
Comment effectuer un test Shapiro-Wilk dans R (avec exemples)
Le test de Shapiro-Wilk est un test de normalité. Il est utilisé pour déterminer si un échantillon provient ou non d’unedistribution normale .
Ce type de test est utile pour déterminer si un ensemble de données donné provient ou non d’une distribution normale, ce qui est une hypothèse couramment utilisée dans de nombreux tests statistiques, notamment la régression , l’ANOVA , les tests t et bien d’autres.
Nous pouvons facilement effectuer un test Shapiro-Wilk sur un ensemble de données donné en utilisant la fonction intégrée suivante dans R :
shapiro.test(x)
où:
- x : un vecteur numérique de valeurs de données.
Cette fonction produit une statistique de test W ainsi qu’une valeur p correspondante. Si la valeur p est inférieure à α = 0,05, il existe suffisamment de preuves pour affirmer que l’échantillon ne provient pas d’une population normalement distribuée.
Remarque : La taille de l’échantillon doit être comprise entre 3 et 5 000 pour pouvoir utiliser la fonction shapiro.test().
Ce tutoriel montre plusieurs exemples d’utilisation pratique de cette fonction.
Exemple 1 : Test de Shapiro-Wilk sur des données normales
Le code suivant montre comment effectuer un test Shapiro-Wilk sur un ensemble de données avec une taille d’échantillon n=100 :
#make this example reproducible set.seed(0) #create dataset of 100 random values generated from a normal distribution data <- rnorm(100) #perform Shapiro-Wilk test for normality shapiro.test(data) Shapiro-Wilk normality test data: data W = 0.98957, p-value = 0.6303
La valeur p du test s’avère être de 0,6303 . Puisque cette valeur n’est pas inférieure à 0,05, nous pouvons supposer que les données de l’échantillon proviennent d’une population normalement distribuée.
Ce résultat ne devrait pas être surprenant puisque nous avons généré les exemples de données à l’aide de la fonction rnorm(), qui génère des valeurs aléatoires à partir d’une distribution normale avec moyenne = 0 et écart type = 1.
Connexe : Un guide sur dnorm, pnorm, qnorm et rnorm dans R
Nous pouvons également produire un histogramme pour vérifier visuellement que les données de l’échantillon sont normalement distribuées :
hist(data, col='steelblue')
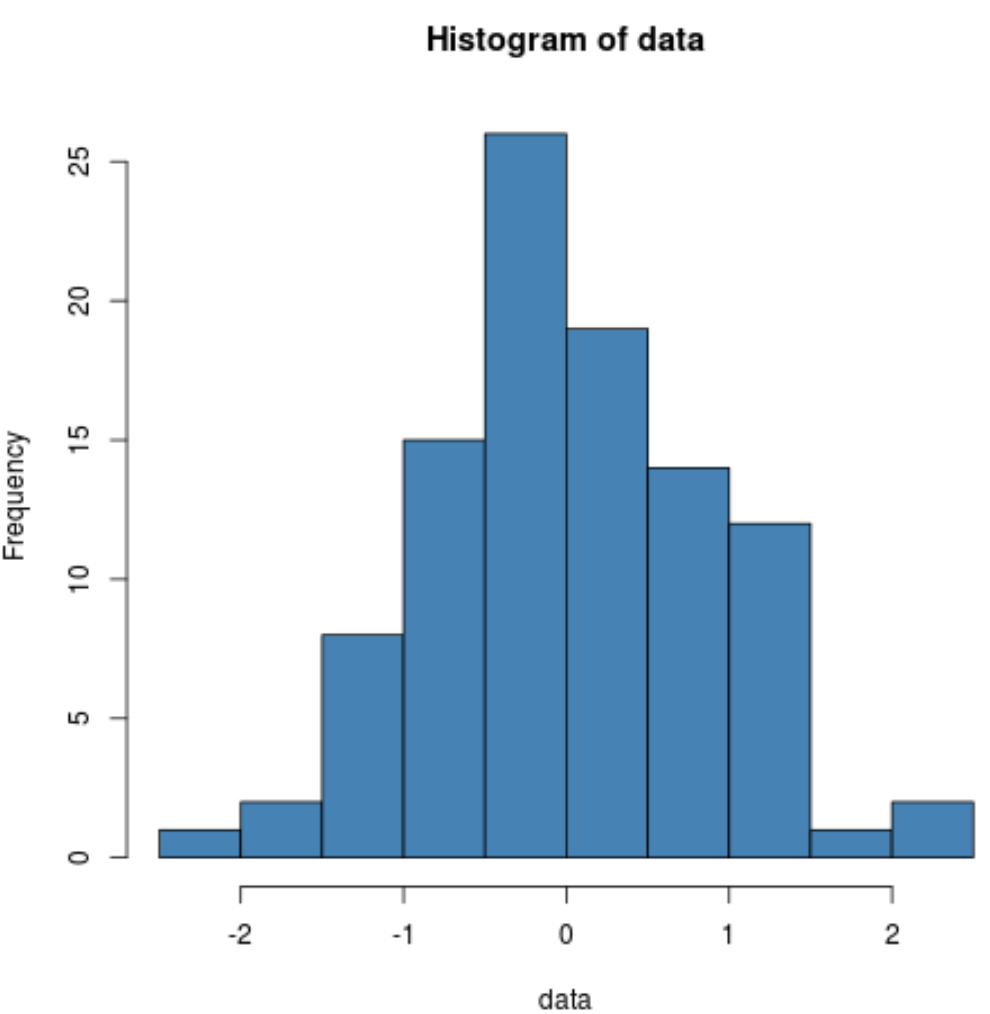
Nous pouvons voir que la distribution est assez en forme de cloche avec un pic au centre de la distribution, ce qui est typique des données normalement distribuées.
Exemple 2 : Test de Shapiro-Wilk sur des données non normales
Le code suivant montre comment effectuer un test de Shapiro-Wilk sur un ensemble de données avec une taille d’échantillon n=100 dans lequel les valeurs sont générées aléatoirement à partir d’une distribution de Poisson :
#make this example reproducible set.seed(0) #create dataset of 100 random values generated from a Poisson distribution data <- rpois(n=100, lambda=3) #perform Shapiro-Wilk test for normality shapiro.test(data) Shapiro-Wilk normality test data: data W = 0.94397, p-value = 0.0003393
La valeur p du test s’avère être 0,0003393 . Puisque cette valeur est inférieure à 0,05, nous disposons de suffisamment de preuves pour affirmer que les données de l’échantillon ne proviennent pas d’une population normalement distribuée.
Ce résultat ne devrait pas être surprenant puisque nous avons généré les exemples de données à l’aide de la fonction rpois(), qui génère des valeurs aléatoires à partir d’une distribution de Poisson.
Connexe : Un guide des dpois, ppois, qpois et rpois dans R
Nous pouvons également produire un histogramme pour voir visuellement que les données de l’échantillon ne sont pas normalement distribuées :
hist(data, col='coral2')
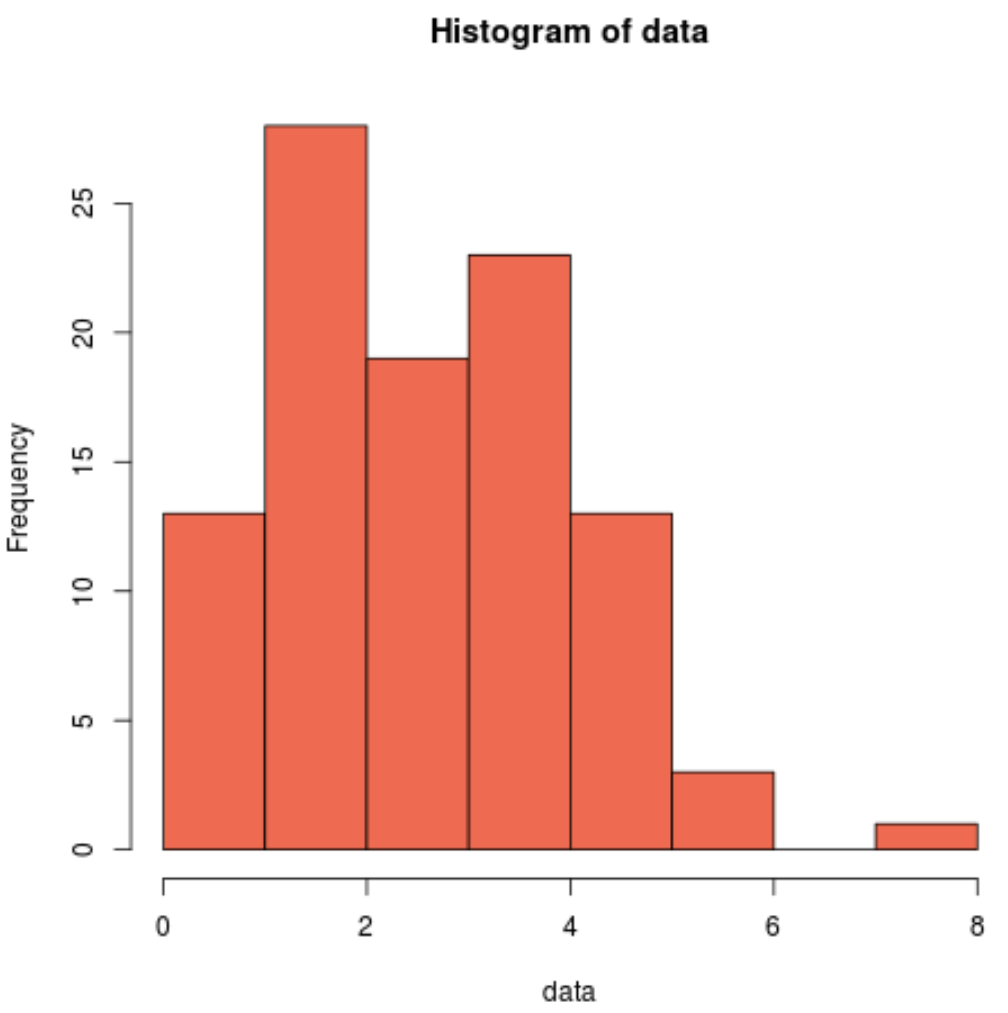
Nous pouvons voir que la distribution est asymétrique à droite et n’a pas la « forme de cloche » typique associée à une distribution normale. Ainsi, notre histogramme correspond aux résultats du test de Shapiro-Wilk et confirme que nos données d’échantillon ne proviennent pas d’une distribution normale.
Que faire avec des données non normales
Si un ensemble de données donné n’est pas normalement distribué, nous pouvons souvent effectuer l’une des transformations suivantes pour le rendre plus normal :
1. Transformation du journal : transformez la variable de réponse de y en log(y) .
2. Transformation racine carrée : Transformez la variable de réponse de y en √y .
3. Transformation de racine cubique : transformez la variable de réponse de y en y 1/3 .
En effectuant ces transformations, la variable de réponse se rapproche généralement de la distribution normale.
Consultez ce tutoriel pour voir comment effectuer ces transformations en pratique.
Ressources additionnelles
Comment effectuer un test d’Anderson-Darling dans R
Comment effectuer un test de Kolmogorov-Smirnov dans R
Comment effectuer un test Shapiro-Wilk en Python
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus