
Comment effectuer une MANOVA dans Stata
Une ANOVA unidirectionnelle est utilisée pour déterminer si différents niveaux d’une variable explicative conduisent ou non à des résultats statistiquement différents dans certaines variables de réponse.
Par exemple, nous pourrions être intéressés à comprendre si trois niveaux d’études (diplôme d’associé, baccalauréat, maîtrise) conduisent ou non à des revenus annuels statistiquement différents. Dans ce cas, nous avons une variable explicative et une variable de réponse.
- Variable explicative : niveau d’éducation
- Variable de réponse : revenu annuel
Une MANOVA est une extension de l’ANOVA unidirectionnelle dans laquelle il y a plus d’une variable de réponse. Par exemple, nous pourrions être intéressés à comprendre si le niveau d’éducation conduit ou non à des revenus annuels différents et à des montants différents d’endettement étudiant. Dans ce cas, nous avons une variable explicative et deux variables de réponse :
- Variable explicative : niveau d’éducation
- Variables de réponse : revenu annuel, dette étudiante
Comme nous avons plus d’une variable de réponse, il serait approprié d’utiliser une MANOVA dans ce cas.
Ensuite, nous expliquerons comment effectuer une MANOVA dans Stata.
Exemple : MANOVA dans Stata
Pour illustrer comment effectuer une MANOVA dans Stata, nous utiliserons l’ensemble de données suivant qui contient les trois variables suivantes pour 24 personnes :
- educ : niveau d’études (0 = Associate, 1 = Bachelor, 2 = Master)
- revenu : revenu annuel
- dette : dette totale liée au prêt étudiant
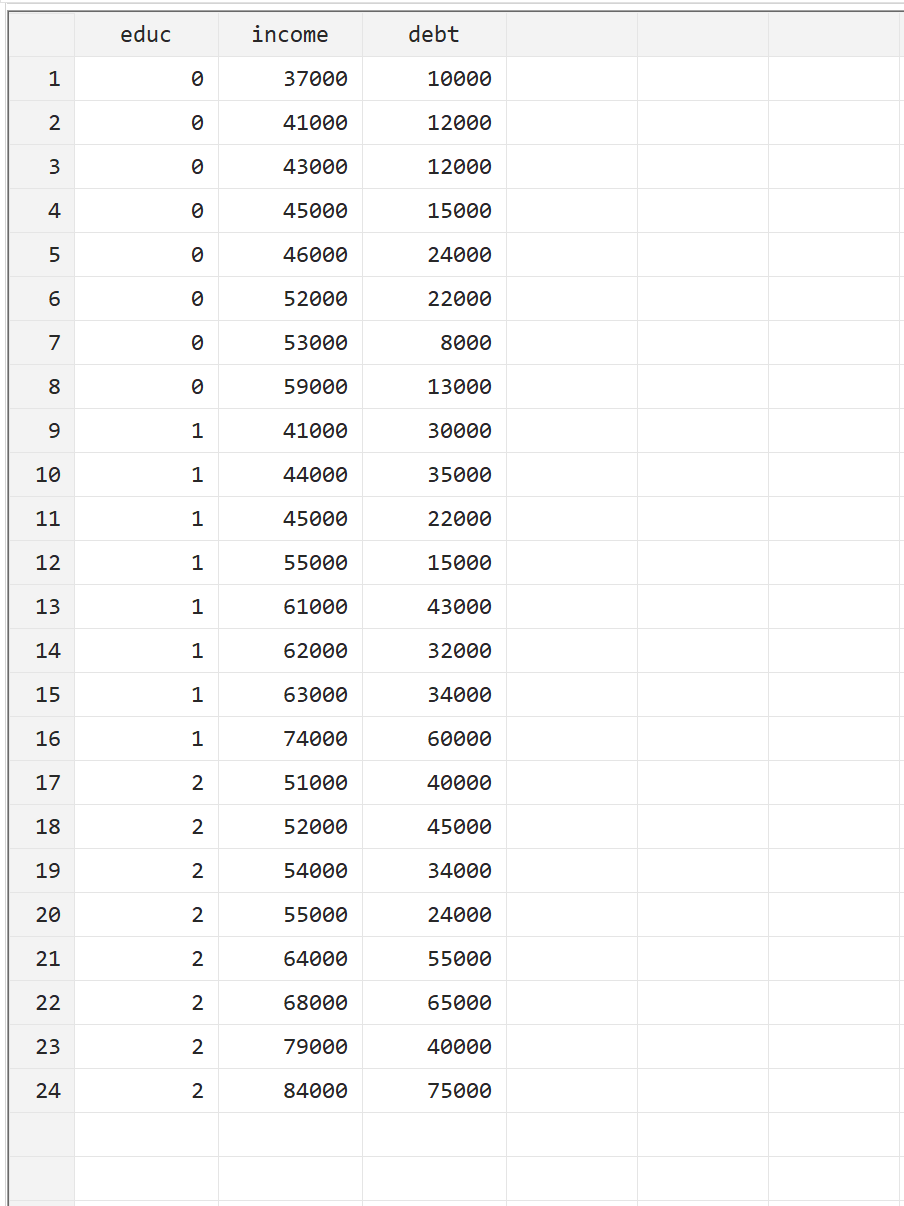
Vous pouvez reproduire cet exemple en saisissant manuellement les données vous-même en accédant à Données > Editeur de données > Editeur de données (Modifier) dans la barre de menu supérieure.
Pour effectuer la MANOVA en utilisant l’éducation comme variable explicative et le revenu et la dette comme variables de réponse, nous pouvons utiliser la commande suivante :
dette de revenu manova = educ

Stata produit quatre statistiques de test uniques ainsi que leurs valeurs p correspondantes :
Lambda de Wilks : statistique F = 5,02, valeur P = 0,0023.
Trace de Pillai : statistique F = 4,07, valeur P = 0,0071.
Trace Lawley-Hotelling : statistique F = 5,94, valeur P = 0,0008.
La plus grande racine de Roy : F-Statistic = 13,10, P-value = 0,0002.
Pour une explication détaillée de la façon dont chaque statistique de test est calculée, reportez-vous à cet article du Penn State Eberly College of Science.
La valeur p pour chaque statistique de test est inférieure à 0,05, donc l’hypothèse nulle sera rejetée quelle que soit celle que vous utilisez. Cela signifie que nous disposons de suffisamment de preuves pour affirmer que le niveau d’éducation entraîne des différences statistiquement significatives dans le revenu annuel et la dette étudiante totale.
Remarque sur les valeurs p : la lettre à côté de la valeur p dans le tableau de sortie indique comment la statistique F a été calculée (e = calcul exact, a = calcul approximatif, u = limite supérieure).
à propos de l'auteur
Dr. Benjamin Anderson
Il est un professeur de statistiques à la retraite devenu éducateur dévoué sur Statorials. Avec une vaste expérience et une expertise dans le domaine des statistiques, je m'engage à partager mes connaissances pour responsabiliser les étudiants grâce à Statorials. Lire plus