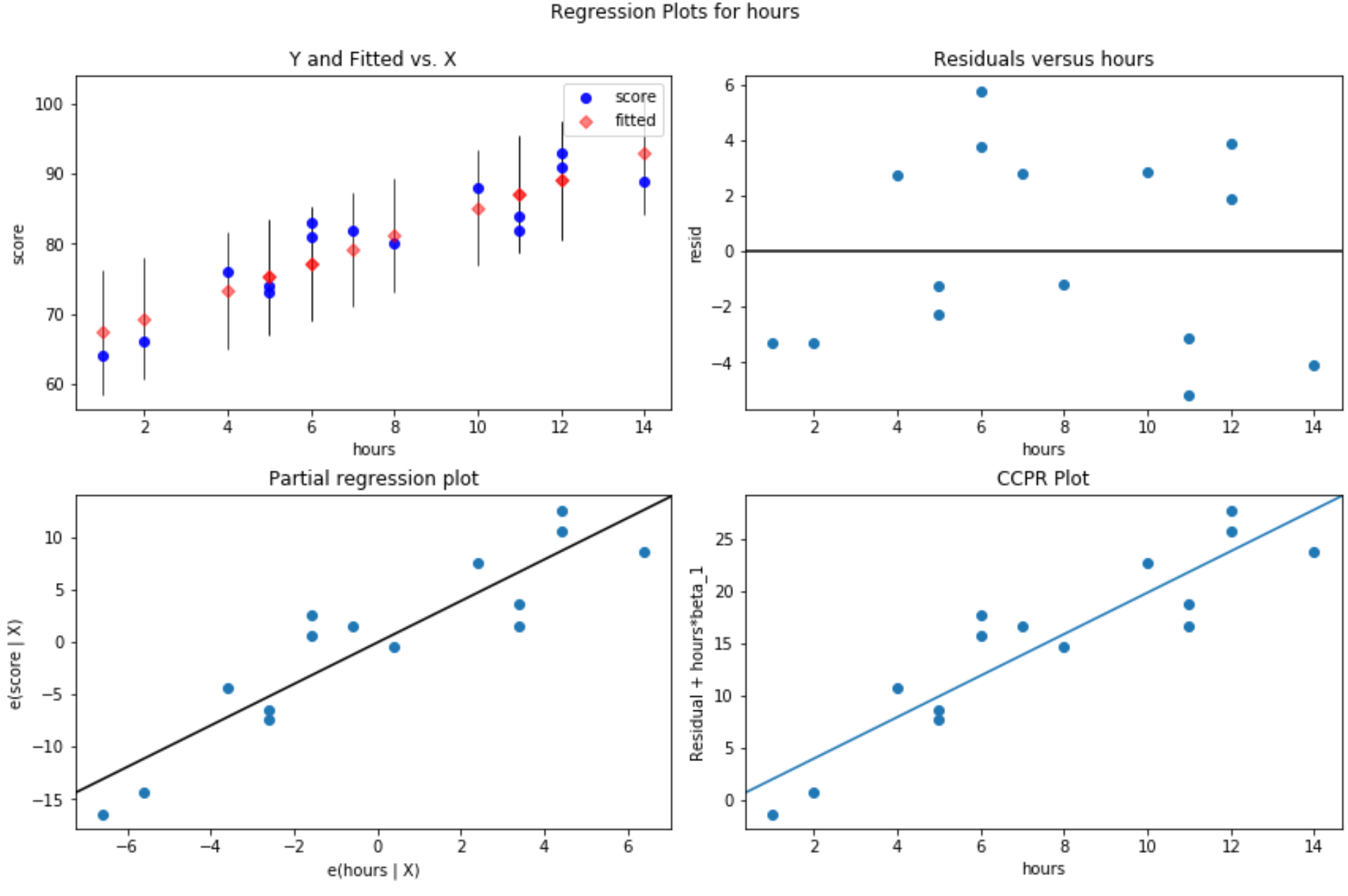
Quatre parcelles sont produites. Celui dans le coin supérieur droit est le tracé résiduel par rapport au tracé ajusté. L’axe des X sur ce tracé montre les valeurs réelles des points de variable prédictive et l’axe des Y montre le résidu pour cette valeur.
Puisque les résidus semblent être dispersés de manière aléatoire autour de zéro, cela indique que l’hétéroscédasticité ne pose pas de problème avec la variable explicative.
Tracé QQ : ce tracé est utile pour déterminer si les résidus suivent une distribution normale. Si les valeurs des données dans le tracé suivent une ligne à peu près droite à un angle de 45 degrés, alors les données sont normalement distribuées :
#define residuals res = model.resid #create Q-Q plot fig = sm.qqplot(res, fit=True, line="45") plt.show()
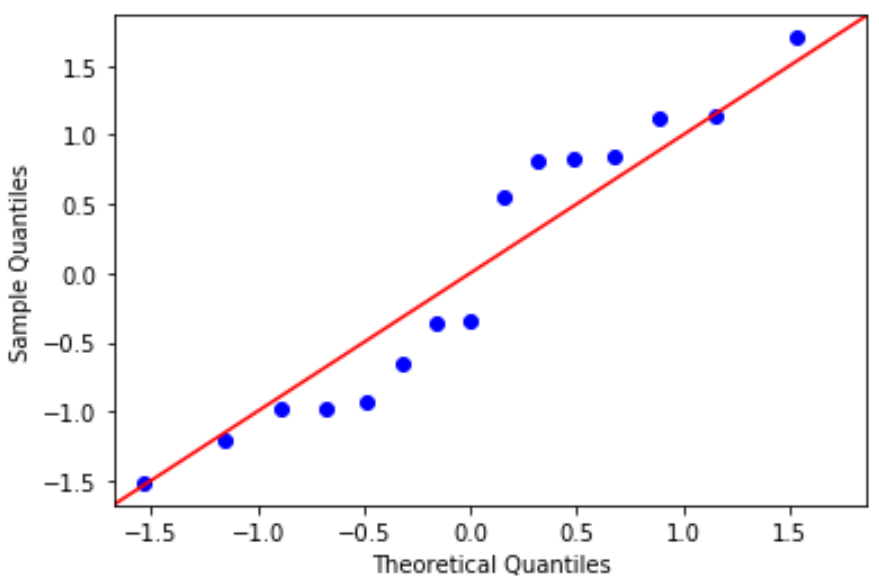
Les résidus s’écartent un peu de la ligne des 45 degrés, mais pas suffisamment pour susciter de sérieuses inquiétudes. Nous pouvons supposer que l’hypothèse de normalité est remplie.
Puisque les résidus sont normalement distribués et homoscédastiques, nous avons vérifié que les hypothèses du modèle de régression linéaire simple sont remplies. Ainsi, la sortie de notre modèle est fiable.
Le code Python complet utilisé dans ce didacticiel peut être trouvé ici .
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus